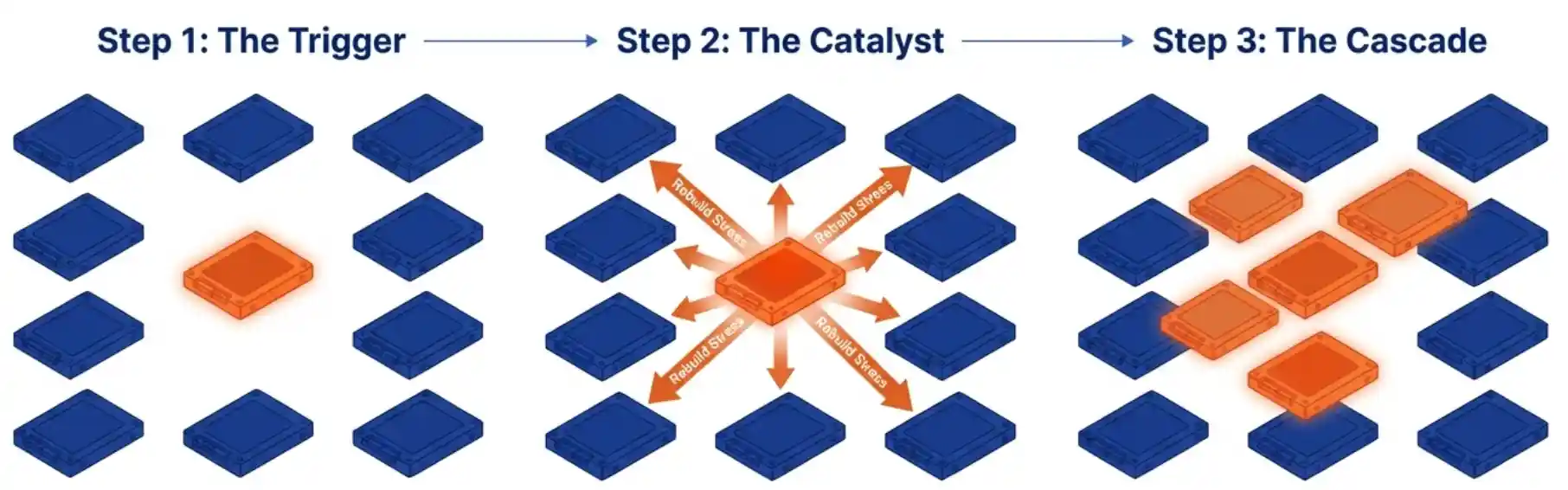
Cascading drive failure is the storage scenario every IT operator wants to never live through. Picture this. A six-node hyperconverged environment running production workloads. A drive fails on one of the nodes. The rebuild starts. Mid-rebuild, a second drive fails. More rebuilds spin up. A third drive fails. Then a fourth. The cluster has now exceeded the tolerance of RF2, the standard two-copy synchronous replication model in VergeOS. It has also exceeded RF3 if you happened to be running it. On most platforms, this cascading drive failure has just ended the cluster, the VMs are stopped, and recovery is a tape-restore conversation.
Key Takeaways
- Cascading drive failure is the dominant concurrent-failure pattern, not the exception. One drive fails, rebuilds kick off, surviving drives wear faster under the rebuild load, and the next failure arrives before the cluster has recovered from the first.
- Hyperconverged and ultraconverged architectures raise the stakes on cascading drive failure. Compute and storage share nodes, so a node loss takes both layers down at once.
- RF2 and RF3 absorb the first one or two losses. ioGuardian streams missing blocks inline beyond that. Live VM migration moves workloads off degraded nodes in parallel. Users see no interruption.
VergeOS handles a cascading drive failure differently. As each drive fails and the failure surface widens, ioGuardian streams the missing blocks inline to the running VMs as the VMs request them. The platform also live-migrates the affected VMs off the most degraded nodes to surviving ones. By the time three or four servers have effectively crashed, the users are still accessing their applications and data. They never see the cascade happen.
The scenario above is a thought experiment built from common failure patterns. Same-batch drives age together. Rebuild storms stress surviving drives and accelerate the next failure. Correlated wear pushes the cascade forward. The pattern is not exotic, it is statistically expected on used media and possible on new media. The architecture that makes the outcome survivable is shipping today. Once you understand how it works, the case for using refurbished media on the right platform becomes a procurement decision rather than a courage test.
Why Cascading Drive Failure Happens
Cascading drive failure is not exotic. Every hyperscaler operating at scale has documented this pattern in their published field data on flash drives. When one SSD fails inside a same-batch group, the probability that two or three more in that group fail within days is materially elevated. The drives shipped together, ran the same workload, and reached the same point on their wear curves at the same time. Rebuilds make it worse, not better, since the surviving drives carry the rebuild load and accelerate their own wear. This is true of new media. It is more true of refurbished media, where the wear distribution is tighter than a fresh procurement order.
The architectural answer is the same regardless of failure cause. Consider three causes: a same-batch firmware bug, correlated end-of-life on a single procurement order, and rebuild stress that propagates the next failure. All three look identical to the storage layer. The platform either absorbs the cascading drive failure without service interruption or it does not. Refurbished drives raise the prior probability of a cascade. They do not change the response model.
Converged architectures raise the stakes further. Hyperconverged and ultraconverged platforms run compute and storage on the same physical nodes, so the loss of a node takes both layers down at once. A cluster experiencing cascading drive failure across the same week is also watching three VM hosts wobble. The architectural answer has to absorb both halves of that failure surface, not just the storage half. Refurbished media on a converged platform without inline recovery compounds the problem in two dimensions at once. The protection model has to cover storage and compute simultaneously or it does not cover anything that matters.
How VergeOS Absorbs Cascading Drive Failure
VergeOS uses synchronous replication rather than erasure coding. RF2 maintains two copies of every block on different drives across different nodes. RF3 maintains three. A write only completes once the second or third copy acknowledges. The platform survives the loss of any drive, and at RF3 the loss of any two, with no parity calculation, no rebuild storm, and no degraded-mode performance penalty. The choice between RF2 and RF3 is a capacity question, not an architecture question. The replication model is the same.

ioGuardian extends the protection model beyond the replication tolerance. It is a separate node holding a complete asynchronous copy of the cluster, updated on every system snapshot. When a failure exceeds the configured RF level, ioGuardian does not attempt to rebuild the failed drives. It steps inline and delivers the missing blocks to the running VMs as the VMs request them. Recovery is not a process that runs in the background. Recovery is the data path itself.
The compute layer responds in parallel. As nodes degrade past the threshold where they can serve workloads reliably, VergeOS live-migrates the affected VMs to surviving nodes. The VMs themselves see no interruption. The combination of inline storage recovery plus continuous VM migration is what lets the cluster absorb the loss of multiple servers without service impact, even when the cascading drive failure exceeds both RF2 and RF3 tolerances.
The Ultra Converged Infrastructure model adds another dimension to cascade resilience. VergeOS supports heterogeneous node types in the same cluster: storage-heavy nodes packed with drives, compute-heavy nodes loaded with CPU and RAM, and classic hyperconverged nodes that balance both. A cluster running this mix spreads the cascade surface across different physical roles. When a same-batch cascade hits the storage-heavy nodes, the compute-heavy nodes keep running VMs uninterrupted. When a compute node fails, the storage nodes keep serving data. The same UCI flexibility that lets you scale compute and storage independently during normal operations also makes it structurally harder to lose a cluster to a single concentrated failure.
Two design consequences follow. The first is performance: the surviving drives never carry a rebuild storm, writes incur no parity recalculation tax, and the failed state holds production-level latency when the ioGuardian target runs on flash. The second is hardware flexibility. The ioGuardian server runs on its own license and its own hardware, and it does not need to match the production cluster in CPU family, generation, or media type. Customers run AMD ioGuardian targets behind Intel production environments, repurpose retired servers as ioGuardian capacity, and place a second ioGuardian instance at a cloud service provider for site-level resilience.
Key Terms
Telemetry Prevents Failure Before It Starts
The cascading drive failure scenario makes the architecture vivid. It also makes the point in the wrong direction. The goal is not to absorb the failure event. The goal is to never reach it. VergeOS does both. The replication model, ioGuardian, and live migration handle the moment of failure. The telemetry layer makes sure the moment rarely arrives.

The platform tracks seven SMART attributes on every drive in real time: total writes, power-on hours, reallocated sectors, wear leveling, ECC errors, end-to-end errors, and temperature. The data flows through a subscription model. A subscription is a rule that fires an alert on a defined condition.
The obvious subscription watches a wear-level threshold, and most customers set the first alert at seventy percent. The more useful subscription watches rate of change. An alert that fires when a drive’s wear level jumps ten points within ten days catches drives at risk of failure days or weeks ahead of any fixed threshold. The same rate-of-change subscription catches the early signature of a cascading drive failure before the second drive in a batch fails.
This capability turns refurbished procurement into a verifiable transaction. A reputable supplier delivers drives with a stated wear level and chain-of-custody record. The buyer installs them, runs a stress workload for twenty-four hours, and lets the platform watch. A drive that arrives at ninety percent wear when the supplier represented twenty percent gets flagged before any production data lands on it. The drive goes back, the supplier gets the call, and the framework has been validated by the platform itself. Refurbished media stops being a faith-based purchase and becomes a quantifiable one.
George Crump and Aaron Richman walk through the secondary-market case, the procurement framework, and the architectural model that makes refurbished enterprise drives a procurement decision rather than a courage test.
This is the two-sided coverage VergeOS delivers. The telemetry layer gives you everything you need to try to prevent the cascading drive failure from happening in the first place, through real-time SMART exposure, rate-of-change subscriptions, and verifiable supplier representations. If the cascade still arrives despite the early-warning systems, the architecture has the resiliency to withstand it, through synchronous replication, inline recovery, live migration, and heterogeneous UCI node distribution that keeps user workloads running through the failure. Both halves of the coverage matter. Most platforms leave the second half to you.
What This Means for Refurbished Procurement
The conventional argument against refurbished enterprise SSDs is elevated failure risk. The argument is correct. The platform decision is what changes the consequence of that risk. New media on a naive architecture faces a different set of stakes than refurbished media on a platform built to absorb cascading drive failure. Erasure coding controls protection at the cost of double-digit-hour rebuilds and a real chance that the next drive failure during rebuild ends the cluster. Synchronous replication, inline recovery, and live migration hold the cluster up regardless of failure cause or media age.
Stack the cost math on top of that architectural reality and the picture changes. Refurbished enterprise SSDs run forty to sixty percent below new pricing in the current market, a market whose underlying dynamics have been characterized as memory and flash prices that are not coming down. The reputable supply chain runs through R2v3-certified vendors who serialize inventory, perform NIST 800-88 sanitization, and stand behind their representations. Drives typically carry eighty to ninety-five percent of rated write life remaining. A buyer who runs SMART verification on intake, sets the rate-of-change subscription, and deploys behind RF2 with ioGuardian has answered the failure-risk question in three independent ways before any customer data lands.
Naive Architecture vs VergeOS for Cascading Drive Failure
| Naive Architecture | VergeOS | |
|---|---|---|
| Protection model | Erasure coding with parity calculation overhead | Synchronous replication with no parity overhead |
| Recovery on failure within tolerance | Multi-hour rebuild storm on surviving drives | Continuous serving with no rebuild |
| Recovery on failure beyond tolerance | Recover from backup, days of downtime | ioGuardian inline streaming, no service interruption |
| Compute response during cascade | VMs stop on affected nodes, manual restart required | Live migration moves VMs to surviving nodes automatically |
| Failure surface across node types | Symmetric nodes concentrate the cascade | UCI heterogeneous nodes spread the cascade across roles |
| Refurbished SSD verification | Manual intake test, no continuous monitoring | Seven SMART attributes monitored real-time, rate-of-change alerts |
The cascade is what makes the scenario memorable. The architecture absorbs cascading drive failure for the same reason it absorbs a same-batch firmware bug, a bad refurbished batch, or a single drive that happened to fail on a busy day. The failure cause is not the variable. The platform is. A companion post, How VergeOS Makes Refurbished SSDs Safe to Run, catalogs the platform’s response to each of the four supplier-side refurb risks.
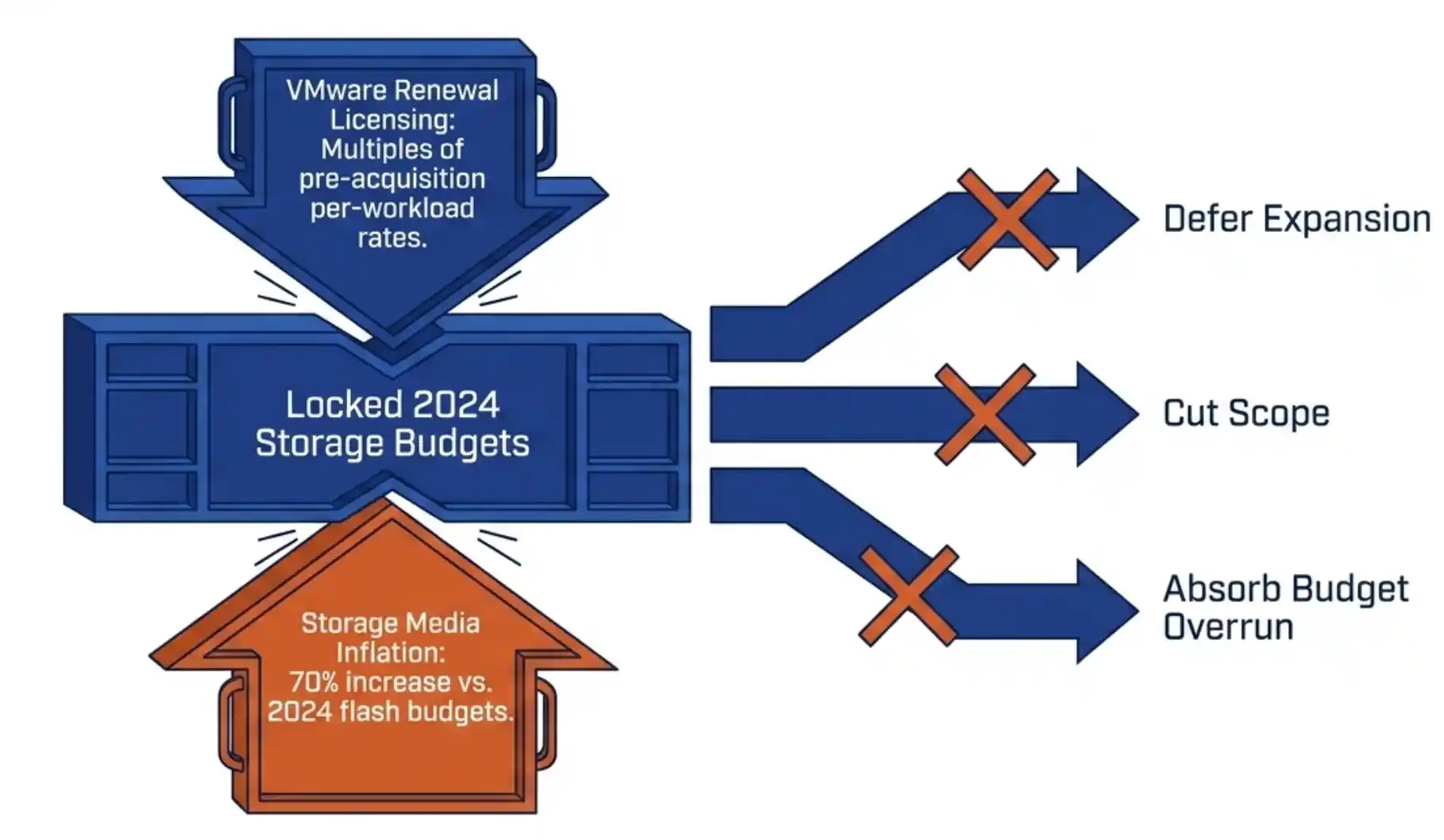 Your 2026 SAN refresh is in trouble. Flash inflation has pushed enterprise SSD prices up 70 percent. Refresh budgets locked in 2024 are now under-funded against current list pricing. The standard responses are to defer expansion, cut scope, or absorb the cost as a budget overrun. None of those options preserve the operational plan you set last year.
Your 2026 SAN refresh is in trouble. Flash inflation has pushed enterprise SSD prices up 70 percent. Refresh budgets locked in 2024 are now under-funded against current list pricing. The standard responses are to defer expansion, cut scope, or absorb the cost as a budget overrun. None of those options preserve the operational plan you set last year. Most infrastructure teams treat their SAN refresh and their hypervisor strategy as separate problems. The SAN refresh is a procurement decision, owned by storage architects. The VMware exit is a platform decision, owned by virtualization leads and the CIO. The two budgets land in different fiscal lines, the two evaluation cycles run on different clocks, and the two vendor conversations rarely overlap.
Most infrastructure teams treat their SAN refresh and their hypervisor strategy as separate problems. The SAN refresh is a procurement decision, owned by storage architects. The VMware exit is a platform decision, owned by virtualization leads and the CIO. The two budgets land in different fiscal lines, the two evaluation cycles run on different clocks, and the two vendor conversations rarely overlap.