Live webinars produce one piece of data no white paper captures cleanly. That data is the audience poll. On May 20, the first poll on Kubernetes Without the VMware Tax asked attendees how their team runs Kubernetes in production today. Roughly half answered the same way. Kubernetes is still in the evaluation column, not yet running in production.

The trade press paints a picture of every enterprise running Kubernetes for years, and the poll told a different story. For a team in that evaluating column, the exit from VMware has become the new priority. The real question is whether the team can evaluate Kubernetes and exit VMware at the same time.
The argument is straightforward. The platform underneath the Kubernetes layer decides more of the long-run operations math than the distribution does. The full architectural case lives in Collapsing the Kubernetes Stack, the long-form companion paper to this post, and the dollar math gets walked separately in The Kubernetes VMware Exit Math, Explained. Pick the platform last, and the distribution choice locks in the storage layer, the snapshot policy, and the vendor count. Pick it first, and the distribution choice becomes a distribution choice.
Key Takeaways
- Pick the platform first. Exiting VMware to a platform that understands containers answers the foundation question and the distribution question inside the same project.
- Running Kubernetes on a hypervisor not designed for container workloads adds a translation tax in storage, networking, and lifecycle, and that tax compounds at every renewal.
- VergeOS publishes three Helm charts from a single Cluster Repository on GitHub, ships persistent volumes natively from the same storage that runs the VMs, and presents both workload types through Rancher. One platform, one support contract, two workload types.
Does the environment need Kubernetes?
The hardest question for a team evaluating Kubernetes is not which distribution to pick. The hardest question is whether the environment needs Kubernetes at all. Plenty of environments need Kubernetes for the right reasons. Plenty of others do not, and the honest answer matters more than the marketing.
The honest answer in the room on May 20 came from David Zarzycki, the engineer who did most of the work on the VergeOS Kubernetes integration. His phrasing was the right one. Is your environment complex enough to warrant the complexity of running Kubernetes at all?
Kubernetes earns its keep when applications change frequently, when teams ship daily, when multi-tenancy is real, when GPU scheduling matters, and when developer self-service is a stated requirement. A two-tier ERP application with a six-month release cycle does not need Kubernetes. A microservices platform with twenty deploy events per day does. Most production environments have both kinds of workloads sitting side by side, and that mix is exactly why the foundation question matters more than the distribution question.
A clean example of a Kubernetes-shaped workload looks like a retail analytics platform that ingests several million transaction events per hour, runs a dozen microservices scaling independently against the event stream, and ships code multiple times a day with feature flags and blue-green rollouts. Storage demand spikes during peak hours. Compute demand spikes around marketing campaigns. The engineering team treats every service as independently deployable. That workload pattern is what Kubernetes was built for, and the platform underneath has to keep up with it. The two-tier ERP application sitting next to that platform does not need any of that machinery, and asking Kubernetes to run it is the wrong tool for the wrong job.
Key Terms
The foundation question, not the distribution question
Kubernetes evaluations almost always start with the distribution shortlist. The standard candidates are Tanzu, OpenShift, Rancher Prime with RKE2 or K3s, and upstream Kubernetes on bare metal. Tanzu’s long goodbye makes that grading harder for any team still committed to vSphere. Each shortlist gets graded against developer experience, ecosystem depth, support contracts, and price. The platform underneath the cluster nodes is a separate conversation. The hypervisor, the storage layer, and the network fabric get graded last, if at all.
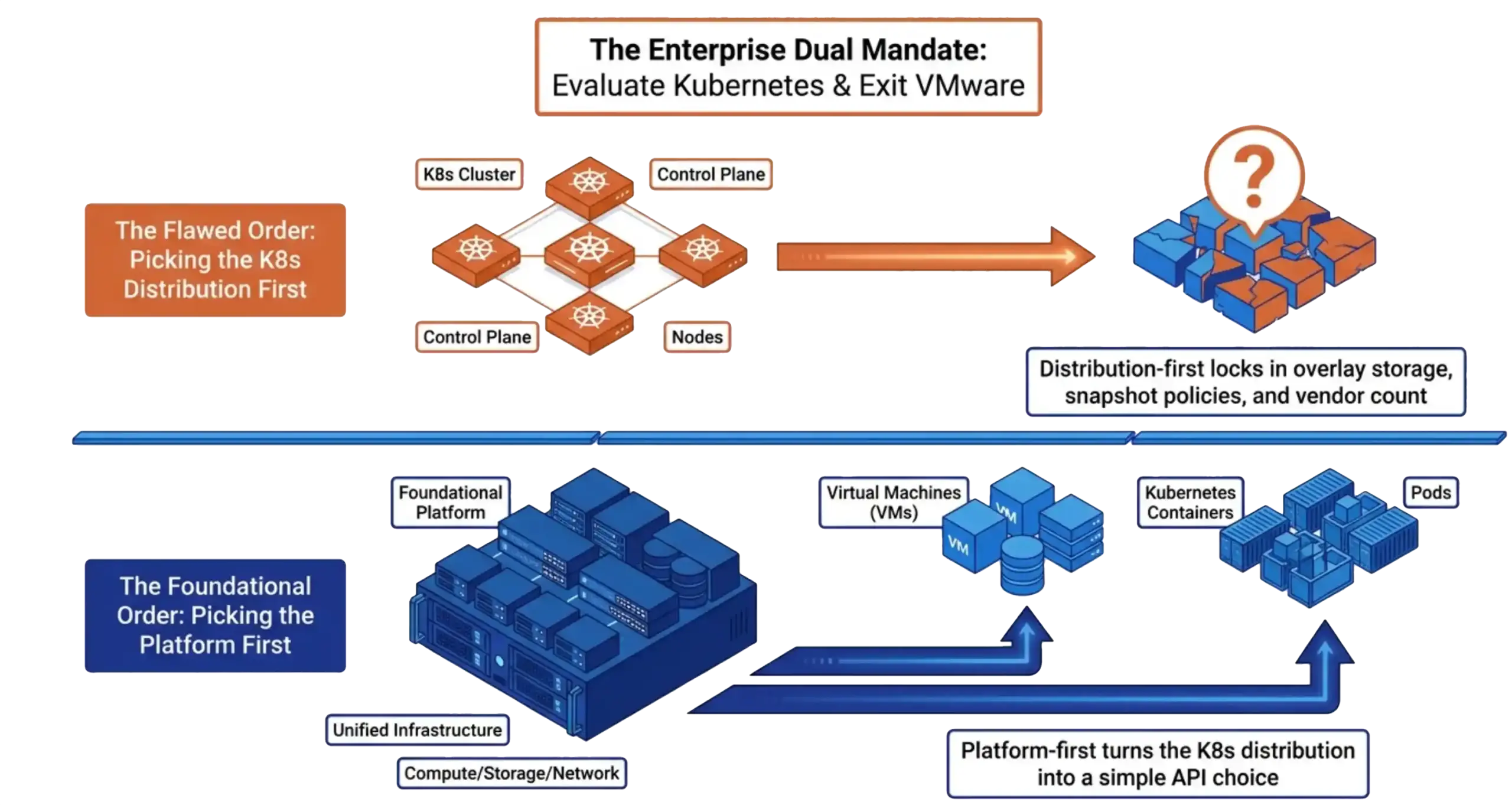
That order is backward. The platform underneath decides how persistent volumes get carved, how cluster nodes scale, how snapshot and replication policies coordinate across VMs and pods, and how many vendor support contracts the operations team carries forever. The Kubernetes distribution determines which API the developer interacts with. Both matter, and the platform decides more.
The reason the order keeps getting reversed is that the distribution choice is louder. There are conferences for Tanzu and conferences for OpenShift. There is no conference for “the platform underneath.” Teams evaluating Kubernetes hear the loudest voices first and rank the platform later. The five-year math punishes that order.
The platform question reduces to a simple test. Count the support contracts the operations team will carry once the evaluation is over. Count the snapshot engines. Count the storage systems. Count the network control planes. Every number greater than one in that list is a translation tax line item. Every one of those line items comes from picking the distribution first and letting the distribution dictate the platform.
What changes when the platform underneath is integrated
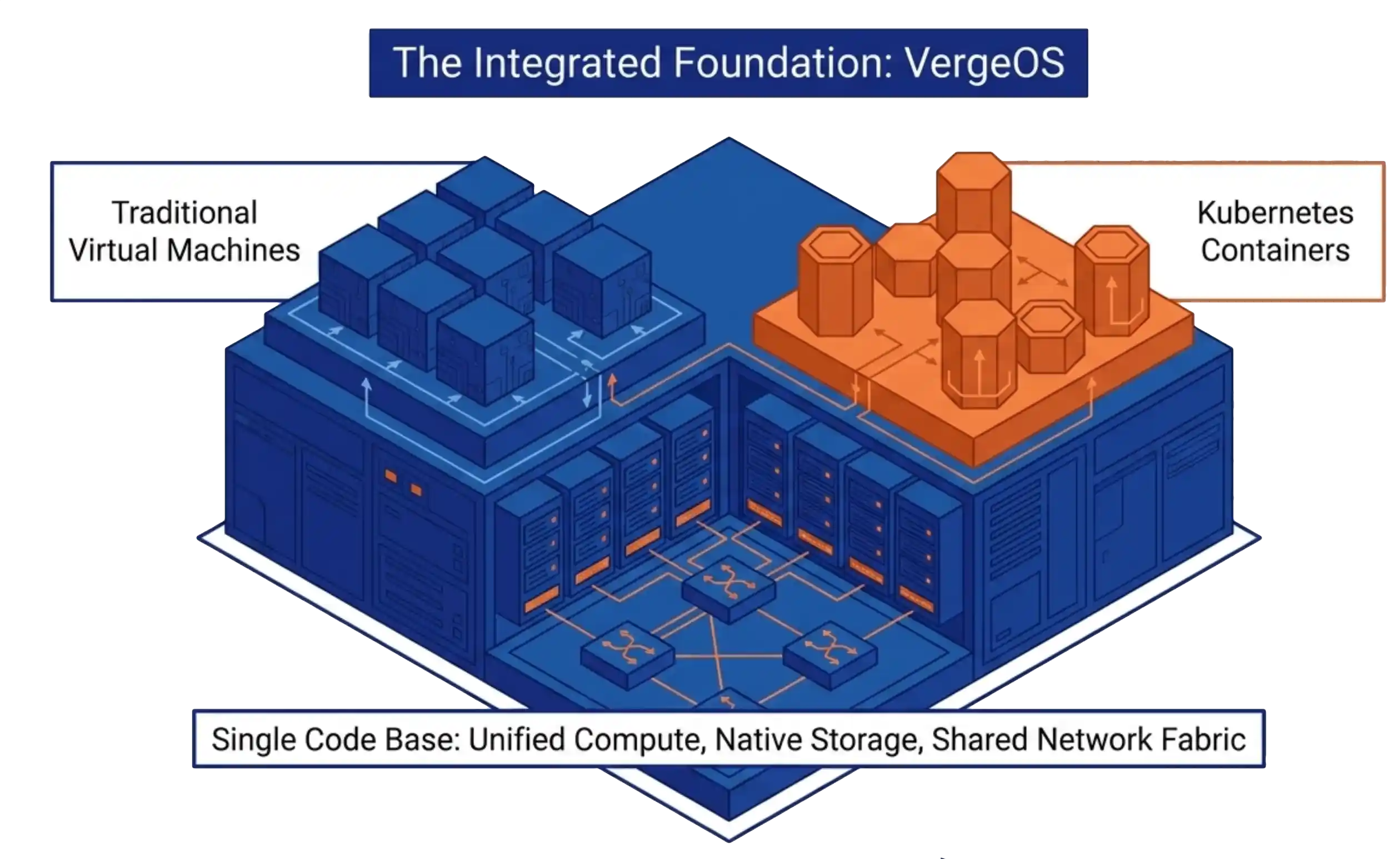
VergeOS treats VMs and Kubernetes containers as workloads on the same code base. The hypervisor, the storage layer, the network fabric, and the Kubernetes integration share one platform. Three Helm charts pulled from one Cluster Repository on the verge-io GitHub. A CSI driver provisions persistent volumes from VergeFS directly, with no overlay storage layer between the pod and the disk. A Cloud Controller Manager handles networking and node lifecycle events through the standard Kubernetes interface. A Cluster Autoscaler handles node-count management through the same upstream project every other distribution uses.
What that means in practice. Rancher remains the management plane the operations team already knows. The cluster object stays standard. The persistent volume comes off the same storage fabric the VMs use, with no Longhorn to license and no Portworx contract to manage. The Kubernetes distribution is whichever flavor Rancher provisions, usually RKE2 or K3s, both upstream. The platform underneath handles the rest, on the same code base it uses to run the VM side of the house. The Kubernetes Without the VMware Tax datasheet lays the architecture diagram and the deployment flow side by side for teams that want the one-page reference.
The typical vSphere Kubernetes stack vs an integrated platform
| Capability | Typical vSphere Kubernetes Stack | VergeOS |
|---|---|---|
| Hypervisor licensing | VCF subscription, per-core pricing | Included in the platform |
| Kubernetes distribution | Tanzu, OpenShift, or Rancher Prime, separate contract | RKE2 or K3s via Rancher, no separate licensing |
| Persistent volumes (CSI) | Vendor CSI driver, overlay storage often required (Longhorn, Portworx) | Native VergeOS CSI driver, no overlay storage |
| Networking and load balancing | Vendor CNI plus separate load-balancer contract | Cloud Controller Manager via standard Kubernetes interface |
| Snapshot and replication | Two policy engines, one for VMs, one for K8s | One snapshot and replication engine, both workload types |
| Vendor support contracts | Three or more | One |
| Cluster create time (May 20 live demo) | Variable, often 15 to 20 minutes | Six minutes, on a lightweight lab system |
Why Rancher?
VergeOS works with any Kubernetes distribution that runs on standard upstream nodes. The integration is upstream by design, three Helm charts and a node driver, no fork and no proprietary kernel extension. A team already running OpenShift or Tanzu can keep that distribution and put VergeOS underneath it.
A team that has not committed to a distribution yet should start with Rancher. The reasoning is practical. Rancher carries the lightest commercial weight of the major management planes, with no separate licensing layer attached to RKE2 or K3s. The node driver integration is the cleanest path to a working cluster on VergeOS. The cluster lifecycle, upgrade, and visibility story all sit in one console the operations team learns quickly. Standing up a first cluster on Rancher takes minutes, and the resulting cluster is upstream Kubernetes. No fork, no proprietary distribution to retrain against, and no vendor exit story to plan for later.
Production proof, named on the live call
Two customers got named on the May 20 webinar, and both are cleared for public use. NGAMING / Nesine in Turkey runs a regulated sports-betting platform on VergeOS, with over 180 Kubernetes nodes carrying live transaction workload. The same production validation appears in the VergeIO Kubernetes general availability announcement.
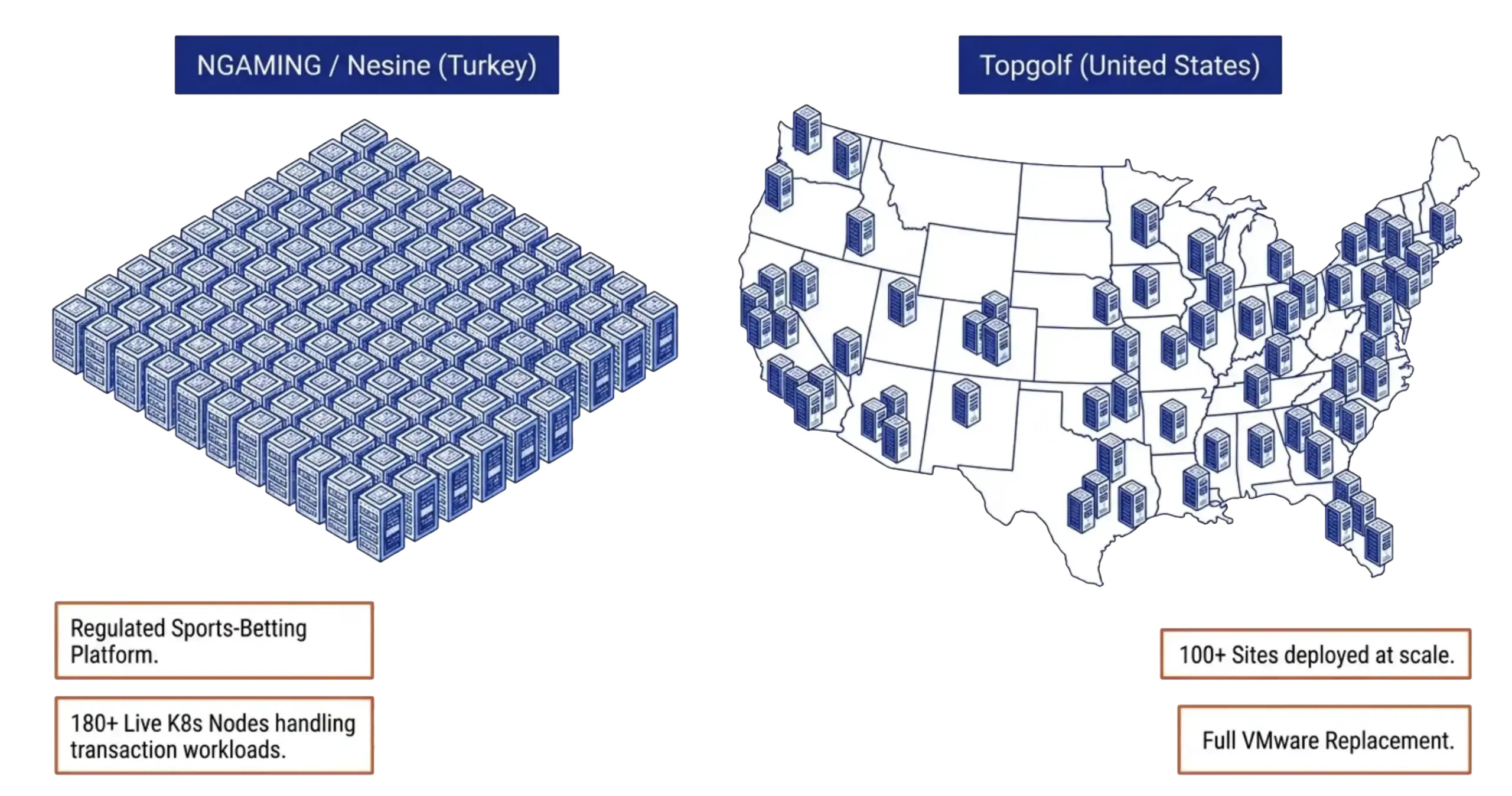
Their feedback in the rollout was that the engineering response cycle felt like having a software development shop on call, even across time zones. That kind of feedback is rare, and it came up for one reason. The engineers who wrote the VergeOS SDKs are the same engineers who wrote the Kubernetes integration. Same team, same code base, same release cadence.
Topgolf is the second name. Over a hundred VergeOS sites across the United States, replacing VMware. The reason Topgolf gave for choosing VergeOS was not the platform alone. It was the platform plus the partnership, agile enough to respond at scale and capable enough to run the full environment. Both customers are evidence that the integrated-platform argument scales from a 180-node Kubernetes cluster in Turkey to a hundred-site VMware replacement in the United States, on the same code base.
How to start evaluating Kubernetes the right way
The clean path for a team evaluating Kubernetes from a standing start looks like this. Stand up VergeOS as the platform. Register the verge-io Cluster Repository in Rancher. Provision a test cluster through the Rancher UI. Run workloads on it. Cluster creation took six minutes on the live demo, on a lightweight home-lab system with two cores and four gigabytes of RAM per node. Production environments run faster. The three Helm charts come from the same repository. The persistent volumes come from VergeOS storage. The Rancher cluster object behaves exactly the way it would on any other Rancher node driver.
The webinar walks the live demo on real hardware. The white paper walks the full architectural argument.
From there the distribution question becomes which flavor of upstream Kubernetes Rancher provisions for the team, with RKE2, K3s, or upstream Kubernetes as the practical options. The platform decision is already made. The vendor count is one. The migration question other teams are still working through does not show up at all. There is nothing to migrate from. The team that picks the platform first gets to keep the evaluation focused on the part that matters, which is whether Kubernetes fits the workload, not whether the storage layer fits the Kubernetes distribution.
The fastest way to validate the foundation argument against a specific environment is a 30-minute architecture overview with one of the engineers who built the integration. Aaron Richman, Field Evangelist at VergeIO and one of the presenters on the May 20 webinar, runs these sessions directly. The agenda is the team’s environment, the workloads under consideration, and the path from the current VMware footprint to a VergeOS deployment that handles VMs and Kubernetes on one platform. No slide deck. The session works against a real environment. Book a session and the conversation starts where the webinar left off.
Why this matters to a team still evaluating Kubernetes
The CloudBolt CII study and the most recent CNCF surveys both show the same pattern. Teams deploying Kubernetes on top of a hypervisor not designed for container workloads spend more on storage, more on vendor support, and more on operations than teams picking an integrated platform from the start.
The gap widens at every renewal. Most evaluations get the order wrong, and the reason is consistent. The distribution choice is louder, and the platform choice shapes the next five years.
The teams in the evaluating column during the May 20 webinar still have a chance to get this order right. The teams that have already moved are working through the migration version of the same question. The order matters more than the urgency.
Frequently Asked Questions
We are not running Kubernetes yet. Do we still need to think about a platform like VergeOS now?
Can VergeOS run alongside our existing VMware environment during evaluation?
Which Kubernetes distribution does VergeOS provision?
Do we have to commit to Rancher to use VergeOS Kubernetes support?
What happens to our existing VMs when we add Kubernetes workloads?
How long does a real production cluster take to provision?
Next steps
The Collapsing the Kubernetes Stack white paper, the Kubernetes Without the VMware Tax datasheet, and the on-demand recording of the May 20 webinar all live in the Kubernetes Without the VMware Tax research center. The fastest way to validate the foundation argument is on your own hardware, with your own workloads. Take a Test Drive Today and provision a Kubernetes cluster through Rancher on VergeOS the same way David showed live.


