The Hidden Costs of HCI
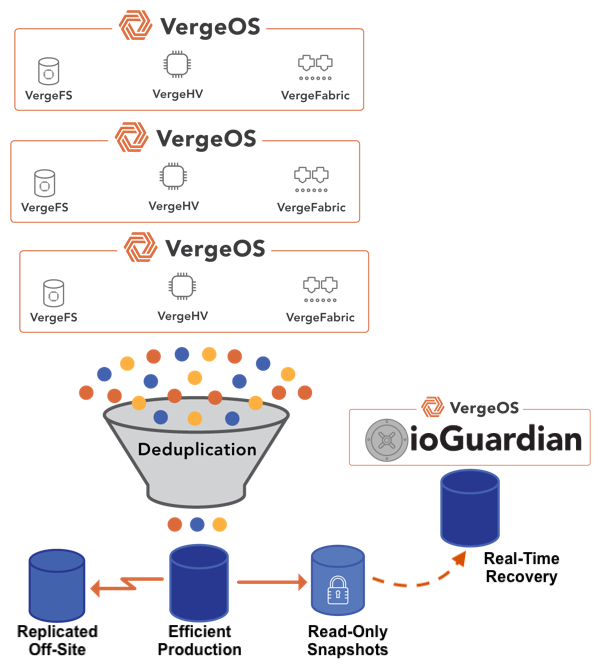
Hyperconverged Infrastructure (HCI) promises simplified management but hides substantial costs and complexities. Traditional HCI architectures impose high hardware requirements, inefficiencies, and restrictive availability models. This article explores these hidden costs, offering a detailed comparison with alternative solutions designed to improve efficiency, reduce complexity, and substantially lower infrastructure expenses and risks.