Extending server longevity requires more than maintaining software compatibility, yet most virtualization and infrastructure software vendors don’t offer even that. Instead, they end hardware support after 4 or 5 years, long before the server has outlived its usefulness. This short timeline reflects how quickly software requirements outpace the systems they run on, not hardware failure or performance degradation. The result is a predictable refresh cycle that replaces hardware long before its physical limits are reached.
Compatibility alone does not keep older servers productive. Running software on legacy hardware is not the same as running it well. Performance declines with every new release. Component wear translates directly into downtime risk.
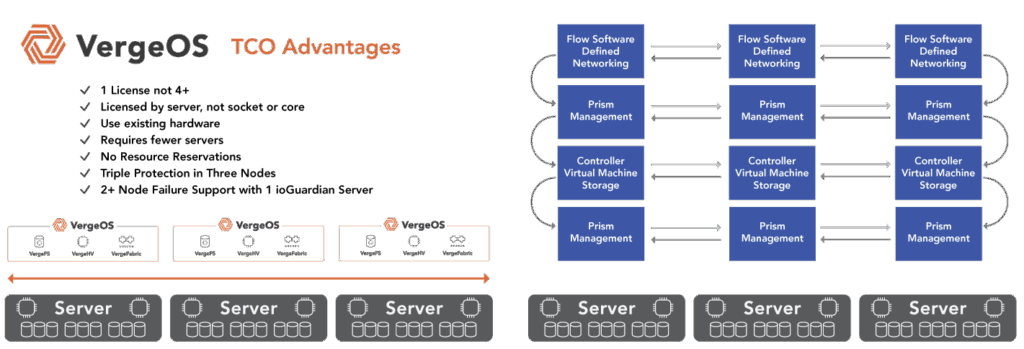
Extending server longevity demands infrastructure software that runs efficiently on existing hardware, delivering consistent performance without additional resources. It also requires protection that keeps applications and data available as servers age. VergeOS was built on that principle.
Why Vendors Don’t Prioritize Extending Server Longevity
Most virtualization and infrastructure platforms are not designed with extending server longevity as a core goal. Their architecture and development model make it difficult to maintain performance and reliability as hardware ages. Over time, this leads to the familiar four- to five-year refresh cycle that defines enterprise IT planning.

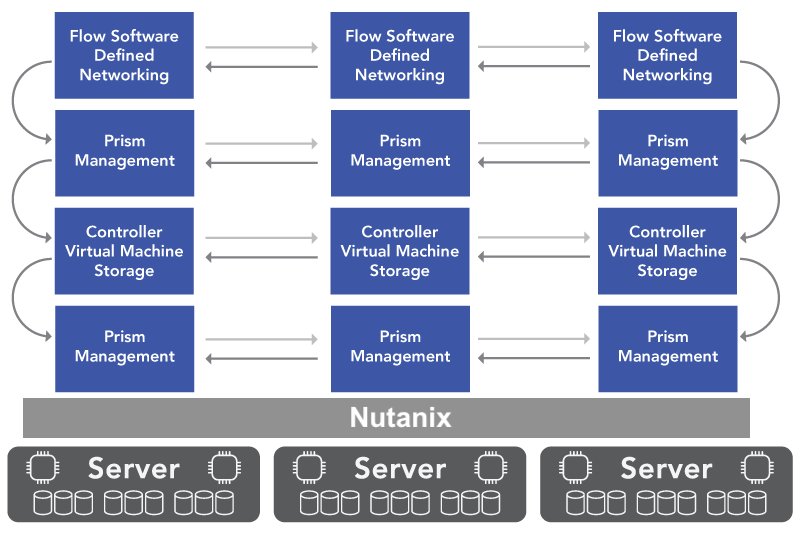
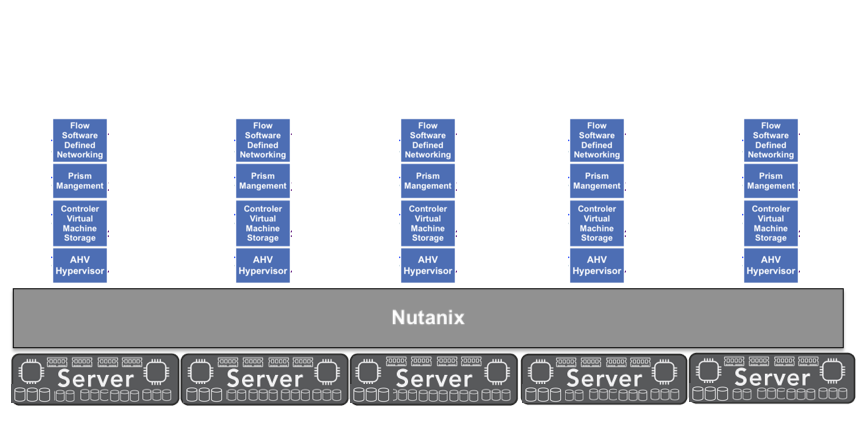
Traditional virtualization software is built from multiple independent layers: a hypervisor, a virtual storage engine, a network virtualization component, and a management framework. Each layer consumes CPU cycles, memory, and I/O bandwidth. Vendors add new features by introducing additional modules that must interact with the existing management layer and hypervisor. Each module introduces its own background services and control processes. With every update, the total resource requirement grows.
The hardware does not inherently become obsolete. The software demands more. A version upgrade that improves functionality also increases CPU utilization and memory consumption. What begins as a minor performance reduction compounds over time until older servers cannot keep up. Replacement becomes the practical response.
This pattern does not stem from neglect or deliberate obsolescence. It is the natural outcome of building large, modular software that continues to expand. Features accumulate, interdependencies multiply, and the software relies on newer hardware generations to maintain responsiveness. The model favors innovation speed and feature breadth at the expense of long-term hardware usability.
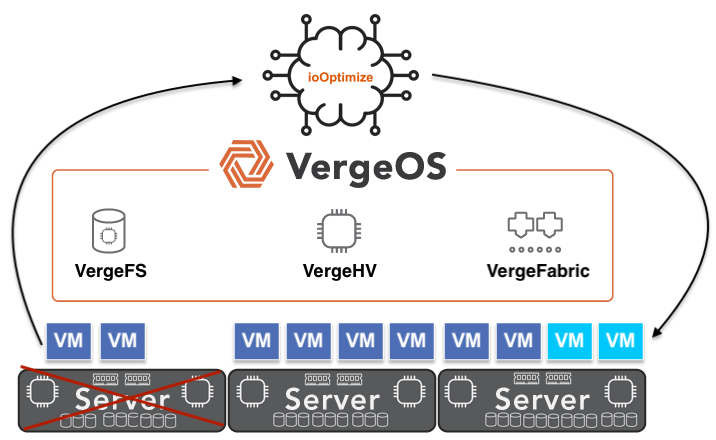
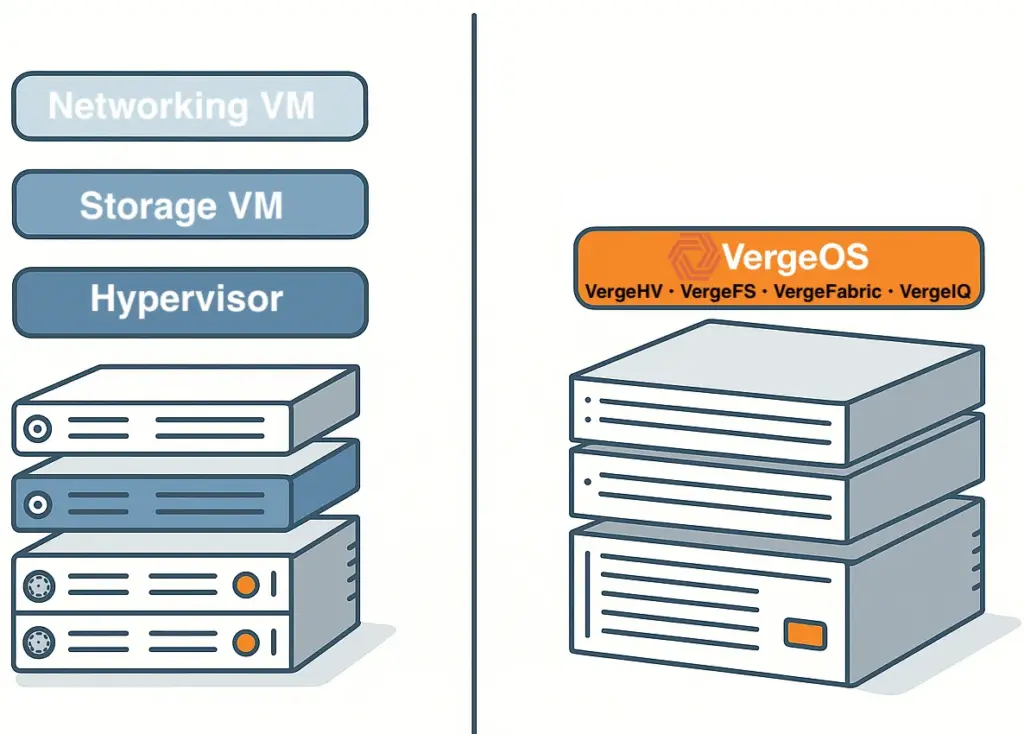
VergeOS approaches infrastructure differently. By integrating compute, storage, and networking into a single codebase, the platform eliminates redundant modules and interprocess communication that drain resources in traditional architectures. New features are built directly into the existing framework, maintaining performance instead of eroding it.
Servers continue to perform well, stay reliable, and remain part of the production environment long after other platforms declare them outdated.
Extracting Modern Performance from Existing Hardware
Extending server longevity depends as much on software design as it does on hardware reliability. The physical systems inside a data center have far more capability than the software running on them fully uses. The limiting factor isn’t the hardware. It’s the architectural overhead introduced by complex, multi-layer virtualization stacks.
Each software layer adds its own control processes, scheduling mechanisms, and data translation routines. Over time, these layers stack up like filters, each one slowing the flow of compute and I/O. Hardware performance appears to decline when the underlying components are perfectly capable. The system is working harder to do the same amount of work.
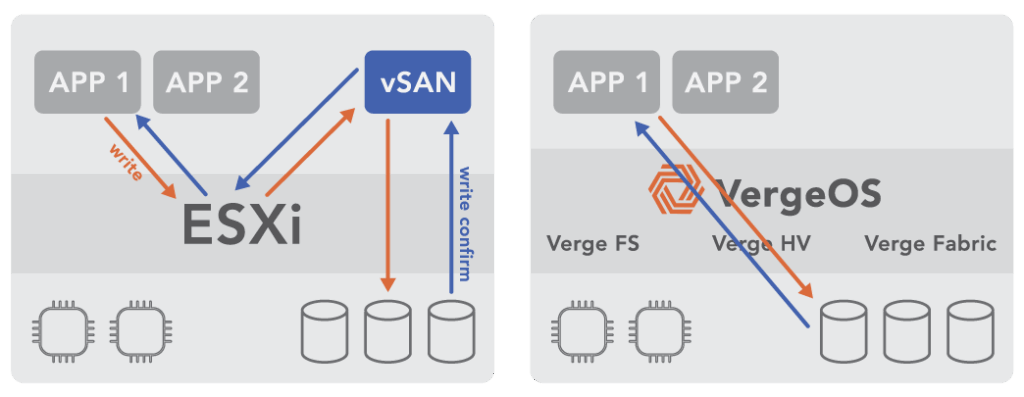
VergeOS runs compute, storage, networking, and AI in a single, unified code base. There are no redundant services or handoffs between independent modules. Every operation travels the shortest possible path through the system. This design reduces CPU utilization, shortens I/O latency, and improves cache efficiency.
The platform restores balance between what hardware does and what the software allows it to do. By removing unnecessary translation layers, older servers run workloads at modern performance levels. Environments that once struggled with overhead-heavy hypervisors see measurable performance improvements simply by switching to a unified infrastructure model.
VergeOS customers exiting VMware report not only continuing to use their existing servers but also repurposing systems that VMware had already deprecated. These customers keep servers in production for eight to ten years, well beyond the typical refresh cycle, maintaining consistent performance and reliability.
Artificial Intelligence as an Example

Most vendors are adding AI as a set of external modules that sit on top of their existing stack. Each new layer brings its own management and resource overhead, increasing complexity and accelerating hardware refresh cycles.
VergeOS integrates AI directly. It includes AI as a service, built into the infrastructure operating system. The feature appears and activates with a toggle: no new layers, no extra configuration, and no performance penalty. Older servers contribute to AI initiatives by hosting GPUs or supporting complementary workloads. This design keeps infrastructure simple and extends the usefulness of servers into the AI era.
Overcoming Hardware Aging Through Software Design
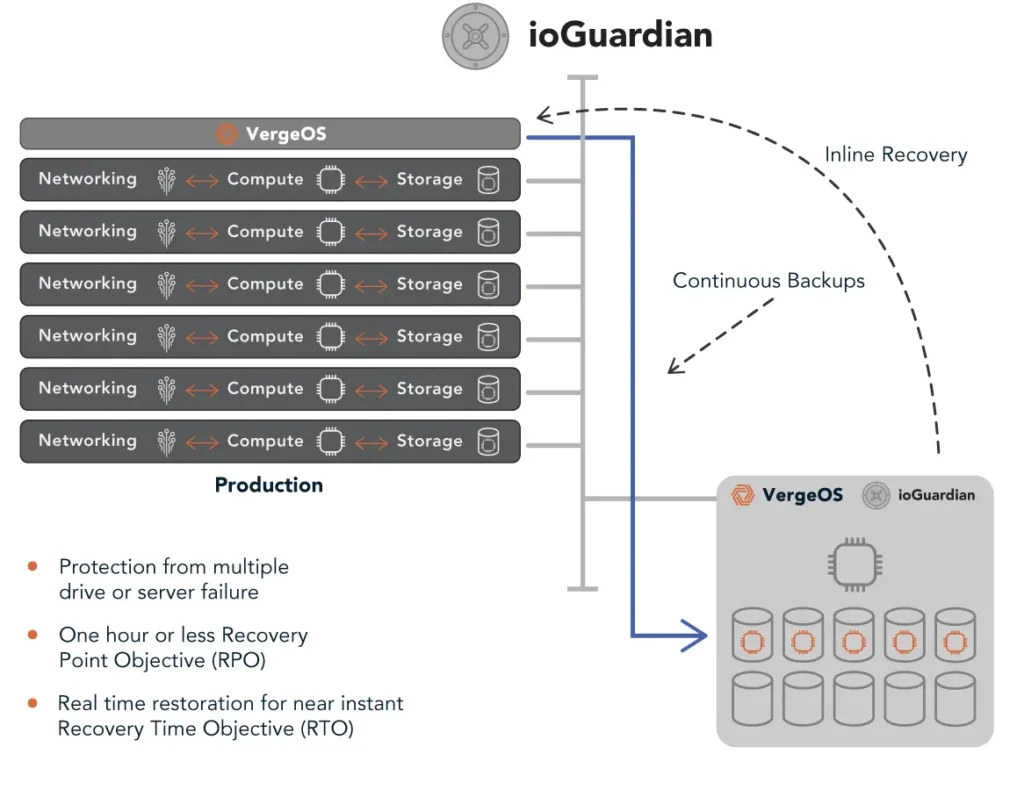
Fans, power supplies, and storage devices wear out over time. Traditional virtualization platforms treat these events as interruptions, forcing downtime for replacement or triggering complex failover procedures that require external tools. VergeOS treats protection as an inherent part of its design, not a separate feature.
The platform continuously monitors every system component, watching for early indicators of degradation: rising temperatures, increased I/O latency, or power fluctuations. When it detects a potential issue, it alerts administrators long before the problem becomes critical. Maintenance happens during normal operations rather than during an emergency outage.
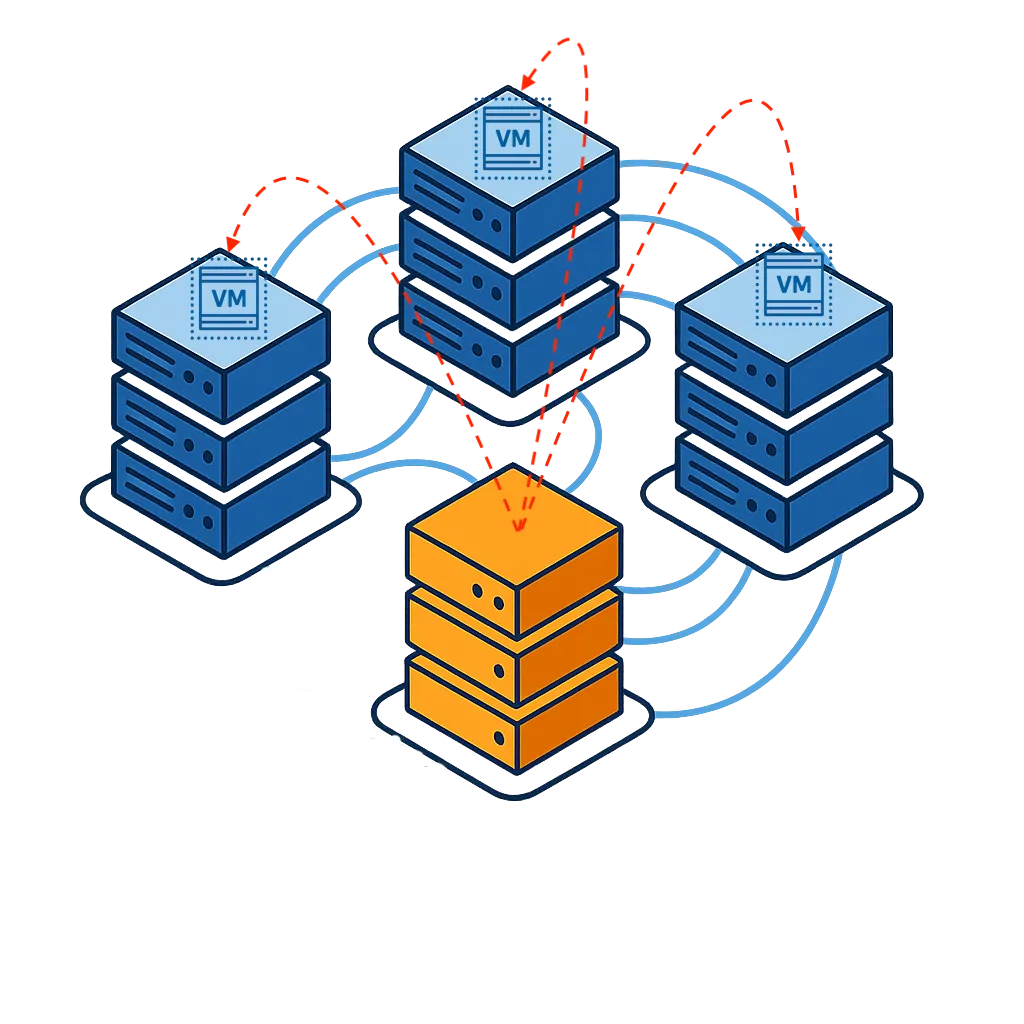
If a component fails unexpectedly, VergeOS isolates the affected node and automatically redistributes workloads across healthy servers in the instance. Using ioOptimize, it distributes those workloads intelligently to deliver the best possible performance with the remaining resources. Applications and data remain online without impacting performance. Users experience no interruption. VergeOS’s single-codebase architecture enables instant coordination of recovery operations without external orchestration or third-party clustering tools.
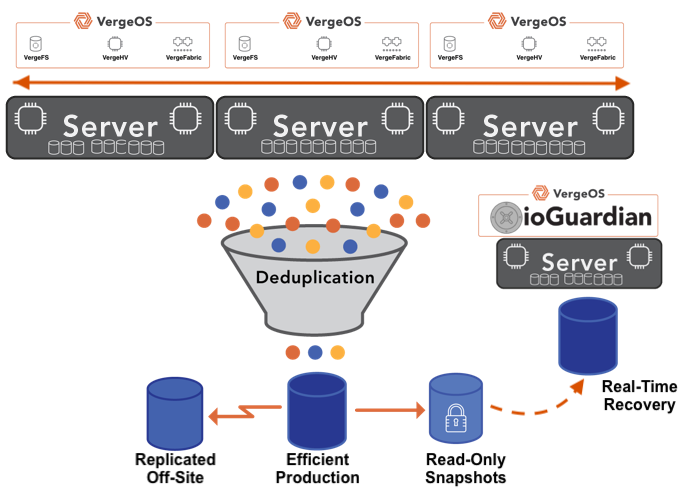
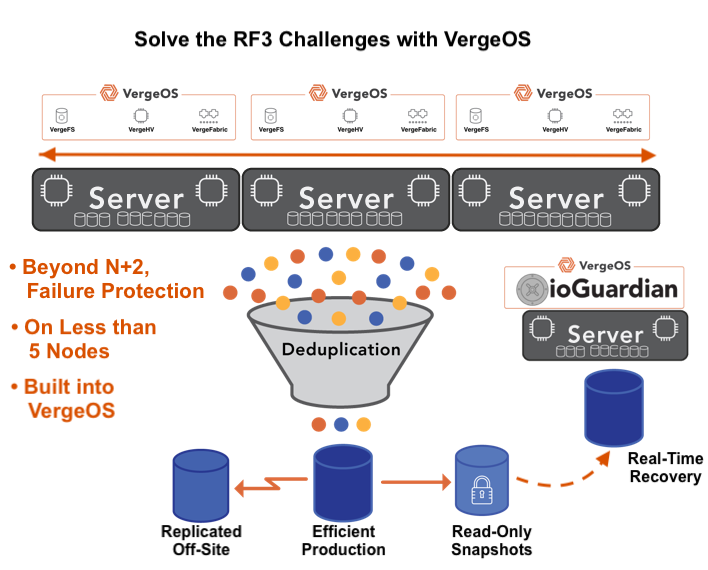
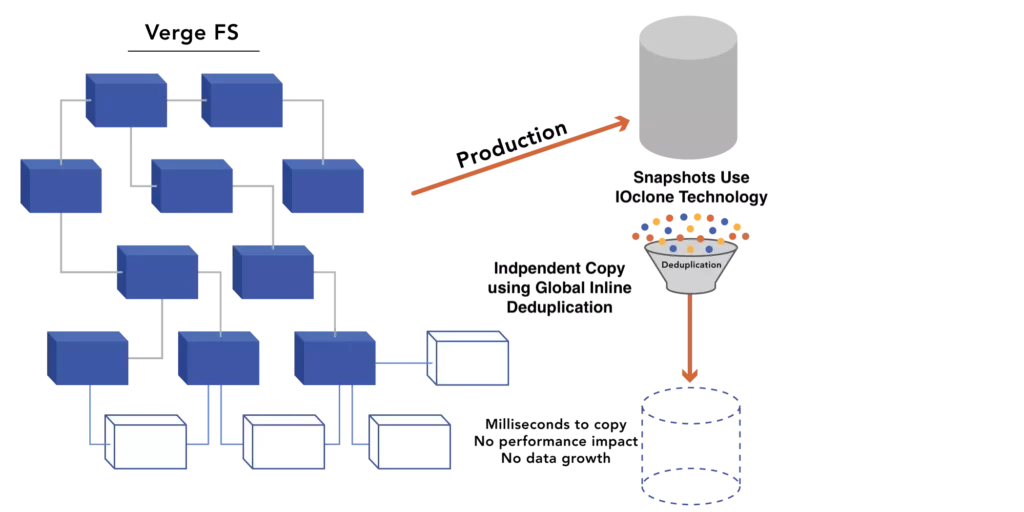
Protection extends beyond simple fault tolerance. The platform guards data using synchronous replication, also known as mirroring. This method provides immediate, real-time protection by maintaining identical copies of data across nodes. It introduces far less overhead than erasure coding or RAID and delivers high performance and low latency. VergeOS incorporates infrastructure-wide deduplication, which significantly reduces the capacity impact of mirroring.
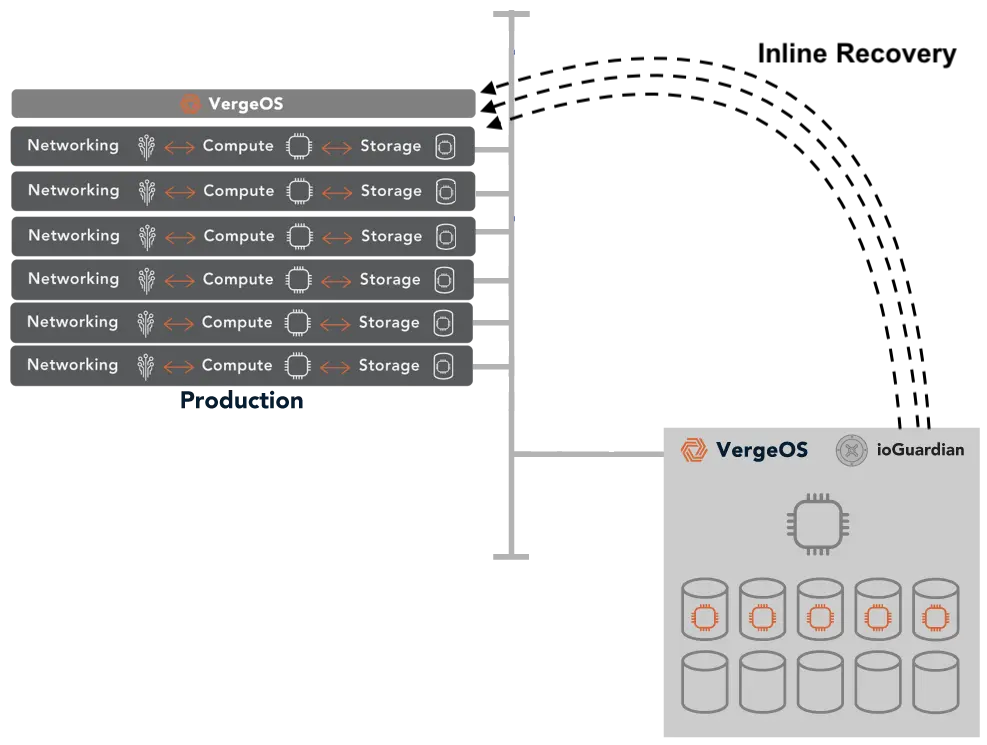
When combined with ioGuardian, protection extends even further. The feature creates a third copy of critical data without the high cost of traditional three-way mirrors or a replication factor of 3. The result is superior data integrity and availability that goes beyond a three-way mirror at lower cost and without added infrastructure complexity.
These capabilities are part of VergeOS’s architectural foundation, not layered add-ons. All this protection comes included at no additional cost. VergeOS was designed with safety in mind from the start. By embedding it into the platform’s foundation, the need for add-on licensing or external recovery tools disappears. Every environment, regardless of size, has the same level of protection and availability.
Hardware aging no longer dictates risk. Servers reaching the end of their expected lifespan keep workloads running and data protected. This approach transforms hardware from a potential single point of failure into a flexible resource pool that evolves gracefully over time.
Conclusion: Redefining Modernization Through Extending Server Longevity
Most organizations are facing an infrastructure modernization problem; they are forced to update their infrastructure due to VMware upheaval and to support new workloads like AI. But modernization need not come at the expense of existing hardware. The right software delivers modernization and extends hardware life.
VergeOS customers experience measurable, lasting value. They routinely extend refresh cycles, reduce capital expenses, and keep servers in production for 8 to 10 years while maintaining full performance and reliability. Many also repurpose previously deprecated systems to support new workloads, from edge environments to AI infrastructure. These outcomes redefine modernization—proving that progress is not about replacement, but about achieving sustained capability and long-term return on investment.