During our “InBrief” Event with Truth In IT, one of the most frequently asked questions was about VMware scale comparisons. This series of questions moved beyond the more general Comparing VMware to VergeOS and focused specifically on how VergeOS handles the demands of scale compared to VMware.
To learn more about VergeOS’ scaling capabilities, watch our on-demand webinar “How to Eliminate the Data Center Scale Problem.”
Understanding VMware Scale Methods
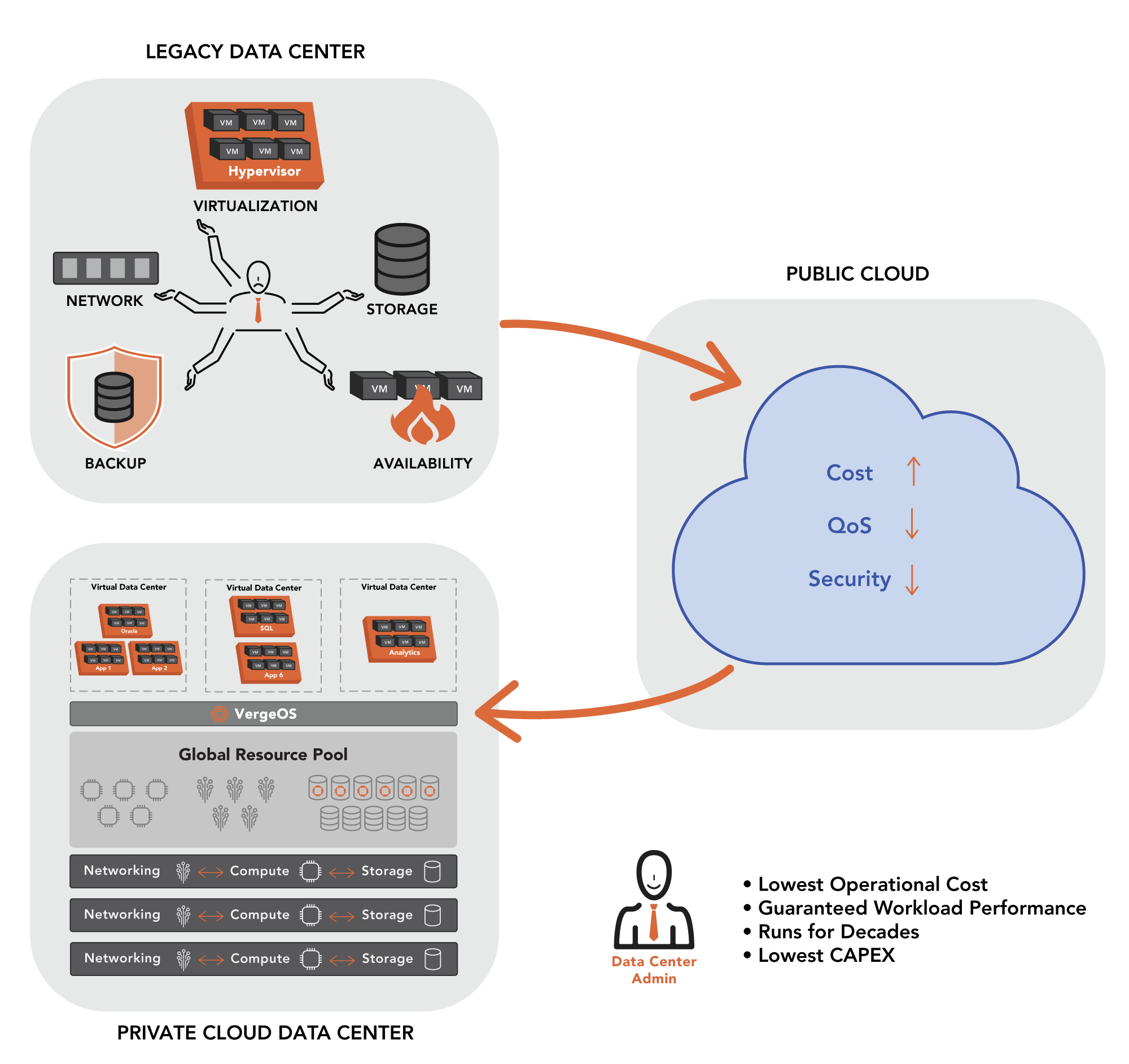
Before making any VMware scale comparisons, you must understand its scaling methodology. How VMware scales depends mainly on the infrastructure on which it resides. Most VMware environments use the classic three-tier architecture with physical network switches, servers, and a separate storage system. Most organizations have one primary switch and server vendor, although a few alternate brands may be in use. However, the storage tier, especially as the environment scales, typically has multiple storage systems for different virtual machine (VM) types or use cases.
A less popular alternative is the classic hyperconverged infrastructure (HCI) which loads software-defined networking (SDN) and software-defined storage (SDS) software onto the same nodes as VMware ESXi. In most cases, the SDN and SDS software run as VMs and are subject to ESXi capabilities. As a result, the organization still has a three-tier architecture. It is just that those tiers are now logical instead of physical. This logical representation of the three-tier architecture is why the classic three-tier architecture remains so prevalent.
These two infrastructures impact the scalability of VMware. VMware claims to support 96 nodes per ESXi cluster in the classic three-tier architecture, but only 64 nodes within its HCI cluster because of limitations within the vSAN cluster.
Understanding VergeOS Scale Methods
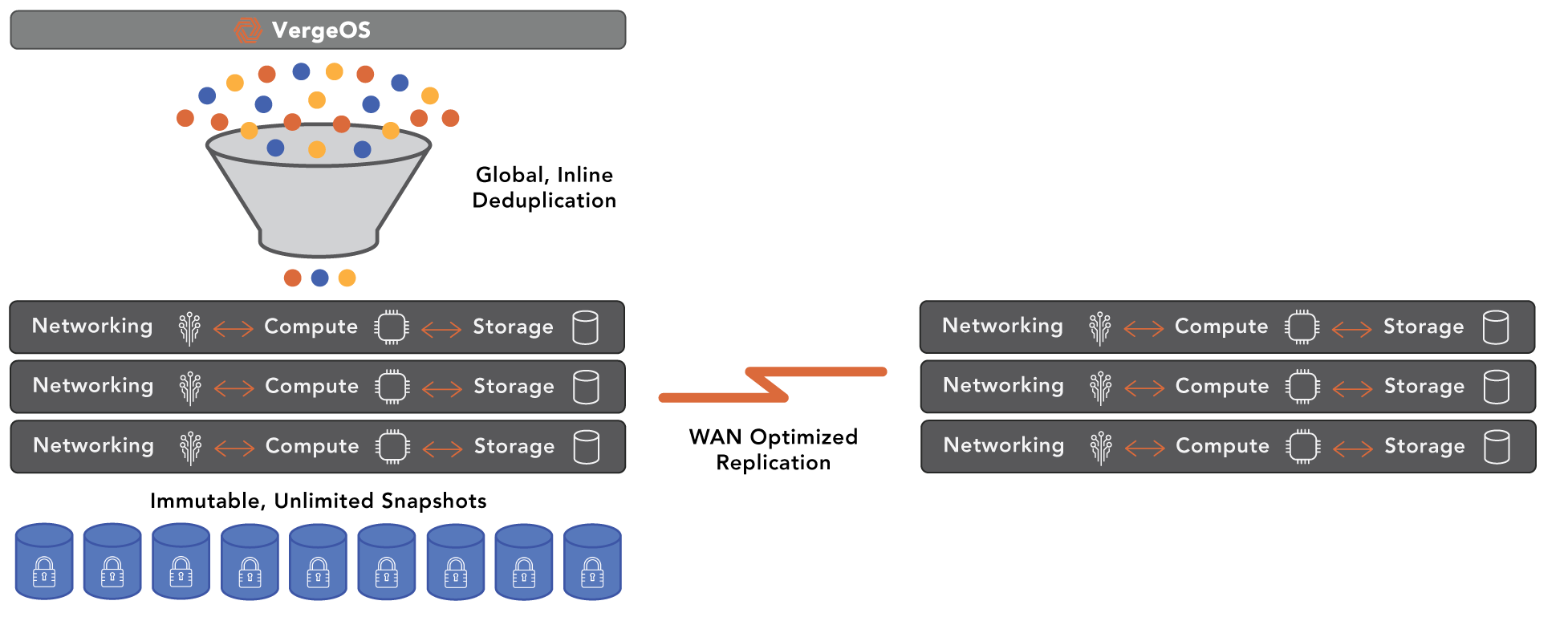
VergeOS is an ultraconverged infrastructure (UCI). Similar to HCI, it does not use an external storage array. Unlike HCI’s use of separate SDN and SDS software inside the hypervisor, UCI integrates the networking and storage functionality into the hypervisor. This critical difference significantly improves the ability to scale the infrastructure, especially when you compare UCI to HCI. There is no technical limit on the number of nodes VergeOS support, and there is no case of “diminishing returns” as you scale. We have customers in production with over 60 active nodes in a single VergeOS instance.
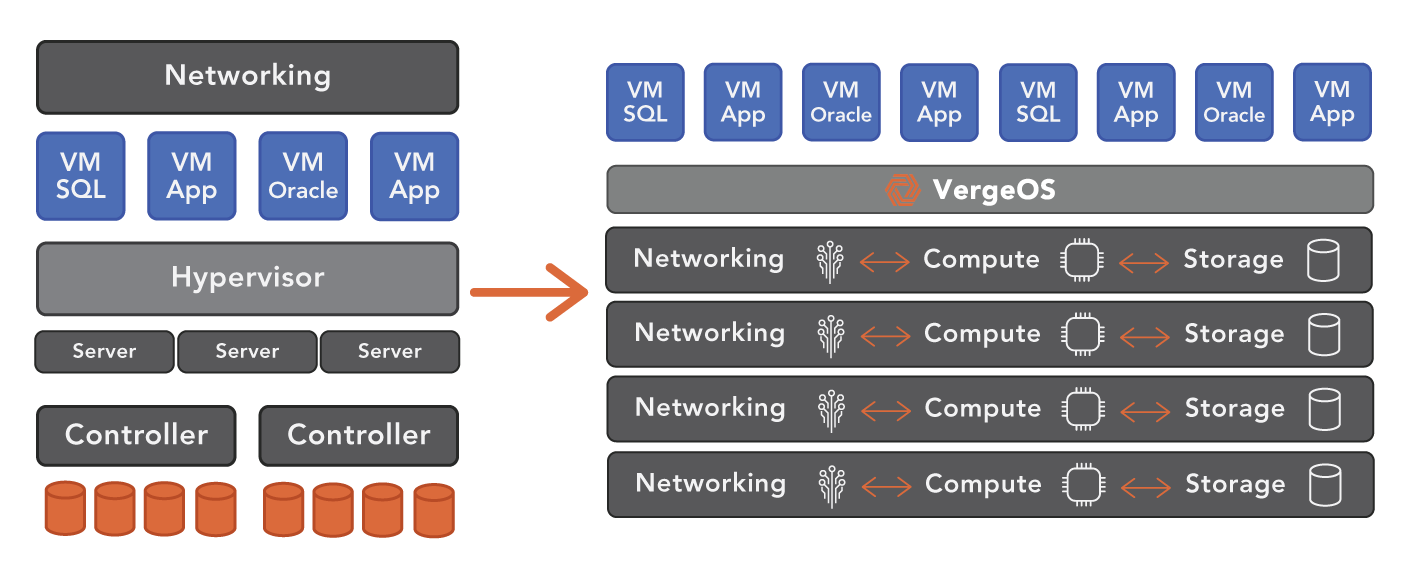
Subscribe to our Digital Learning Guide (DLG), “Understanding the VergeOS Architecture,” for a deep dive into our ultraconverged infrastructure. Our DLGs are white papers delivered in weekly bite-sized chunks.
Comparing VergeOS to VMware Scale
When making VMware scale comparisons, there are two aspects to remember. First, what are the technical limitations of scalability, and second, what are the ramifications of scaling the cluster on resource utilization and organizational flexibility?
VergeOS’ Technical Scale is Better Than VMware Scale
VergeOS is superior in raw node count versus VMware, enabling large enterprises to meet even the most demanding processing and storage performance requirements. Again, we have production customers with over 60 nodes, hundreds of virtual data centers, and thousands of virtual machines. These customers have been running VergeOS at this level of scale for years. VergeOS customers also don’t need to worry about scaling complexity. With VergeOS, there is only one software package, not three or more.
VergeOS’ Efficient Scale is Better Than VMware Scale
VMware scale comparisons to VergeOS should also include how efficiently the infrastructure scales. While raw node count may be critical for some data centers, most organizations seek more efficiency and flexibility in how the VMware alternative scales. Efficient scale means only adding additional nodes after the existing nodes’ resources have been used to their full potential. An efficient infrastructure can deliver more performance from fewer nodes, which lowers both capital and operational costs.
The comparison of efficient scale is where VergeOS has a clear and more practical advantage. We repeatedly have VMware customers moving to our platform and are seeing better performance from their applications even though it runs on the same hardware. The lack of efficiency is why many customers who originally consider HCI end up selecting a classic three-tier architecture. UCI delivers the efficiency they need.
As a result, customers can add even more workloads to the environment without purchasing additional hardware. In some cases, they have been able to delay new server purchases for years, thanks to the implementation of VergeOS. The efficiency results from integrating the networking and storage components and, frankly, just better execution of the code. Our efficiency means that while customers can scale further with VergeOS, they won’t have to scale as often.
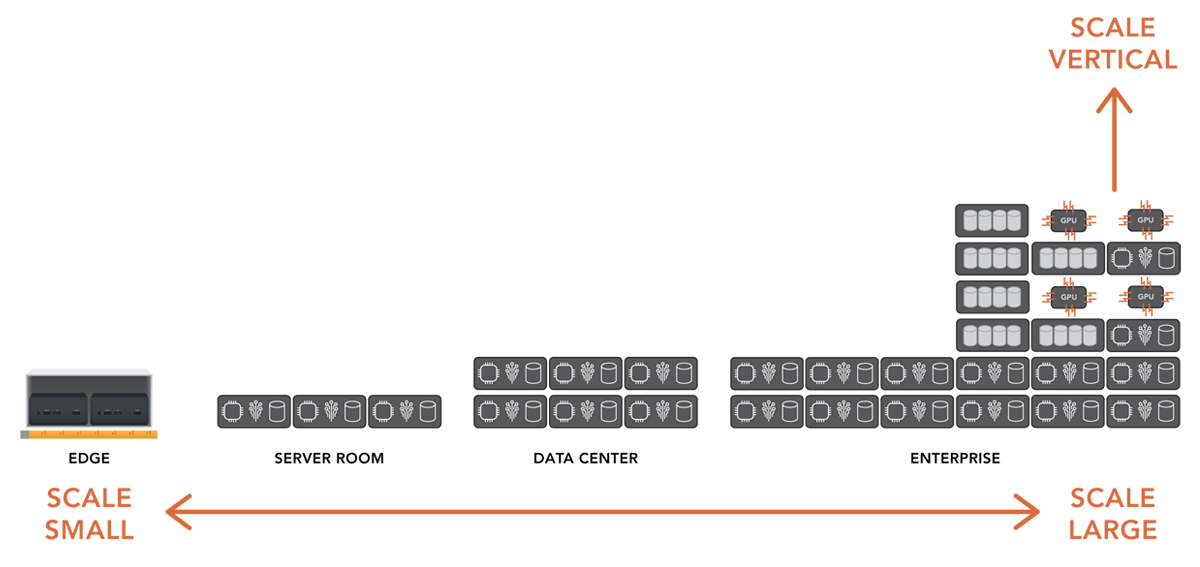
VergeOS’ Flexible Scale is Better Than VMware Scale
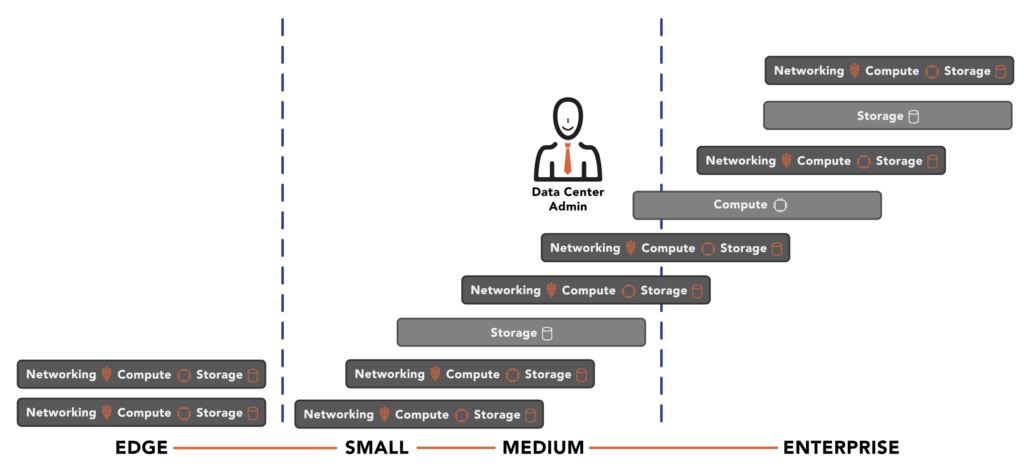
VMware scale comparisons to VergeOS must also include how flexible it is to scale the cluster. Most customers will want to start small and add nodes as workloads and organizational growth demand it. Instead, most customers will grow their environment over time. During that time, their needs will change, and so will technology. The first dozen or so nodes they start with may only be available after the time they add their fiftieth node.
With VMware, you must create an entirely separate cluster if you add different servers with different configurations, like an AMD processor instead of an Intel processor. While there is a common management interface, plenty of functions need to be set separately. HCI Storage is a good example. It is locked to the cluster and can’t be shared across clusters.
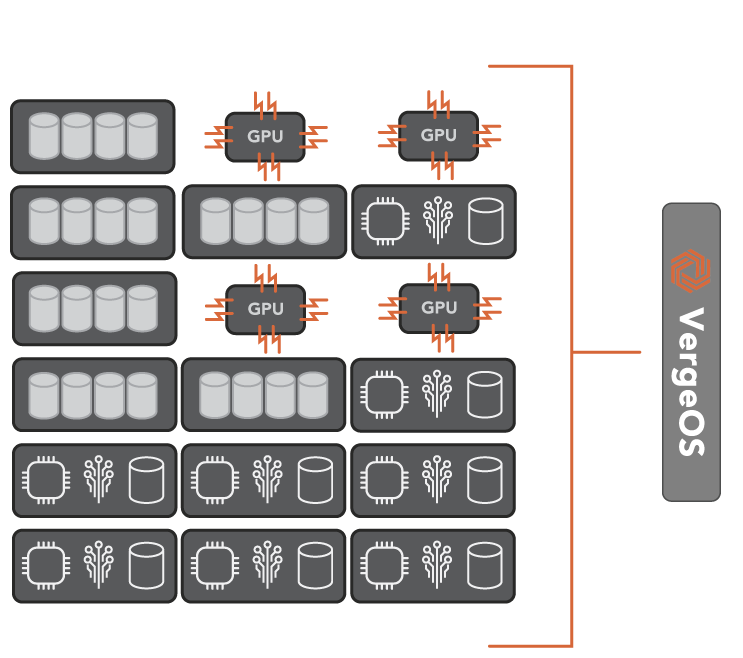
With VergeOS, IT can bring in servers of vastly different configurations, different processors, different storage media types, and even with GPUs. They are all managed by a single VergeOS environment. Resources can be isolated to a single virtual data center or distributed across multiple virtual data centers.
VergeOS’ flexibility means that the software can adapt to the organization’s needs and integrate new hardware innovations. IT can use VergeOS for mainstream applications with modest performance requirements, then add high-performance nodes with GPUs and NVMe flash or high-capacity nodes for file sharing and backup. Each of these different hardware configuration types is still managed within the same VergeOS instance.
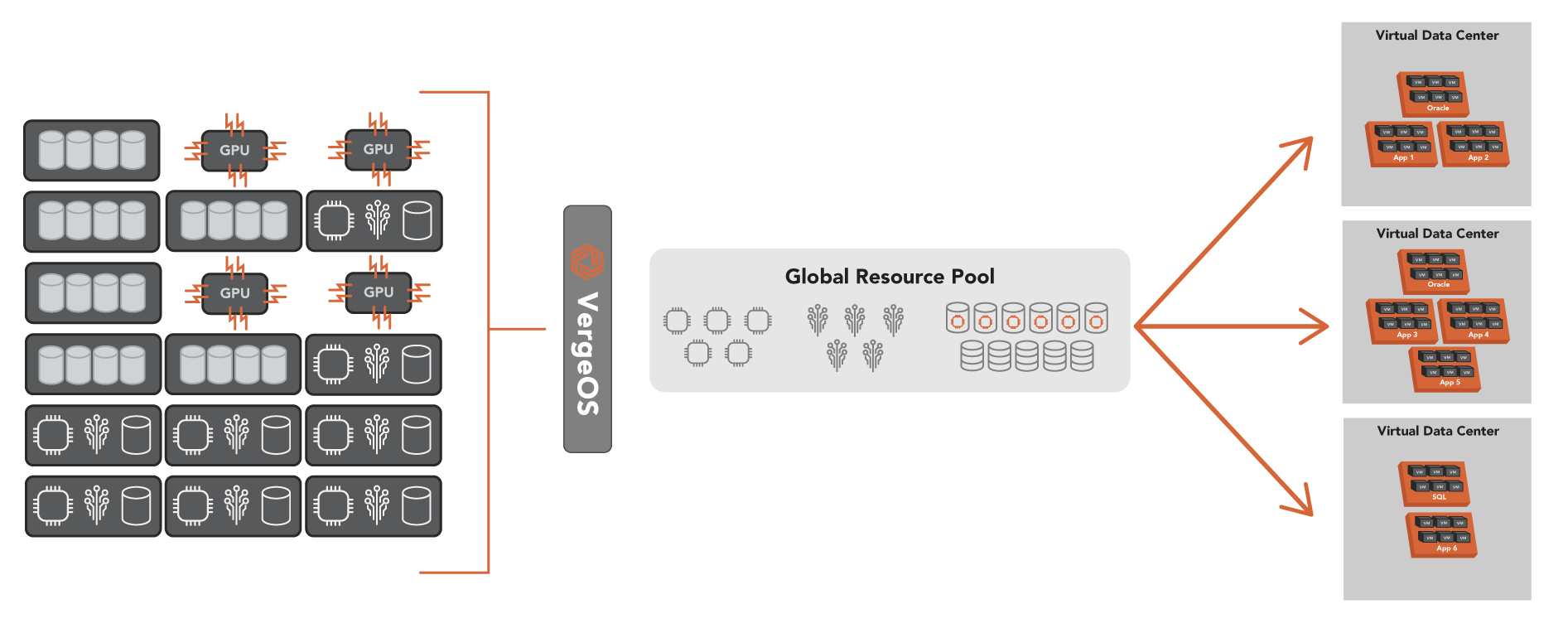
Conclusion
VMware scale comparisons to VergeOS will show how superior VergeOS is in all the ways IT measures scalability. It is affordable for small data centers and enables them to deliver more performance on less hardware while also providing robust networking functionality. Enterprises can support various workloads thanks to VergeOS’ ability to mix nodes and use Virtual Data Centers. There is no technical limit on how many nodes, VergeOS supports, but its efficiency means you will require less than VMware.
It is also important to remember that VergeOS is a complete offering and requires no compromises versus VMware. It provides robust data protection, massive capacity scalability, and almost bare-metal performance of virtualized applications. VergeOS’ storage capabilities are so powerful that many customers switch to VergeOS as part of a SAN replacement project.