Refurbished SSD telemetry determines whether a used enterprise drive is suitable for production. The Refurbished SSD Framework webinar aired on May 7, and six weeks of follow-up calls have surfaced one question more than any other. Buyers accept the 40 to 60 percent discount against new pricing. The objection that survives is narrower and sharper. How does a team know the supplier’s stated wear number is honest? The answer never rests on trust. It rests on measurement.
Most refurbished data center hardware suppliers are reputable. They serialize inventory, document the chain of custody, and stand behind their wear representations. The risk sits with the exception, not the rule, and the platform’s job is to catch that exception before it matters.
A supplier can reset SMART counters and present a drive as having 20 percent wear when the actual figure is near 90. The buyer who accepts that number on faith inherits the risk. The buyer who measures the drive with platform-level telemetry manages it. That single distinction separates a procurement decision from a gamble.
The control that does the work is not a single reading at intake. It is a continuous measurement against the platform’s thresholds throughout the drive’s entire production life. A label can be reset. A trajectory under real writes cannot. That trajectory is what VergeOS watches.
Key Takeaways
- Refurbished SSD telemetry does not depend on catching a reset counter at the door. Continuous monitoring plus redundancy keeps a mislabeled drive from costing you data.
- VergeOS raises a drive warning when wear level or reallocated sectors cross a threshold, then a proactive replacement procedure swaps the drive with the cluster online and redundant.
- A reset counter hides a drive’s starting point, not its trajectory. Real production writes push a worn drive across the thresholds far sooner than its label predicts.
A Reset Counter Hides the Starting Point, Not the Trajectory
The wear-leveling indicator falls in a straight line as data is written. The slope per terabyte stays about the same across the drive’s life. A counter reset to 20 percent counts down from that false floor at the normal rate, and a single day of synthetic writes barely moves it. The label, on its own, resists a quick catch at intake.
The trajectory tells the truth the label hides. Worn NAND retires cells under real writes. Reallocated sectors grow, and read and write errors climb. Wear crosses its threshold sooner than a true 20 percent drive ever would. VergeOS reads those signals per drive and raises a status the moment a limit is passed.
The documented warning statuses are exact:
- Wear level exceeded its maximum threshold.
- Reallocated sectors exceeded their maximum threshold.
- Read or write error threshold reached.
Each one bubbles up to the System Dashboard as a Warning or an Error. The drive that lied about its starting point announces its real condition the first time production pressure finds it.
Key Terms
The Seven Refurbished SSD Telemetry Attributes to Watch
Enterprise SSDs publish around twenty SMART attributes. Seven of them account for the bulk of the predictive value, and reading them together matters more than reading any one alone.
- Total writes track progress toward the rated TBW.
- Reallocated sectors indicate physical media degradation, as failed cells are added to a remap list.
- Wear leveling count reports how much fresh NAND the drive has left to redirect writes onto.
- The ECC error rate indicates that the drive silently corrects more errors per read, a leading indicator that the firmware tries to hide.
- End-to-end error rate flags controller-level corruption that should sit at zero.
- Power-on hours and temperature round out the picture: the first as context, the second as an accelerant for every other failure mode.

VergeOS turns three of these into operational triggers. Wear level, reallocated sectors, and read or write errors each have a maximum threshold, and crossing one of them moves the drive into a Warning or Error state.
The metric that tells the truth about a used drive is wear leveling, not power-on hours. A drive rotated out of a hyperscaler on a three-year calendar can show high power-on hours and low wear. A drive run hard in a write-heavy role shows the reverse. A team that reads wear leveling against the supplier’s claim reads the drive correctly.
Using Refurbished SSD Telemetry to Lower the Odds
Intake testing is the first filter, not the whole answer.
- Install the refurbished drives behind VergeOS.
- Run a stress workload. Watch for reallocated sectors and read or write errors that a healthy drive of the stated wear would not produce.
- Cross-check the reported wear against host writes and power-on hours. A drive that contradicts itself, or that sheds sectors under load, goes back before it ever holds production data.
The limit deserves a plain statement. A clean counter reset can pass a short bench test, and the wear percentage moves too little in a day to expose a falsified baseline on its own. Intake testing reduces the likelihood of introducing a bad drive into production. Catching the rest is the job of continuous monitoring.
The protocol still earns its place. It turns the supplier’s wear number into a claim that the platform inspects rather than accepts, and it returns the obviously bad units on the first batch. The passing drives enter an environment that keeps watching them.
Continuous Monitoring Is Where the Protection Lives
The drive that slips through the intake meets the part that matters. Refurbished SSD telemetry does its real work in production, where VergeOS watches every drive and alerts on the conditions that precede failure. An On-Demand subscription emails the moment a drive crosses its wear-level or reallocated-sector threshold or changes status. A scheduled subscription delivers the drive and tier dashboards at a daily or weekly interval, so a team can track trends between alerts. VergeOS recommends running both against the System Dashboard for timely awareness of drive issues.

A mislabeled drive reveals itself here. Its real wear crosses the threshold weeks ahead of the schedule its fake label implied. The Warning status fires on the dashboard. The team replaces the drive before it fails, using the proactive replacement procedure, with the node in maintenance mode and the rest of the cluster online and redundant. The mislabel costs a drive swap, not a data loss.
This is the answer to the original objection. A team does not need to prove the wear number honest at the door. It needs to detect a drive drifting toward failure and act before the failure occurs. Continuous monitoring paired with proactive replacement does exactly that.
Refurbished SSD Telemetry Needs a Platform Behind It

Monitoring buys you a warning, and the architecture prevents data loss. The two work as a pair, and refurbished SSD telemetry earns its value only on a platform built to act on what it finds. VergeOS pairs monitoring with synchronous replication at RF2 or RF3, so the loss of one or two drives results in no rebuild storm and no service interruption.
The failures that a team does not predict are still handled without interrupting the application. Same-batch refurbished drives age together, and a cohort can move toward the edge in parallel. When a loss exceeds replication tolerance, ioGuardian streams missing blocks to running VMs as they request them, and live migration moves workloads off the degraded nodes. Recovery becomes the data path during the failure, not a restore job after it.
Provenance stops deciding the final outcome. A worn drive and a fresh drive present the platform with the same event, a drive crossing a threshold or dropping out, and the response does not change with the drive’s history. The case has been made that storage recovery architectures matter more than drive reliability, and that principle is what lets refurbished media stand on equal footing with new.
Label-Based Trust vs VergeOS Monitored Operation
| Label-Based Trust | VergeOS Monitored Operation | |
|---|---|---|
| Supplier wear claim | Accepted as stated on the invoice | Treated as a claim the platform inspects under load and across production life |
| Worn drive in production | Discovered when it fails | Crosses a wear or reallocated-sector threshold and raises a Warning first |
| Response to the signal | Reactive replacement after an outage | Proactive replacement with the cluster online and redundant |
| Failure beyond tolerance | Backup restore and downtime | ioGuardian inline streaming, no service interruption |
Refurbished SSD Telemetry is a Math Problem.
The webinar closed on a single line. Refurbished enterprise flash is a procurement decision, not a courage test. Six weeks of conversations have moved the proof from the loading dock to the running cluster. The discount lives on the invoice. That discount runs deep enough to pay for a VMware exit with refurbished hardware. The protection lives in refurbished SSD telemetry that watches every drive and an architecture that absorbs the failures it sees coming.
The fear that kept refurbished drives out of the data center was the fear of a number no one could check. VergeOS does not ask a team to check that number once. It checks the drive every day it runs.
Two steps put the framework to work. Watch The Refurbished SSD Framework on demand to see the architecture in full. Then run the Refresh Cost Diagnostic against your own environment and put a number on what a refurbished refresh saves.



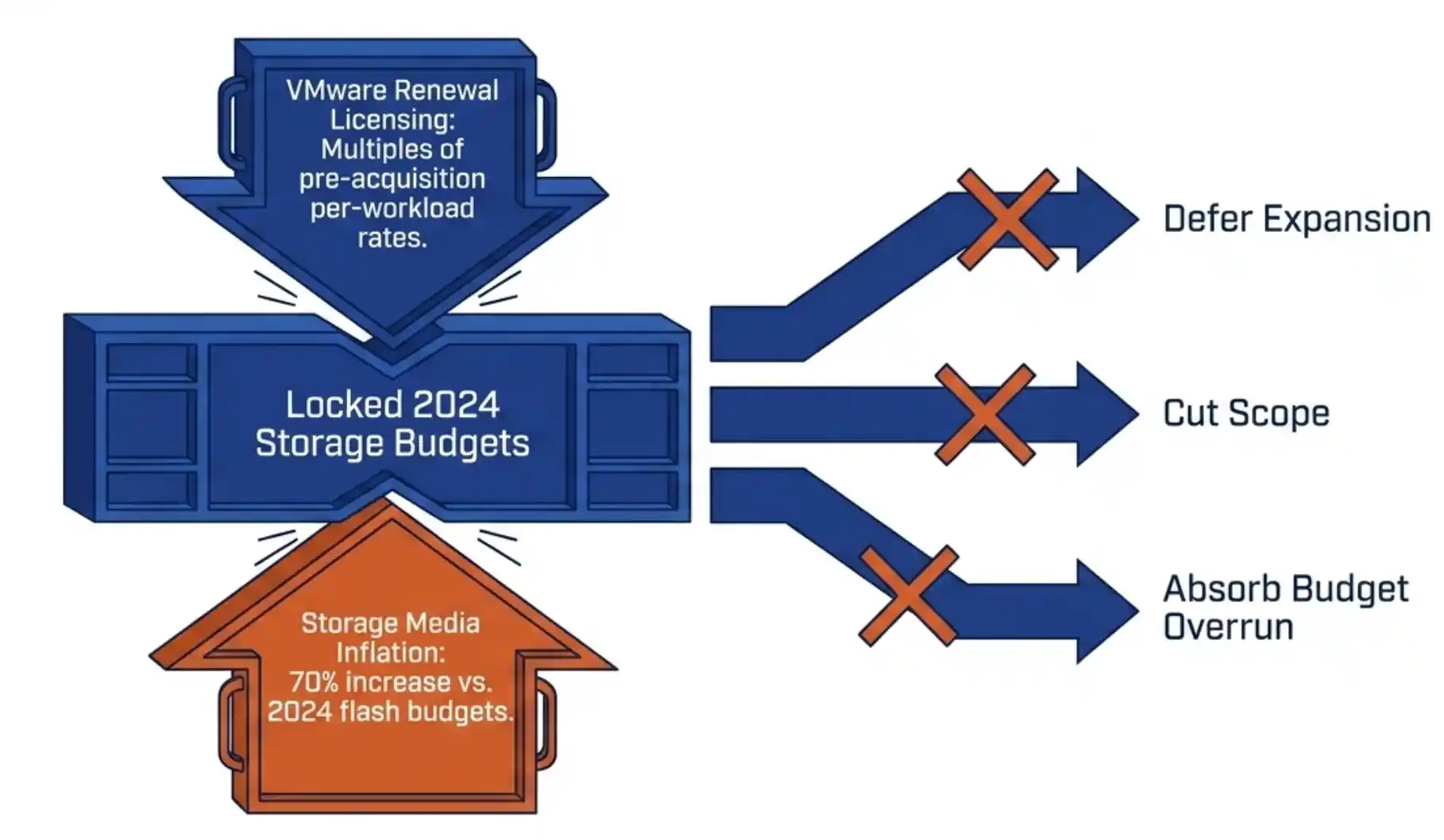 Your 2026 SAN refresh is in trouble. Flash inflation has pushed enterprise SSD prices up 70 percent. Refresh budgets locked in 2024 are now under-funded against current list pricing. The standard responses are to defer expansion, cut scope, or absorb the cost as a budget overrun. None of those options preserve the operational plan you set last year.
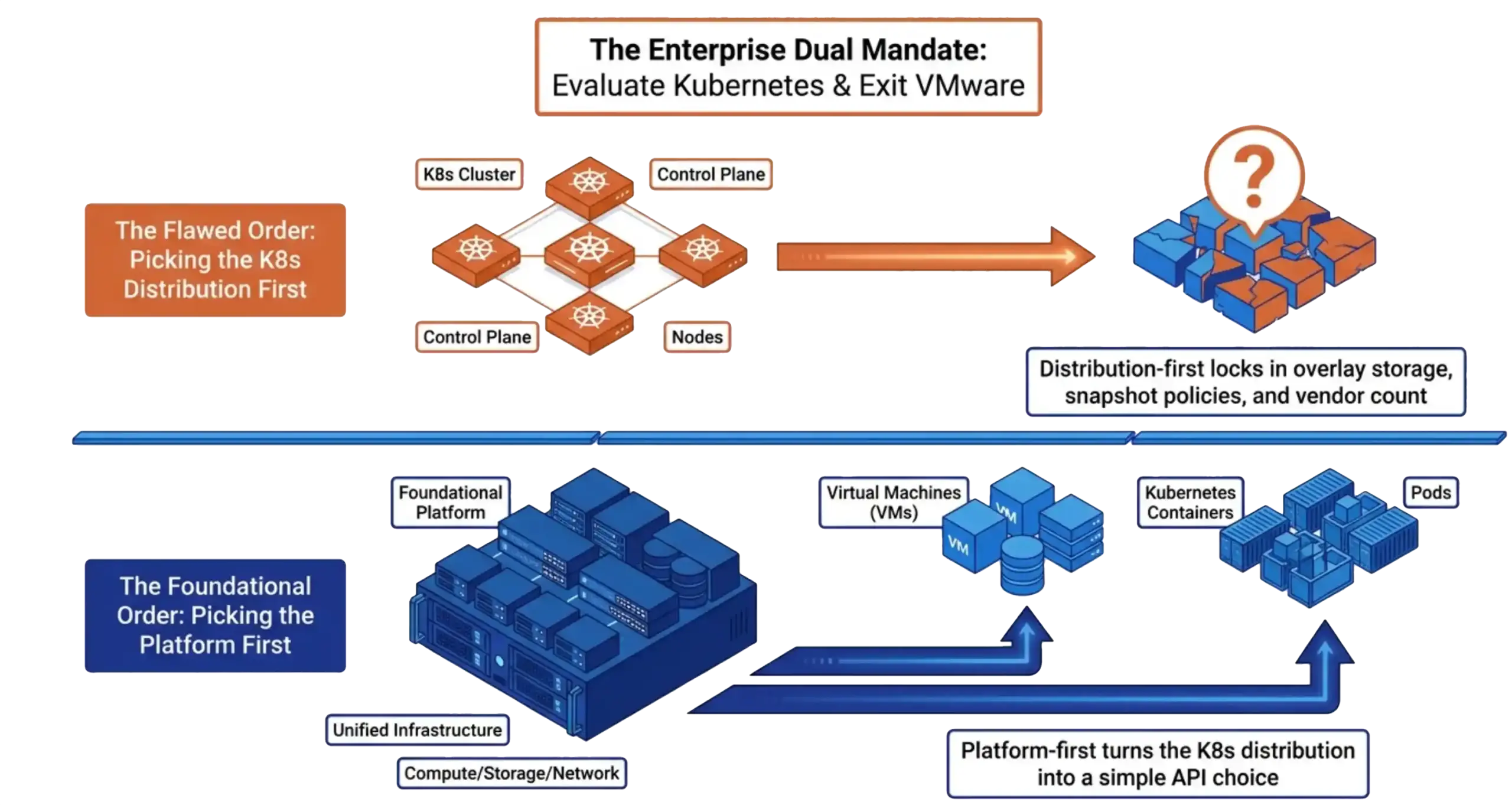
Your 2026 SAN refresh is in trouble. Flash inflation has pushed enterprise SSD prices up 70 percent. Refresh budgets locked in 2024 are now under-funded against current list pricing. The standard responses are to defer expansion, cut scope, or absorb the cost as a budget overrun. None of those options preserve the operational plan you set last year. Most infrastructure teams treat their SAN refresh and their hypervisor strategy as separate problems. The SAN refresh is a procurement decision, owned by storage architects. The VMware exit is a platform decision, owned by virtualization leads and the CIO. The two budgets land in different fiscal lines, the two evaluation cycles run on different clocks, and the two vendor conversations rarely overlap.
Most infrastructure teams treat their SAN refresh and their hypervisor strategy as separate problems. The SAN refresh is a procurement decision, owned by storage architects. The VMware exit is a platform decision, owned by virtualization leads and the CIO. The two budgets land in different fiscal lines, the two evaluation cycles run on different clocks, and the two vendor conversations rarely overlap.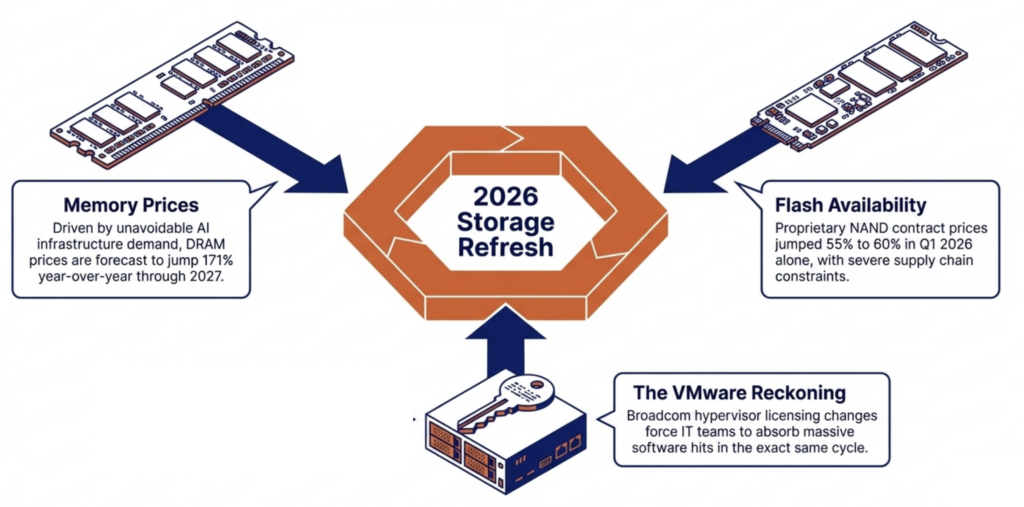

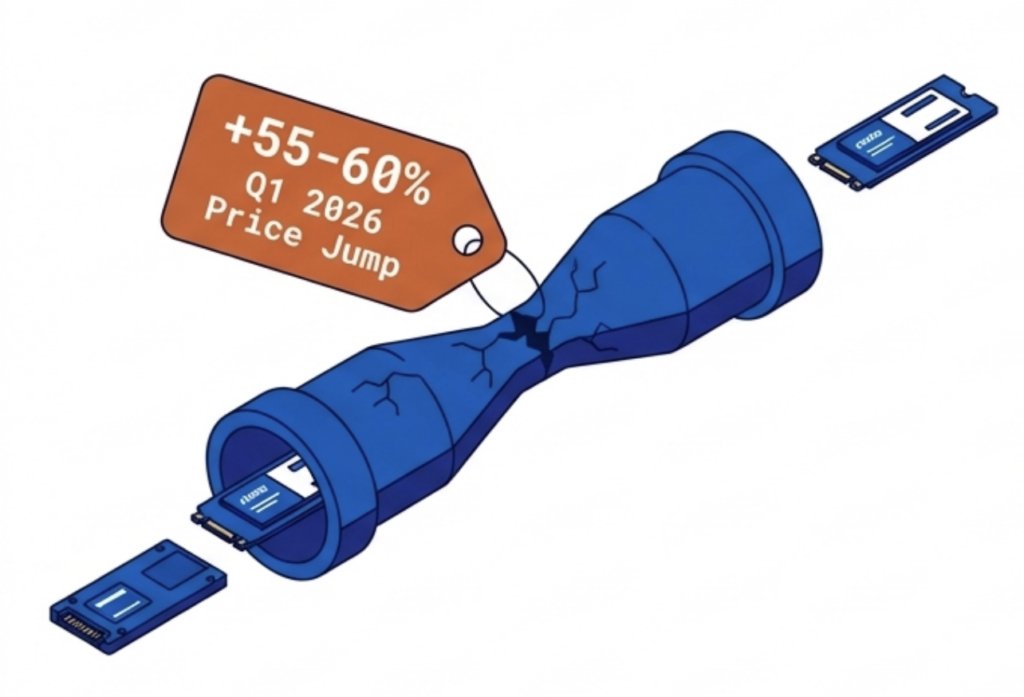
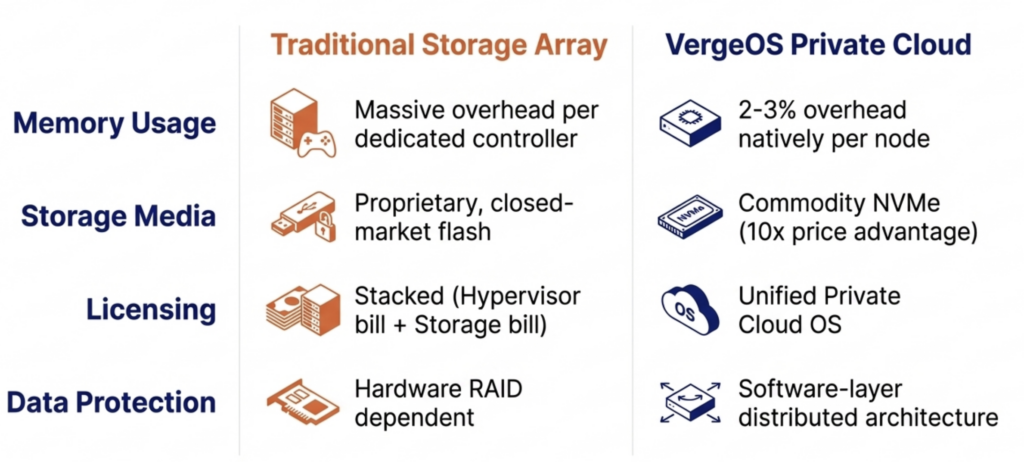
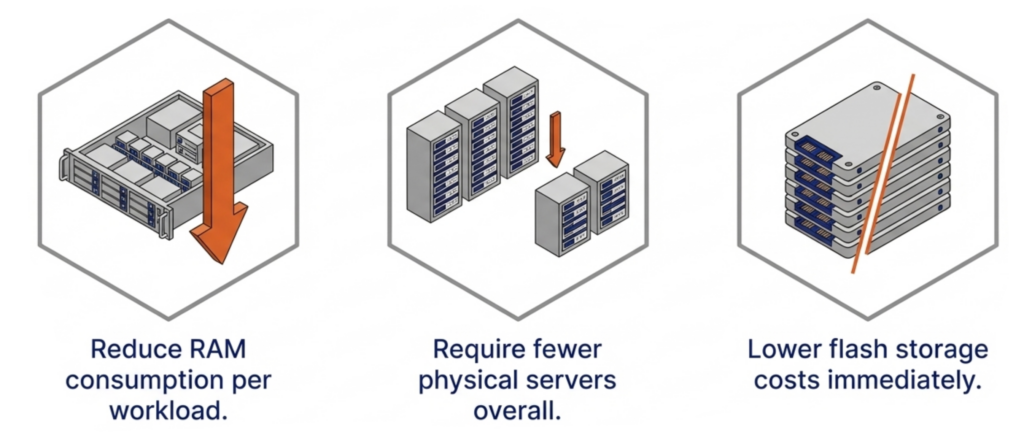 DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.
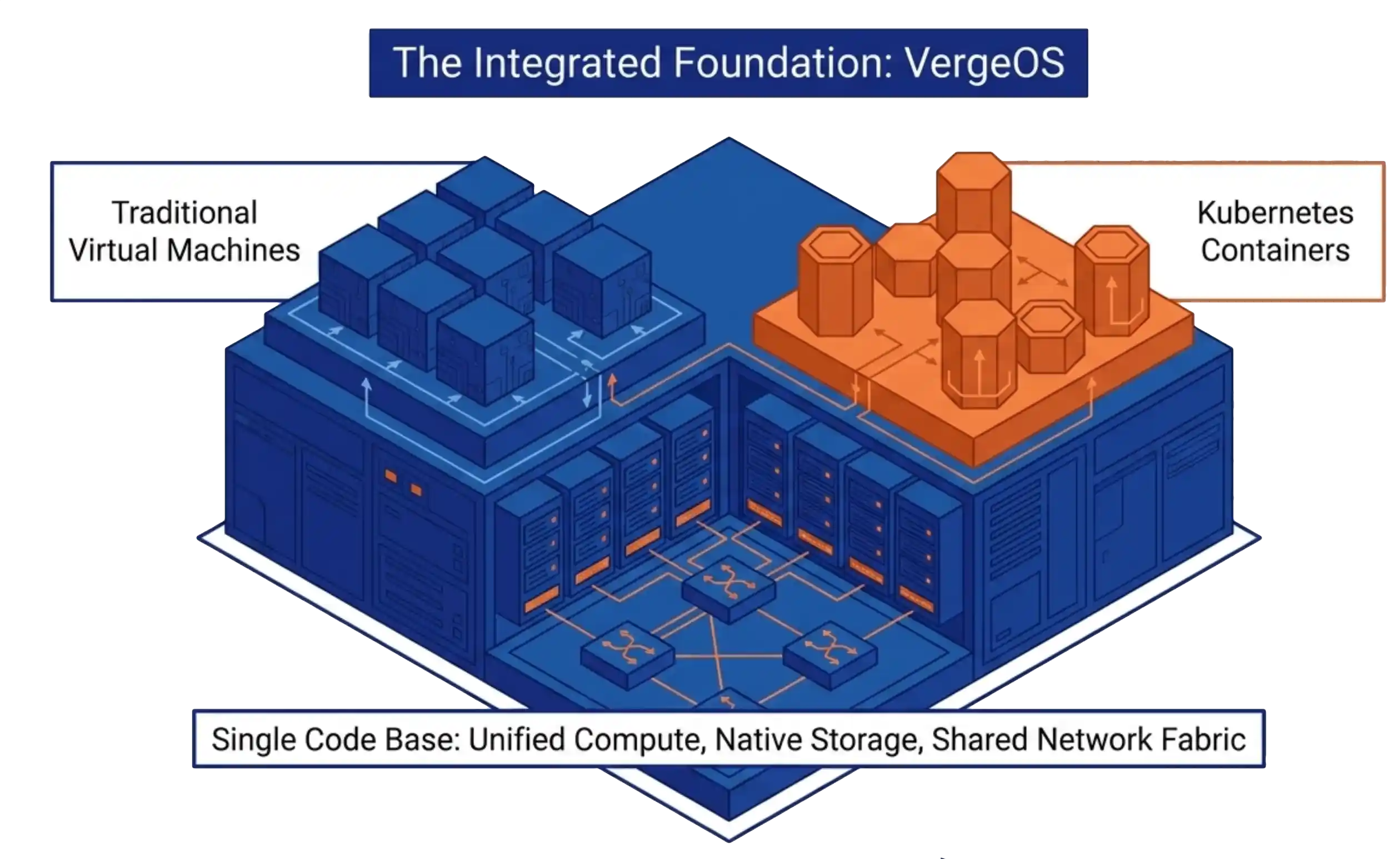
DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.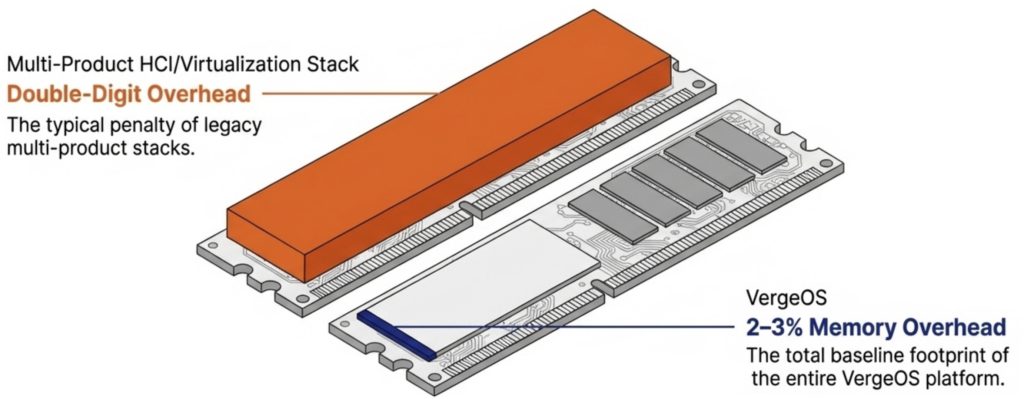 It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.
It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.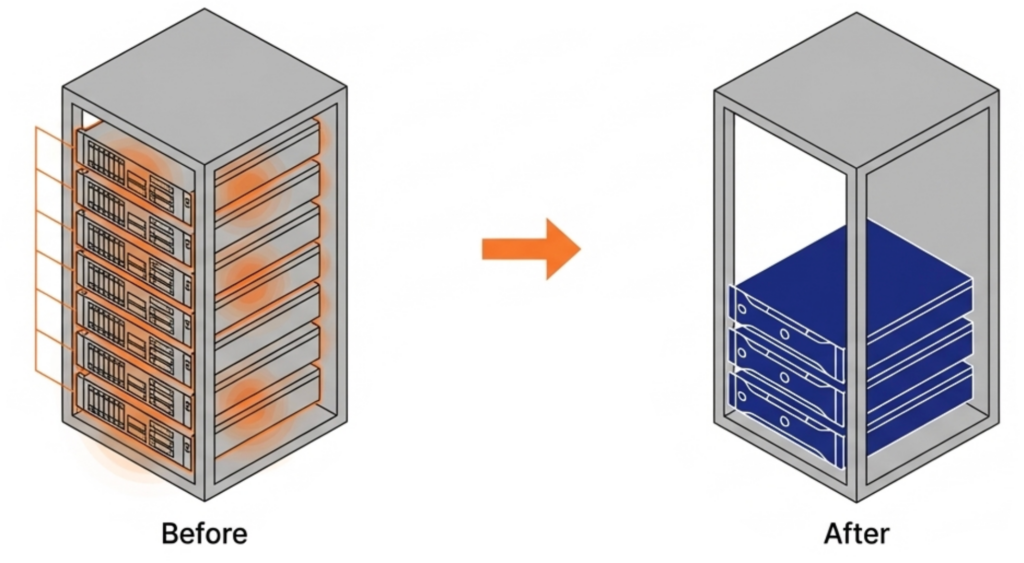 VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production.
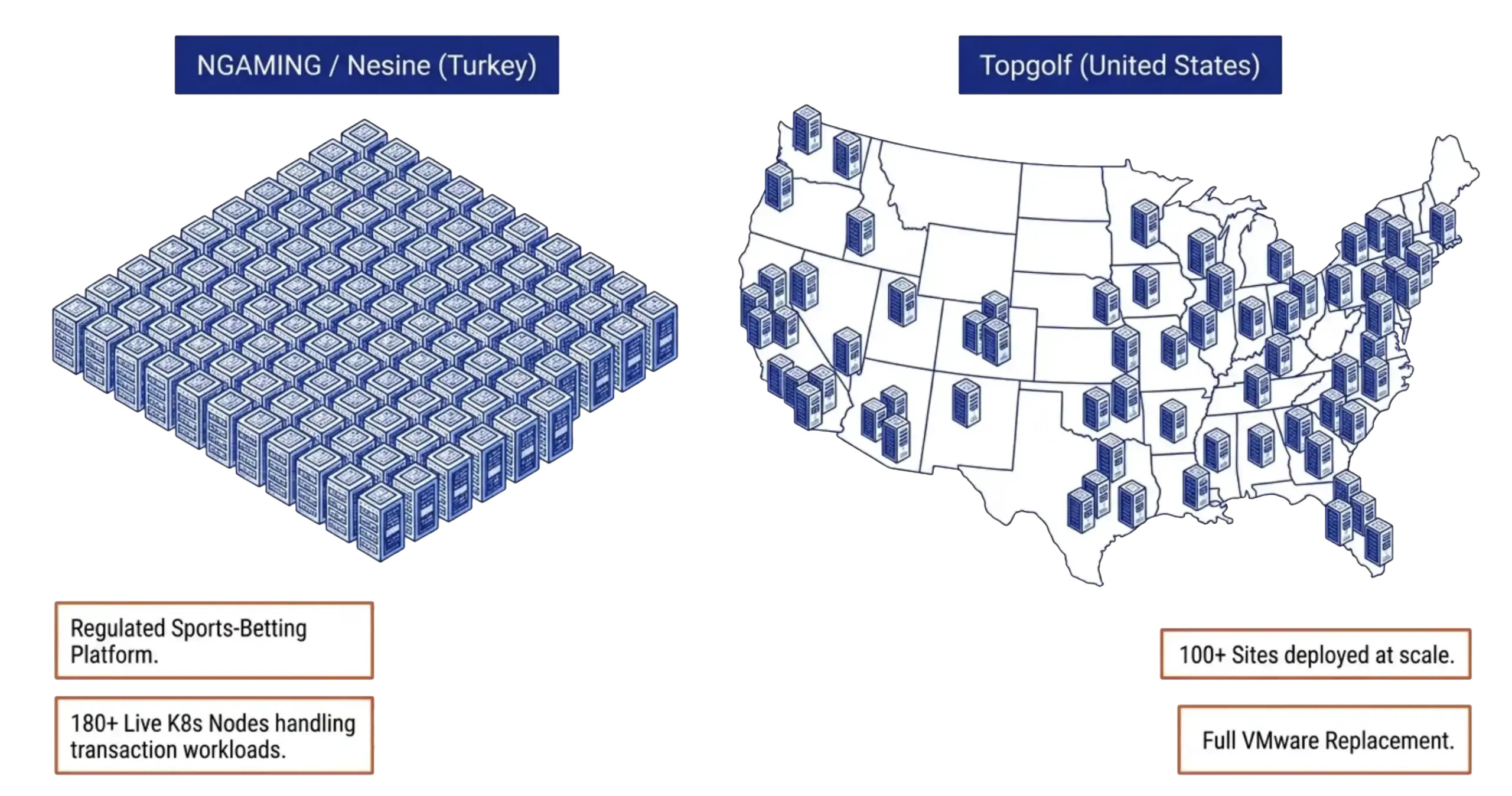
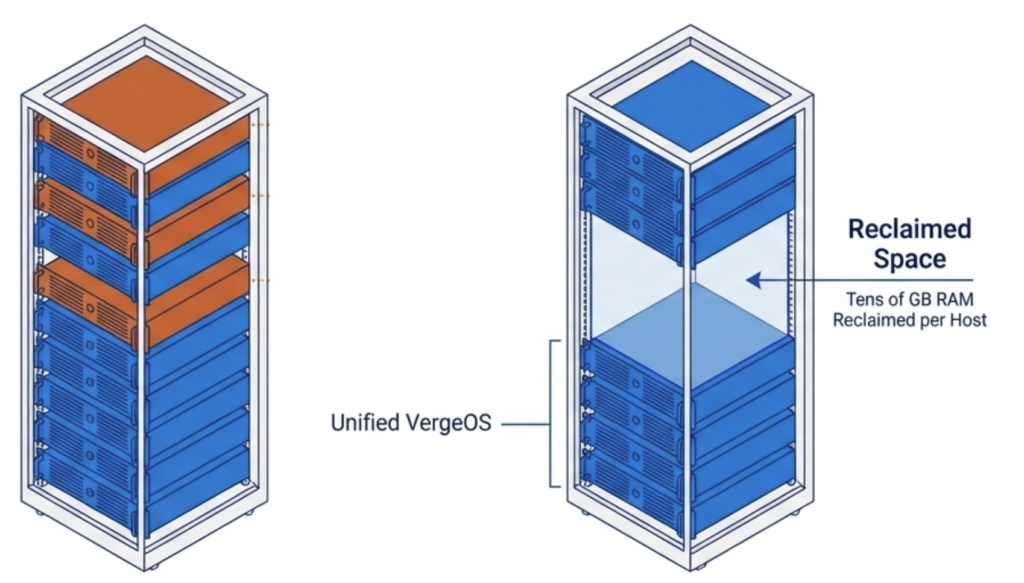
VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production.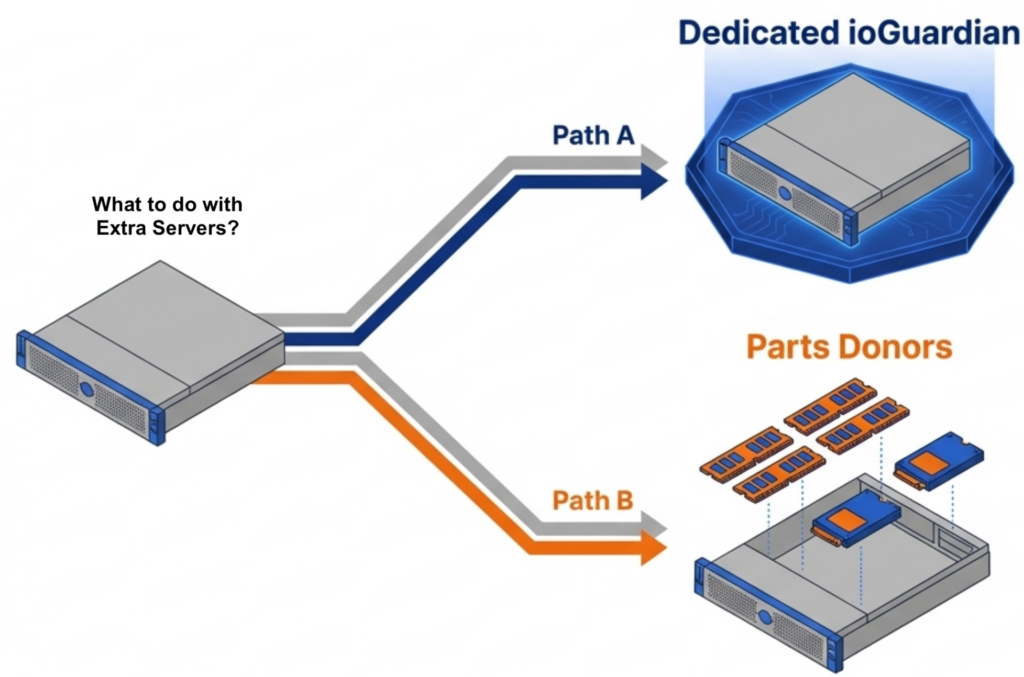 The consolidation math works across an entire fleet. An organization running 100 six-node VMware clusters that consolidates to 100 three-node VergeOS clusters frees 300 servers for repurposing, retirement, or spare parts — during a supercycle where replacement hardware is both expensive and slow to ship.
The consolidation math works across an entire fleet. An organization running 100 six-node VMware clusters that consolidates to 100 three-node VergeOS clusters frees 300 servers for repurposing, retirement, or spare parts — during a supercycle where replacement hardware is both expensive and slow to ship.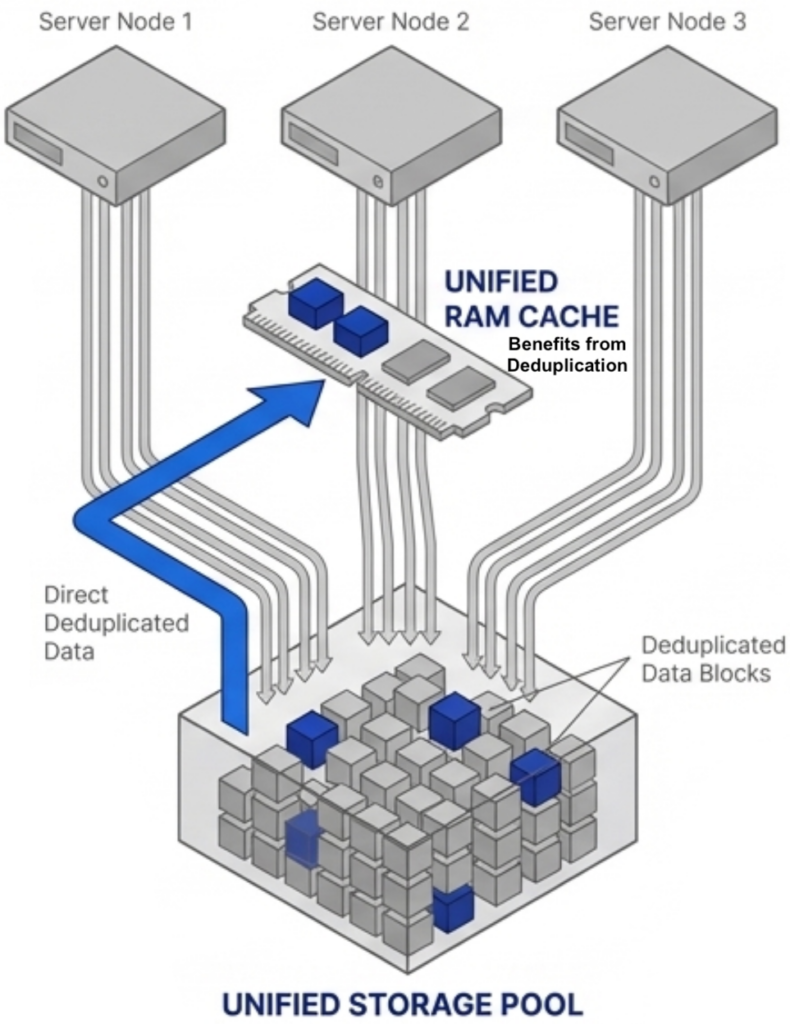 Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.
Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.