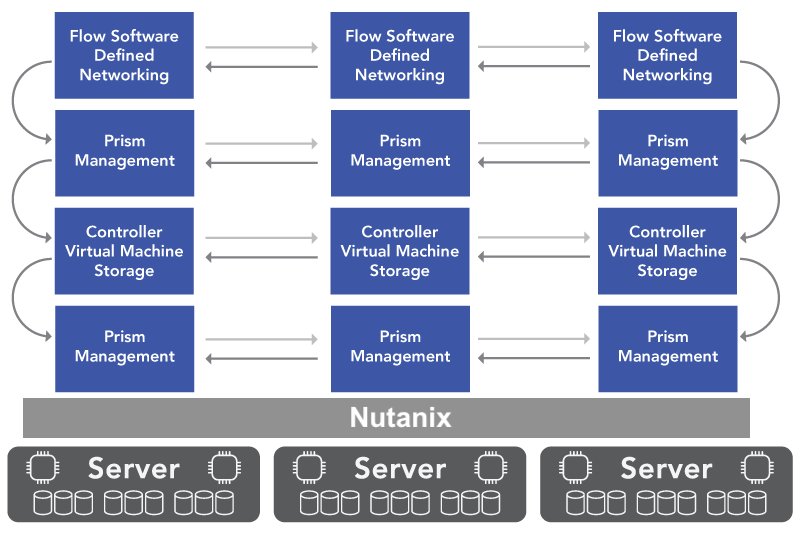
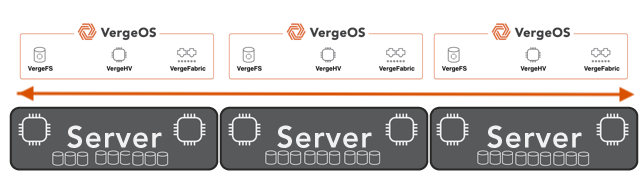
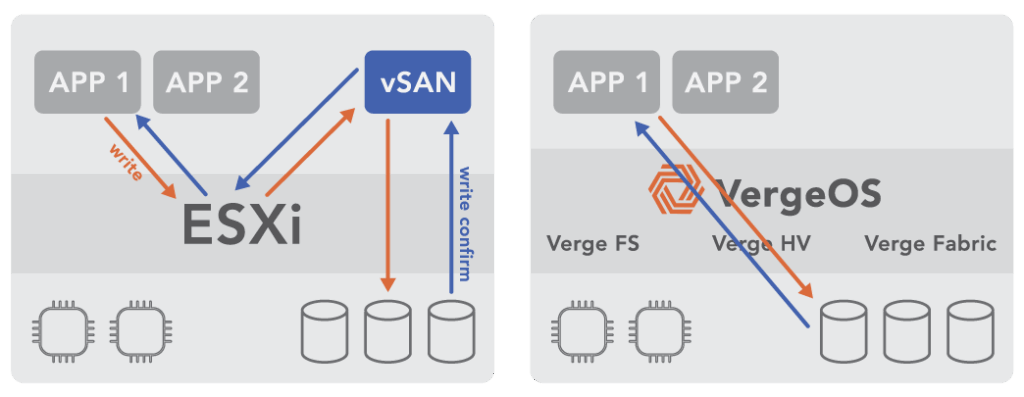
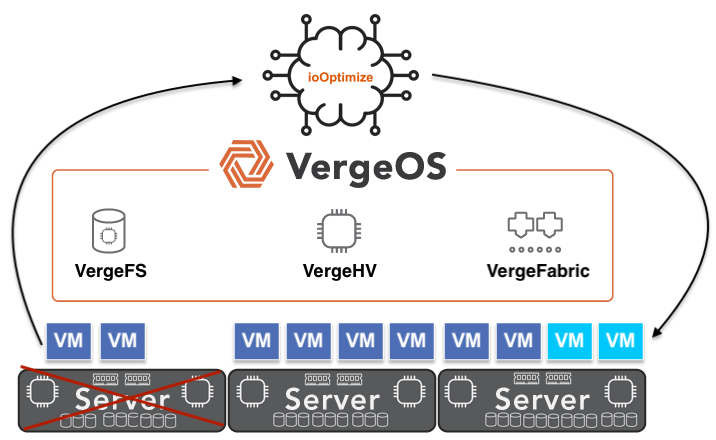
For most IT organizations, the VMware server upgrade conversation arrives at the same time as the renewal decision. Broadcom’s per-core subscriptions drove 300–500% VMware cost increases, turning a technology preference into a financial emergency. But migrations take time, and the working plan for many organizations has been sensible: renew for one more year, buy the servers needed to keep the environment running, and use that window to evaluate alternatives properly.
 That plan made sense in 2024. The renewal was expensive but predictable — Broadcom had only completed the acquisition a year earlier, many organizations still had time remaining on existing contracts, and buying one more year to evaluate alternatives was a reasonable call. The servers were a known quantity. The budget math was uncomfortable but manageable. What changed is not the plan — it is the price of executing it. The two line items that seemed controllable have both moved against you at the same time, and the combined number no longer looks like buying time. It looks like paying a premium to stay on a platform you have already decided to leave.
That plan made sense in 2024. The renewal was expensive but predictable — Broadcom had only completed the acquisition a year earlier, many organizations still had time remaining on existing contracts, and buying one more year to evaluate alternatives was a reasonable call. The servers were a known quantity. The budget math was uncomfortable but manageable. What changed is not the plan — it is the price of executing it. The two line items that seemed controllable have both moved against you at the same time, and the combined number no longer looks like buying time. It looks like paying a premium to stay on a platform you have already decided to leave.
Key Takeaways
Why VMware Server Upgrade Costs Have Changed
 The server market shifted in late 2024 and has not corrected. DRAM contract prices rose 58–63% quarter over quarter in the first half of 2026, driven by AI infrastructure buildout at the hyperscaler level that locked up supply before enterprise buyers could compete. This cycle has been characterized as a Memory and Flash Supercycle — a structural market shift projected to persist well beyond 2027, not a temporary correction. Server-grade DDR5 RDIMMs are on track to double year over year by late 2026. Memory now represents 35% of total server BOM cost, a line item that used to be dominated by processors.
The server market shifted in late 2024 and has not corrected. DRAM contract prices rose 58–63% quarter over quarter in the first half of 2026, driven by AI infrastructure buildout at the hyperscaler level that locked up supply before enterprise buyers could compete. This cycle has been characterized as a Memory and Flash Supercycle — a structural market shift projected to persist well beyond 2027, not a temporary correction. Server-grade DDR5 RDIMMs are on track to double year over year by late 2026. Memory now represents 35% of total server BOM cost, a line item that used to be dominated by processors.
Enterprise SSD pricing compounded the problem. A 30TB TLC enterprise SSD that cost $3,062 in mid-2025 now costs nearly $11,000 — a 257% increase in under a year. For organizations that planned a server refresh at 2024 pricing, the storage bill alone can flip a manageable capital project into a budget conversation that goes back to the CFO. And unlike the licensing increase, which arrived as a known policy change, the hardware inflation arrived quietly — embedded in quotes that came back higher than expected, with OEM validity windows shrinking from thirty days to fifteen. The price you get today expires before your purchase order clears.
Key Terms
Broadcom’s VMware licensing model that charges based on the number of processor cores in use, replacing perpetual licenses. Drove 300–500% cost increases for most organizations after the acquisition closed.
Registered Dual In-Line Memory Module using the DDR5 standard — the server-grade RAM required by modern virtualization hosts. Contract prices are on track to double year over year by late 2026, driven by AI infrastructure demand at the hyperscaler level.
The itemized cost breakdown of all components in a server build. Memory now represents 35% of total server BOM cost in 2026 — the largest single line item, a position historically held by processors.
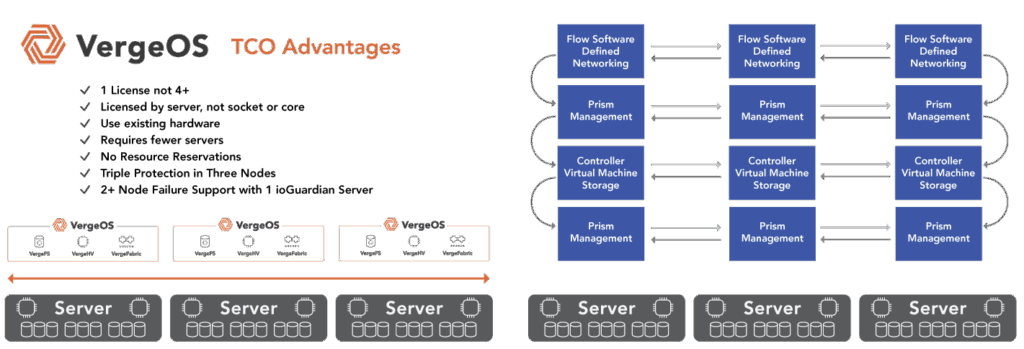
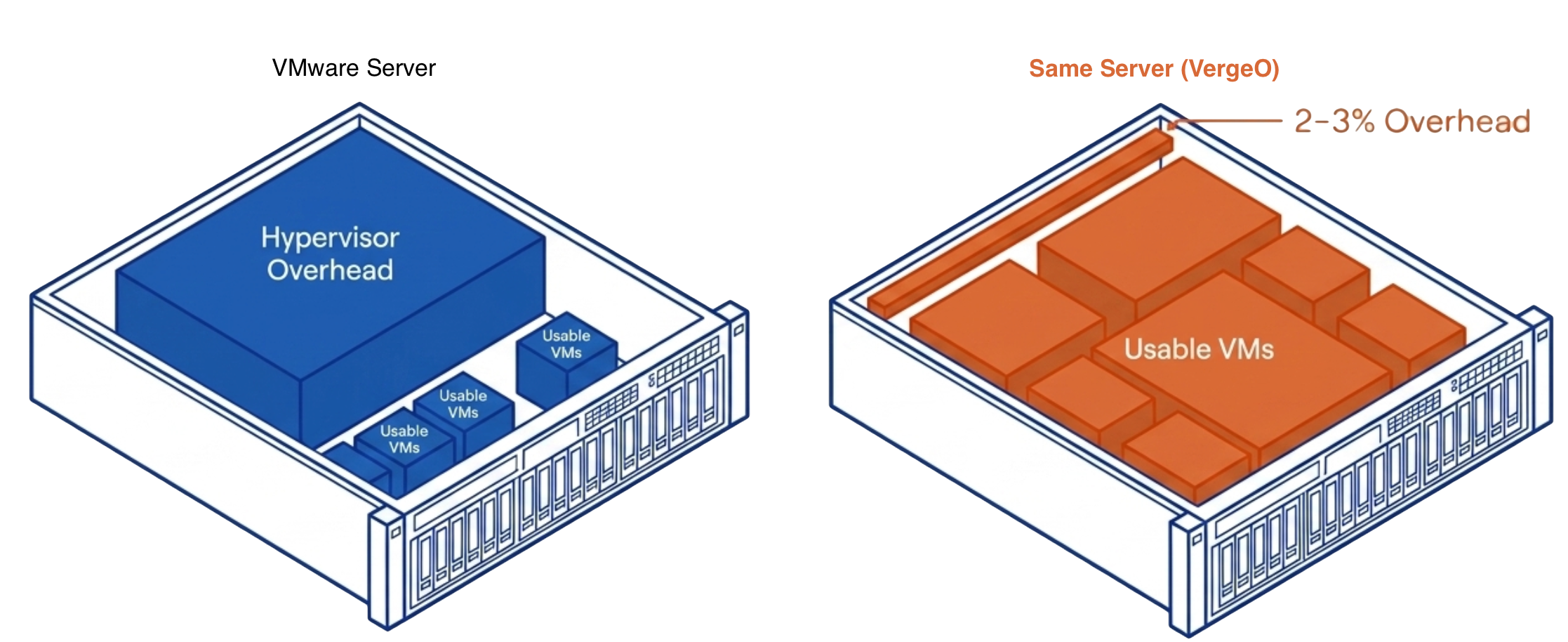
The memory and compute resources consumed by the hypervisor stack itself before any workload runs. VMware runs at double-digit percentages. VergeOS runs at 2–3%, returning the difference to productive workloads on the same physical hardware.
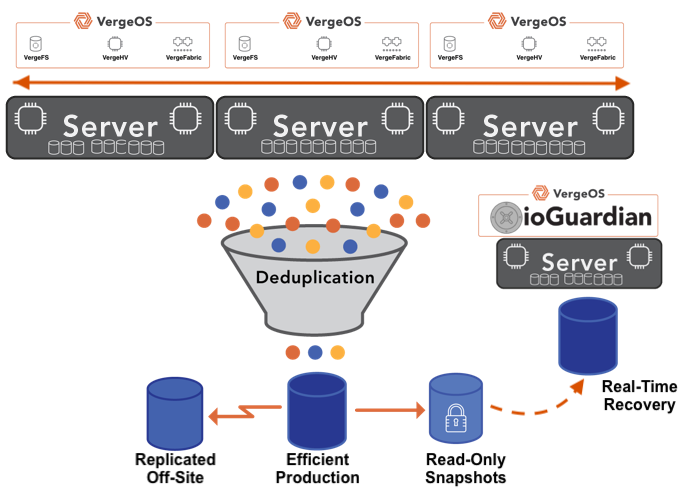
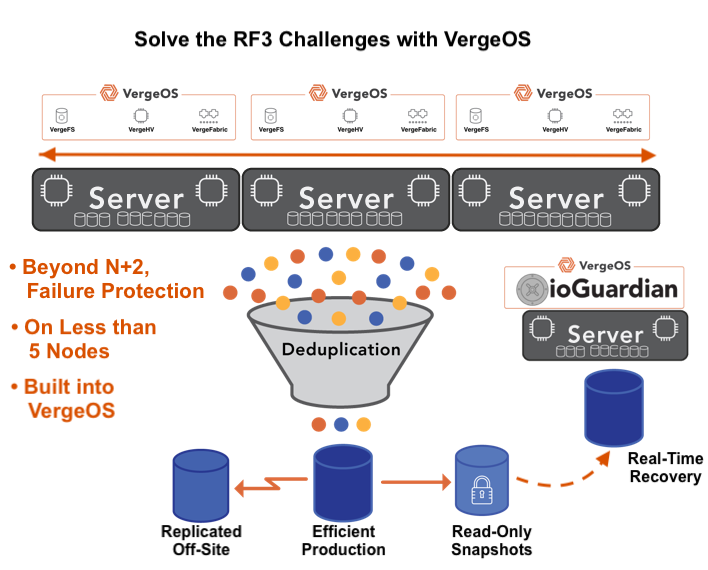
VergeOS’s storage architecture that holds only unique data blocks across all VMs and all nodes, delivering significantly more effective capacity from the storage organizations already own.
The Compounding Trap
Here is where the two costs stop being separate line items. The Broadcom per-core subscription is running at elevated rates with annual escalation baked in. The servers are running at elevated prices with no correction in sight.
George Crump and Mike Matchett unpack the full cost equation — the hardware ambush, the license squeeze, and why VergeOS changes the math. Live Q&A included.
Register Now →The budget that was approved to buy evaluation time is now funding a premium VMware environment on hardware that costs twice what the CFO expected when the plan was signed off. Neither purchase is optional — the environment needs to keep running, and the servers are needed to run it. The combined spend is no longer a bridge to a better decision. It is the cost of not having made the decision sooner.
The compounding works against you in a third way that rarely appears in the analysis. Every month inside that one-year extension is a month the organization is not migrating. Server lead times of three to six months mean that even if the decision to exit comes at month four of the extension, hardware ordered then may not arrive until the extension is nearly over — triggering a second renewal conversation before the first one has paid off. The organization that bought time to evaluate alternatives ends up buying time to buy more time. Each cycle runs at current pricing.
The VMware Exit That Costs Less Than the Renewal
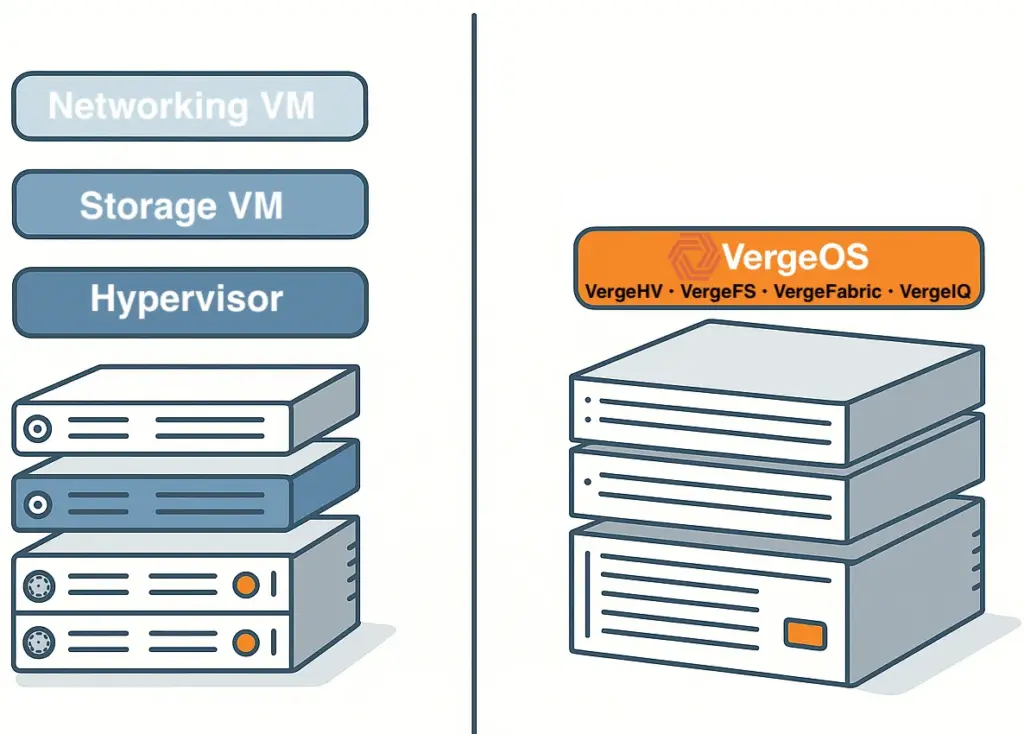
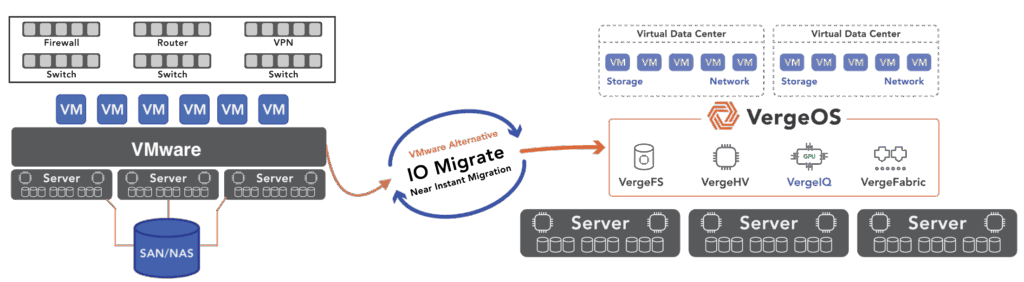
 VergeOS changes the math at every layer where the conventional path breaks down. The starting point is hardware: VergeOS installs on any x86 server already in the data center. The servers the organization was planning to buy are no longer required. The $40,000 nodes, the three-to-six-month lead times, the OEM quote that expires before the purchase order clears — none of that applies. The migration starts on the day the organization decides to move, on hardware already powered on and already running workloads.
VergeOS changes the math at every layer where the conventional path breaks down. The starting point is hardware: VergeOS installs on any x86 server already in the data center. The servers the organization was planning to buy are no longer required. The $40,000 nodes, the three-to-six-month lead times, the OEM quote that expires before the purchase order clears — none of that applies. The migration starts on the day the organization decides to move, on hardware already powered on and already running workloads.
The VMware subscription disappears on day one. That eliminates the compounding trap — there is no renewal to sign, no escalation clause to absorb, and no ongoing Broadcom billing cycle running while the migration proceeds. For an organization paying $30,000 per month in VMware subscription fees, eliminating even six months of that cost covers a significant portion of the migration project itself.
VergeOS does more than start the migration on existing hardware — it makes that hardware perform better than it did under VMware. The entire VergeOS stack runs at 2–3% memory overhead versus double-digit percentages for VMware. That overhead gap translates directly into workload capacity: the same physical servers run more VMs, with more memory available to the workloads that matter. VergeOS storage is globally deduplicated across all VMs and all nodes, which means the flash capacity the organization already owns works significantly harder. Customers consistently find greater storage efficiencies through VergeOS deduplication than they achieved on VMware — the same drives, more effective capacity. The servers that were already paid for become better servers on the day the migration completes.
Make the Decision You Have Already Made
The VMware exit is not a question most IT organizations are still debating. The question is when, and how much the delay costs. Every month inside a renewed VMware contract is a month of Broadcom billing at elevated per-core rates. Every month that passes is another month closer to needing those servers — at whatever price they quote when the order finally goes in.
The organizations finishing their VMware exits in 2026 are not the ones that found a better renewal deal or waited for server prices to correct. They are the ones that recognized the exit itself was the lower-cost option — and that VergeOS made it possible to start on hardware already in the data center, eliminate the subscription on day one, and come out the other side running more workloads on less memory than VMware ever delivered. The math on staying has never been worse. The math on leaving has never been more in favor of moving now.
Renewing VMware vs. Migrating to VergeOS: The 2026 Cost Comparison
| Renew VMware + Buy Servers | Migrate to VergeOS | |
|---|---|---|
| Hardware cost | $40K nodes at peak pricing — when available | Start on existing hardware today |
| Server lead time | 3–6 months before migration can begin | Zero — migration starts immediately |
| VMware subscription | Full renewal at elevated per-core rate | Eliminated on day one |
| Annual escalation | Baked into new contract term | Gone entirely |
| RAM utilization | Double-digit platform overhead unchanged | 2–3% overhead — more workloads, same servers |
| Storage efficiency | No change from existing VMware environment | Global deduplication — existing drives work harder |
| Migration timeline | Starts after hardware arrives | Starts the day the decision is made |
Join George Crump and Mike Matchett on April 30 for The New Economics of VMware Exit — a live TruthInIT webinar unpacking the full cost equation and the path forward. Register for the webinar.
For the complete TCO model and four-step business case, download the white paper: The New Economics of the VMware Exit.
Ready to see VergeOS running on your existing infrastructure? Take a Test Drive Today.