Refurbished enterprise SSDs carry four supplier-side risks. VergeOS turns each one from a procurement objection into a manageable variable. Here is the risk-by-risk catalog.
The cost case for refurbished enterprise SSDs is settled. Drives leaving hyperscale and Fortune 500 fleets typically carry eighty to ninety-five percent of rated write life remaining at forty to sixty percent below new-drive pricing, against a memory and flash market where prices are not coming back down. The objection that survives is not economic. It is risk.
Key Takeaways
- Tampered SMART data, OEM firmware lock, and residual data are caught at admission or in continuous monitoring. The drives never reach a production workload undetected.
- Batch failure correlation is absorbed by the architecture. RF2 holds one drive loss, RF3 holds two, and ioGuardian holds anything beyond by streaming missing blocks inline.
- The platform layer turns the cost-versus-risk question into a procurement decision rather than a faith-based purchase.
Four supplier-side failure modes account for almost every story of a refurbished purchase gone wrong: tampered SMART data, OEM firmware lock, residual data, and batch failure correlation. The platform layer underneath the drives decides whether those four modes are manageable variables or cluster-ending events. VergeOS turns each one into a manageable variable. Three of the four are caught at admission or in continuous monitoring. The fourth is absorbed at the architecture level when the early-warning systems missed something.
In our recent webinar, Solve the Storage Crisis with Refurbished Drives, we walked through this framework at altitude. The white paper covers it in depth. This blog sits between the two as a procurement-side reference for the IT planner who has accepted the cost case and now needs to know what the platform actually does about each risk before signing the purchase order.
Risk 1: Tampered SMART Data
The first refurb risk is tampered SMART data. Less-reputable refurbishers reset the SMART counters or reflash the controller to make a drive report low write totals, low power-on hours, and high remaining wear life. A drive bought as twenty percent used arrives looking pristine. The wear catches up under load. Customers find out three months in, after the drive has been a production member of the storage pool. The detection mechanism has to operate at intake, not at the first failure.
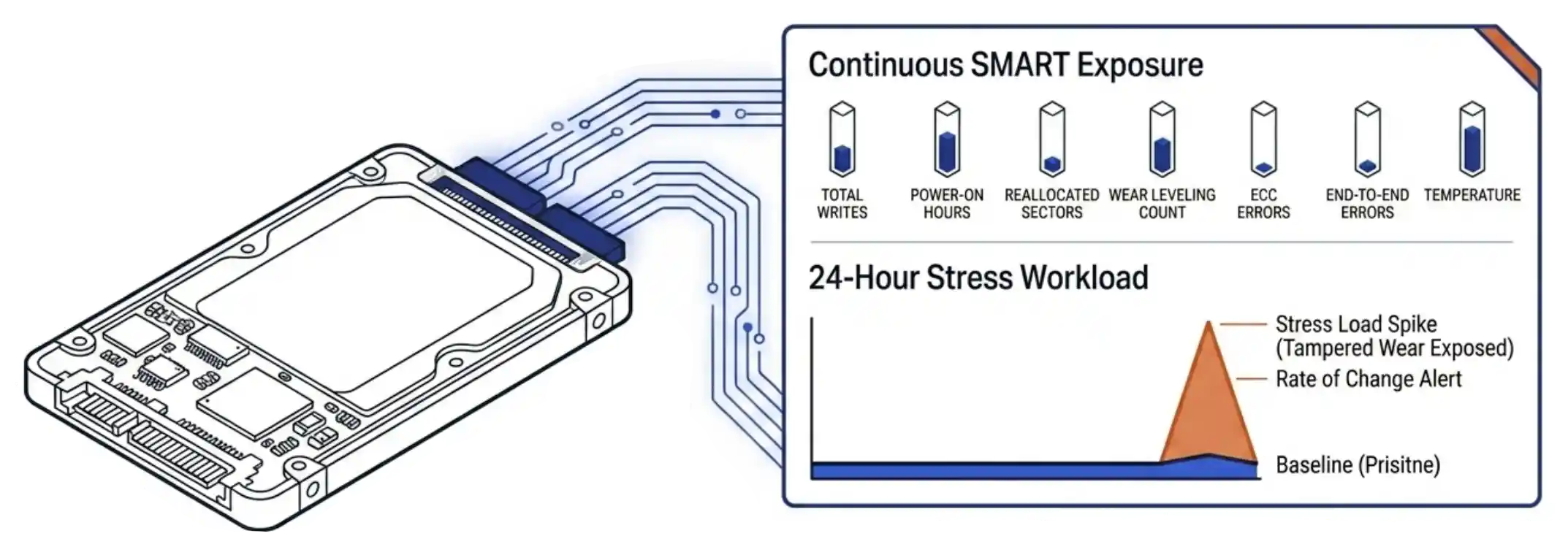 VergeOS exposes the seven primary SMART attributes on every drive in the cluster in real time: total writes, power-on hours, reallocated sectors, wear leveling count, ECC errors, end-to-end errors, and temperature. The exposure is continuous, not on-demand. A drive that arrives reporting twenty percent used wear gets watched against its reported state from the moment it joins the pool. Tampered drives reveal themselves quickly when actual write activity moves the counters faster than the reported state would predict. VergeOS alerting can be setup to warn you of signs of this behavior without you having to check in on every drive every day.
VergeOS exposes the seven primary SMART attributes on every drive in the cluster in real time: total writes, power-on hours, reallocated sectors, wear leveling count, ECC errors, end-to-end errors, and temperature. The exposure is continuous, not on-demand. A drive that arrives reporting twenty percent used wear gets watched against its reported state from the moment it joins the pool. Tampered drives reveal themselves quickly when actual write activity moves the counters faster than the reported state would predict. VergeOS alerting can be setup to warn you of signs of this behavior without you having to check in on every drive every day.
The platform supports an intake protocol that compounds the detection. A twenty-four-hour stress workload writes against the drive at near-saturation and lets the subscription model watch the rate of change. A rate-of-change alert that fires when wear advances ten points within ten days catches tampered drives within the burn-in window. The drive goes back before any tenant data touches it.
Risk 2: OEM Firmware Lock
The second refurb risk is OEM firmware lock. Some major server vendors flash their drives with firmware that refuses to operate in any chassis other than the original vendor’s hardware. The drive looks normal on the procurement spec sheet. Once the drive arrives and gets inserted, the controller refuses to mount. A buyer who orders a hundred locked drives discovers the problem at the deployment stage and now has a procurement dispute and a deployment delay.
VergeOS reads and reports the controller firmware signature at admission. Firmware-locked drives surface immediately and the platform refuses to add them to the pool. The procurement report goes back to the buyer with the drive serials, the firmware identifiers, and the supplier reference. The drives go back under warranty. The deployment continues with the drives that admitted cleanly. No production workload was ever at risk.
The architectural answer behind the admission check matters as much as the check itself. VergeOS accepts any qualified NVMe or SATA drive from any manufacturer. A buyer who hits an OEM firmware lock has alternatives. The platform is not tied to a single drive ecosystem, so the procurement reset is a matter of warranty exchange and re-order, not a forced rebuild of the storage strategy. Hardware flexibility is what makes the lock detection actionable.
Key Terms
Risk 3: Residual Data
The third refurb risk is residual data. Blancco research on used SSDs entering the secondary market finds that forty-two percent retain recoverable content from a prior owner and fifteen percent contain personally identifiable information. The risk is compliance-driven as much as security-driven. A regulated buyer who deploys a refurbished drive that turns out to hold prior-owner PII has a reporting obligation under most data-protection regimes. The primary control is supplier-side. The platform-side controls compound the supplier-side discipline.
The supplier-side primary control is NIST 800-88 sanitization at the Purge level on every drive before resale. A buyer who only buys from suppliers documenting per-drive NIST 800-88 has handled the residual-data risk at the source. R2v3-certified refurbishers perform this step as part of their operating standard. The buyer who skips this discipline has skipped the most important risk control in the refurbished SSD procurement framework.
The platform-side controls behave as a second layer. VergeFS mediates every block access through its own metadata layer, so any residual content on a drive is not addressable through tenant operations. The drive’s prior data is overwritten by normal file system activity as the pool fills. The admission process formats the drive into the pool’s metadata structure before tenant workloads land on it. The drive is never raw-accessible by anything other than the file system itself.
Risk 4: Batch Failure Correlation
The fourth refurb risk is batch failure correlation. Drives that shipped together, ran the same workload, and hit the same wear curve at the same time fail in a correlated pattern. The risk is true of new media. It is more pronounced in refurbished media, where the wear distribution is tighter than a fresh procurement order. A cluster running ten drives from the same batch is running ten drives that age together and fail together.
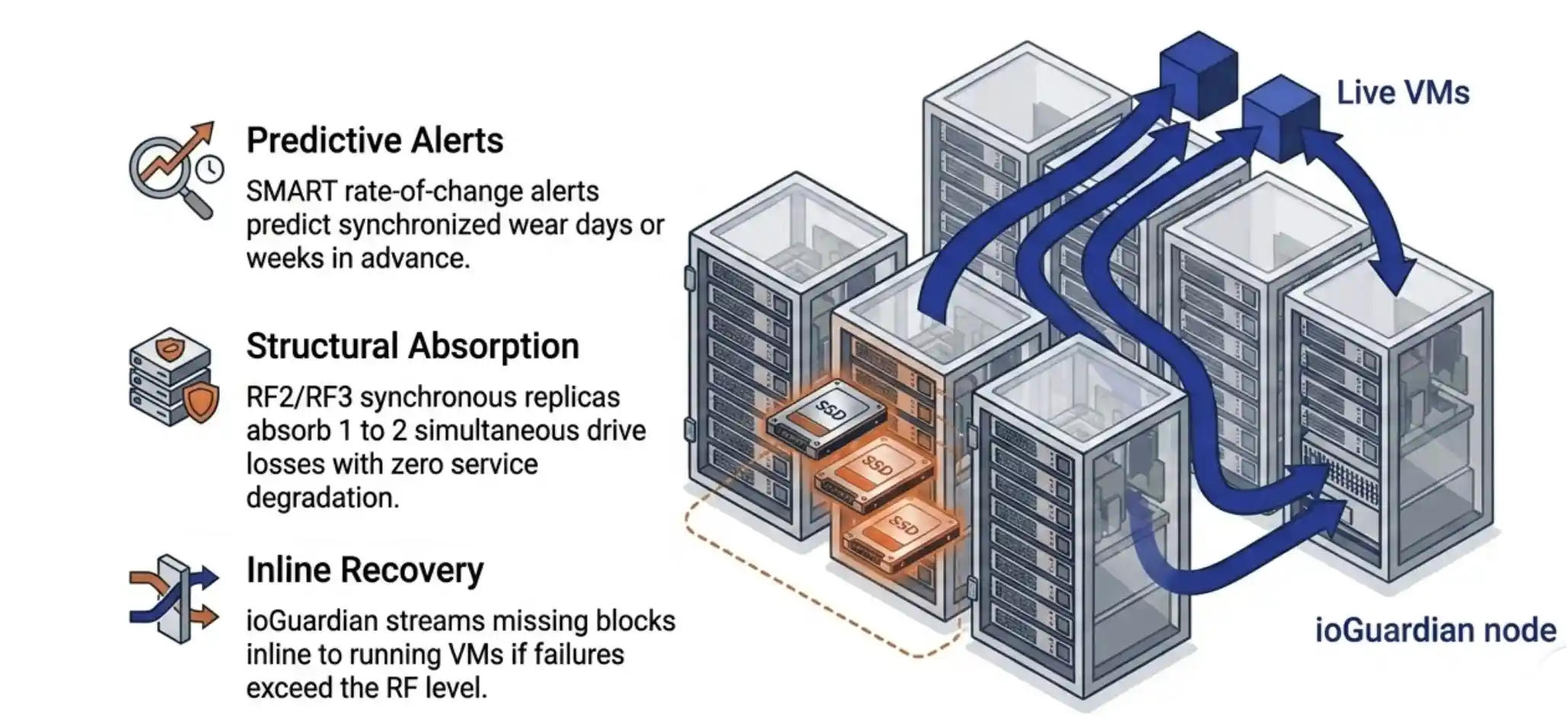 The platform handles correlated batch failure on three levels. The rate-of-change SMART subscription fires when multiple drives in a batch show wear advancing in synchronized patterns, giving the IT operator days or weeks of warning. RF2 (two synchronous replicas) absorbs the loss of any one drive without service degradation. RF3 (three synchronous replicas) absorbs two. The choice between RF2 and RF3 is a capacity question, and most customers run RF2 once they understand the layer above it.
The platform handles correlated batch failure on three levels. The rate-of-change SMART subscription fires when multiple drives in a batch show wear advancing in synchronized patterns, giving the IT operator days or weeks of warning. RF2 (two synchronous replicas) absorbs the loss of any one drive without service degradation. RF3 (three synchronous replicas) absorbs two. The choice between RF2 and RF3 is a capacity question, and most customers run RF2 once they understand the layer above it.
The layer above RF2 and RF3 is ioGuardian. The platform holds a complete asynchronous copy of the cluster on a separate node and streams missing blocks inline when a failure exceeds the configured RF level. Concurrent loss of multiple drives or even multiple servers becomes a continued-service event rather than a recovery event.
The cost advantage of refurbished enterprise SSDs is real. The four supplier-side risks are also real. The platform underneath the drives decides whether the second cancels the first. VergeOS turns each risk into a manageable procurement variable. The buyer keeps the savings. The platform handles what the supplier alone cannot.
George Crump and Aaron Richman walk the secondary-market case, the procurement framework, and the architectural model that makes refurbished enterprise drives a procurement decision rather than a courage test.
The full architecture case, the procurement framework at depth, the four risk categories, the synchronous replication model, the SMART monitoring loop, and the five-gate decision path.
Refurb Risk Treatment: Naive Platform vs VergeOS
| Risk | Naive Platform | VergeOS |
|---|---|---|
| Tampered SMART | Detected after deployment, sometimes after failure | Continuous SMART exposure plus 24-hour intake stress workload plus rate-of-change alerts |
| OEM firmware lock | Discovered when the drive refuses to mount | Firmware signature reported at admission, drive blocked from pool |
| Residual data | Buyer-dependent, raw blocks may be tenant-accessible | VergeFS mediates all block access, supplier NIST 800-88 enforced upstream |
| Batch failure correlation | Cluster-ending event during rebuild storm | Rate-of-change alerts plus RF2 / RF3 plus ioGuardian inline recovery |


