See the Storware-VergeOS architecture demonstrated live, including cross-hypervisor recovery and the four-of-six failure proof point. Live Q&A included.
Register Now →Most VMware exit data protection plans treat the backup tier as a hand-me-down decision. The team picks a destination hypervisor, builds the migration runbook, and assumes the existing backup product will follow the workloads to wherever they land. That assumption is the source of more transition-window pain than any other architectural choice.
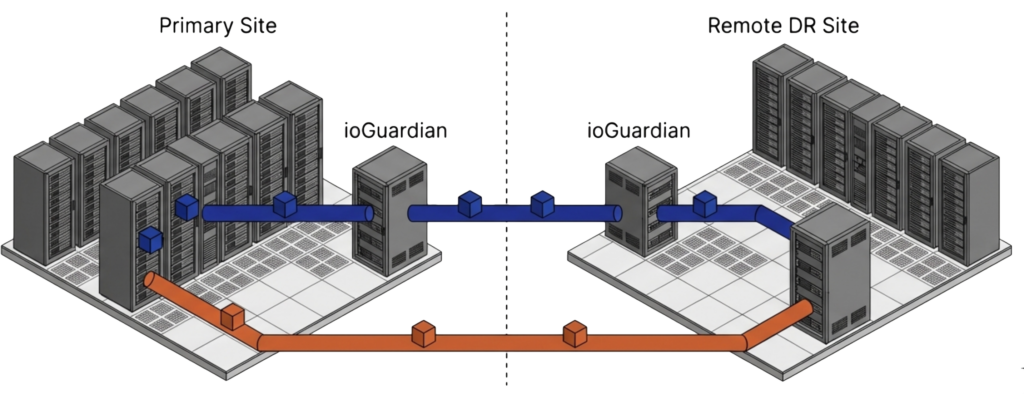
The reason is simple. A VMware-exit migration is rarely a single cutover event. Tier-two workloads move first because their dependencies are simple. Critical workloads stay on VMware longer because of NSX rules, custom backup hooks, vendor support contracts, and operational muscle memory. The result is a weeks-to-months-long parallel-operation window in which production data lives on the source hypervisor, the destination hypervisor, or both. A backup infrastructure that only knows how to talk to one of those hypervisors becomes a second migration project on top of the first.
Key Takeaways
VMware Exit Data Protection Starts in the Transition Window
 Gartner’s planning data projects that 55 percent of enterprises will be in proof-of-concept evaluations of VMware alternatives by 2028. Industry reporting on VMware price increases under Broadcom shows a range from 50 percent to over 1,000 percent for affected customers. CloudBolt’s 2024 survey found 99 percent of IT decision-makers reporting concern about the acquisition’s impact. These three numbers explain why the migration question is no longer optional for most VMware shops. They do not explain why the backup tier needs to be redesigned alongside it.
Gartner’s planning data projects that 55 percent of enterprises will be in proof-of-concept evaluations of VMware alternatives by 2028. Industry reporting on VMware price increases under Broadcom shows a range from 50 percent to over 1,000 percent for affected customers. CloudBolt’s 2024 survey found 99 percent of IT decision-makers reporting concern about the acquisition’s impact. These three numbers explain why the migration question is no longer optional for most VMware shops. They do not explain why the backup tier needs to be redesigned alongside it.
The redesign argument comes from operational reality. A team running two hypervisors needs backup tooling that runs against both hypervisors with the same policies, recovery procedures, and retention horizon. Anything less produces parallel backup operations, parallel recovery rehearsals, and parallel staff training. The cost shows up in the transition window, where the team is already managing two infrastructure platforms.
A backup vendor built for heterogeneous environments removes that cost. The same Server, the same policy model, and the same recovery workflow apply to both sides of the migration. The architectural decision is not which backup product is best in isolation. The decision is which backup product survives the transition without forcing a second migration. This shift has been characterized as the chance to rebuild data protection alongside the hypervisor exit, not after it.
Two Layers, Not One Consolidated Product
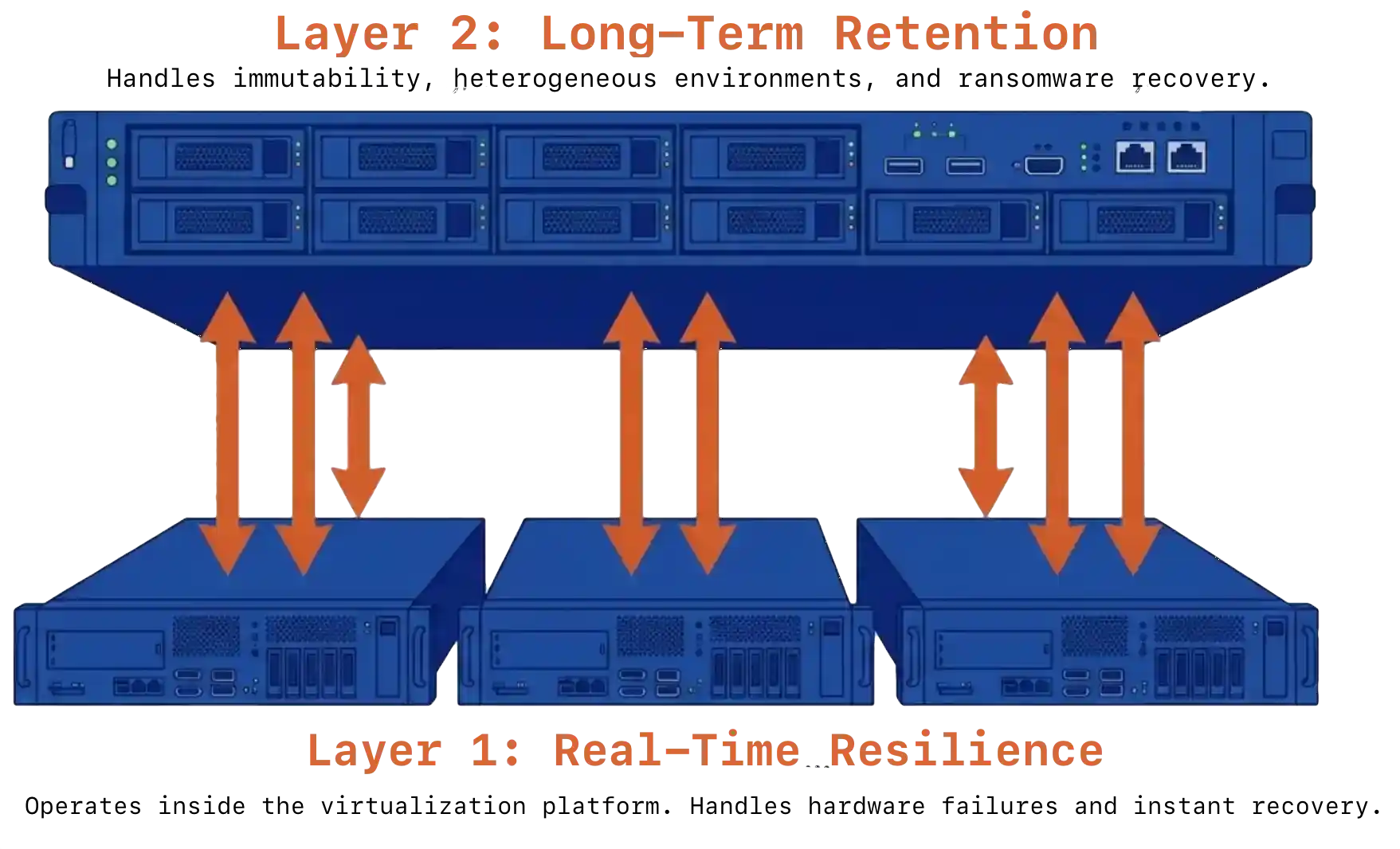 Single-product VMware exit data protection fails one of two tests. Infrastructure-only protection lives inside the virtualization platform. It handles hardware failures and operational continuity well, but offers no compliance retention, no air-gapped immutability, and limited defense against ransomware targeting the production cluster itself. Backup-only protection can take minutes to hours to recover after a hardware event and depends entirely on backup scheduling for meaningful protection.
Single-product VMware exit data protection fails one of two tests. Infrastructure-only protection lives inside the virtualization platform. It handles hardware failures and operational continuity well, but offers no compliance retention, no air-gapped immutability, and limited defense against ransomware targeting the production cluster itself. Backup-only protection can take minutes to hours to recover after a hardware event and depends entirely on backup scheduling for meaningful protection.
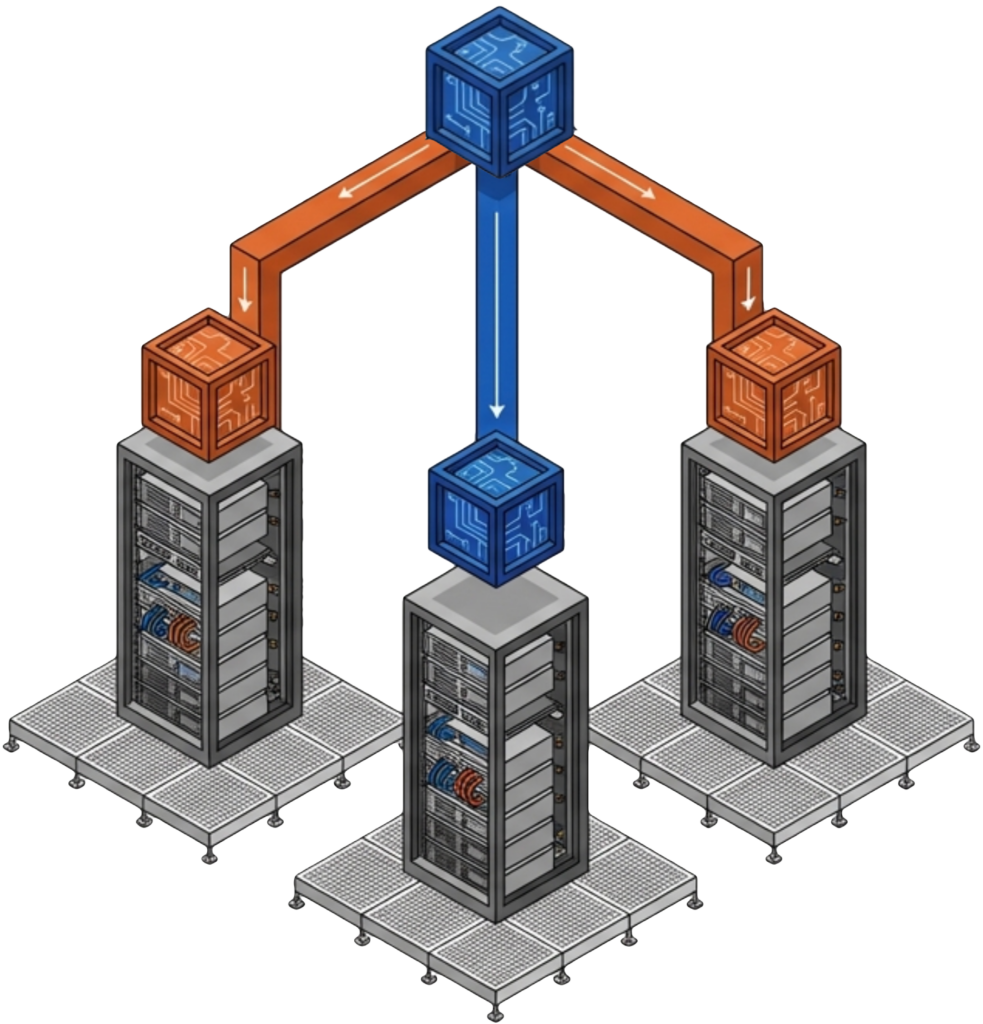
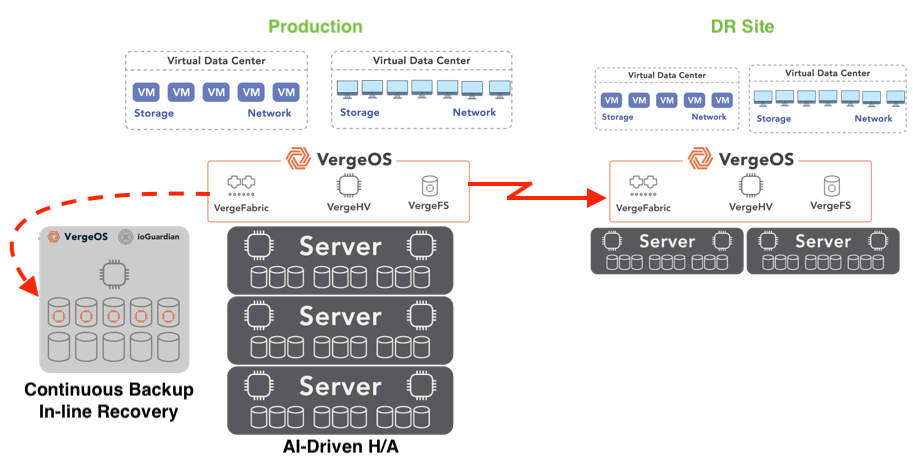
The architecture that survives both modes places independent layers at each level of the stack. Layer one handles real-time resilience. Layer two handles long-term retention and ransomware recovery. The two layers operate independently and reinforce each other.
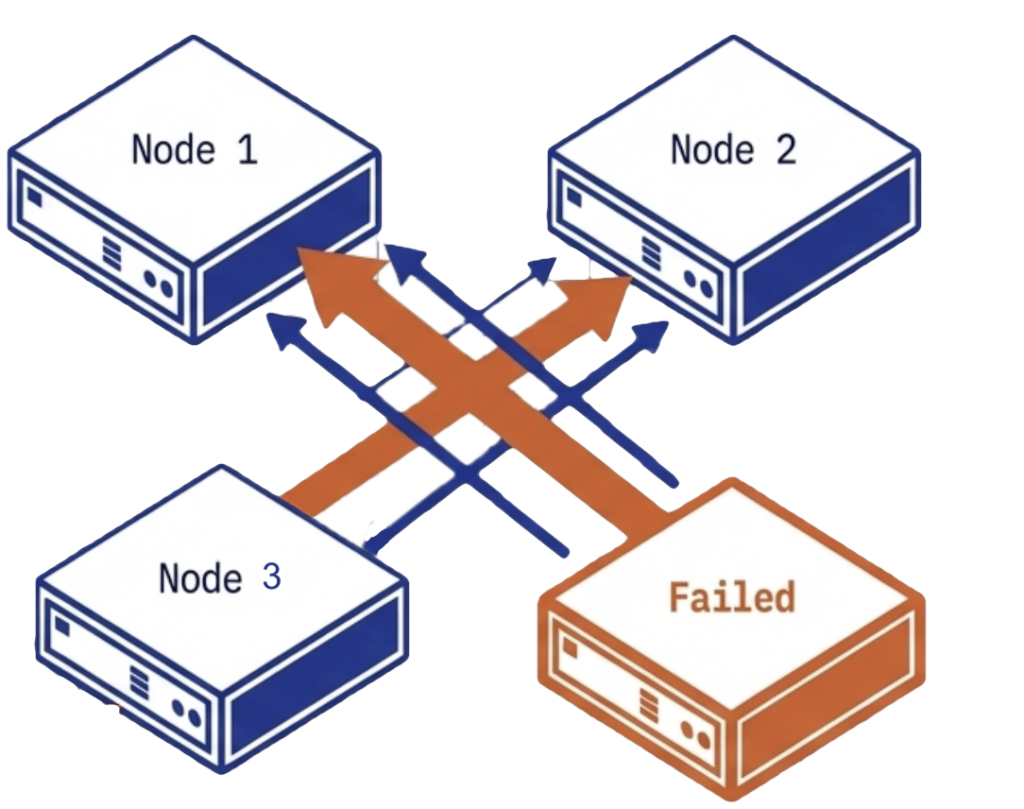
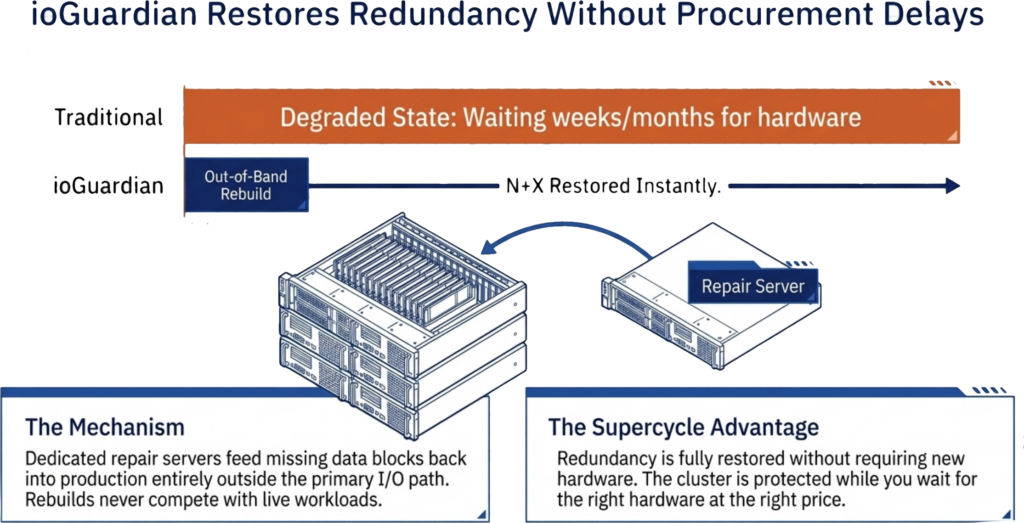
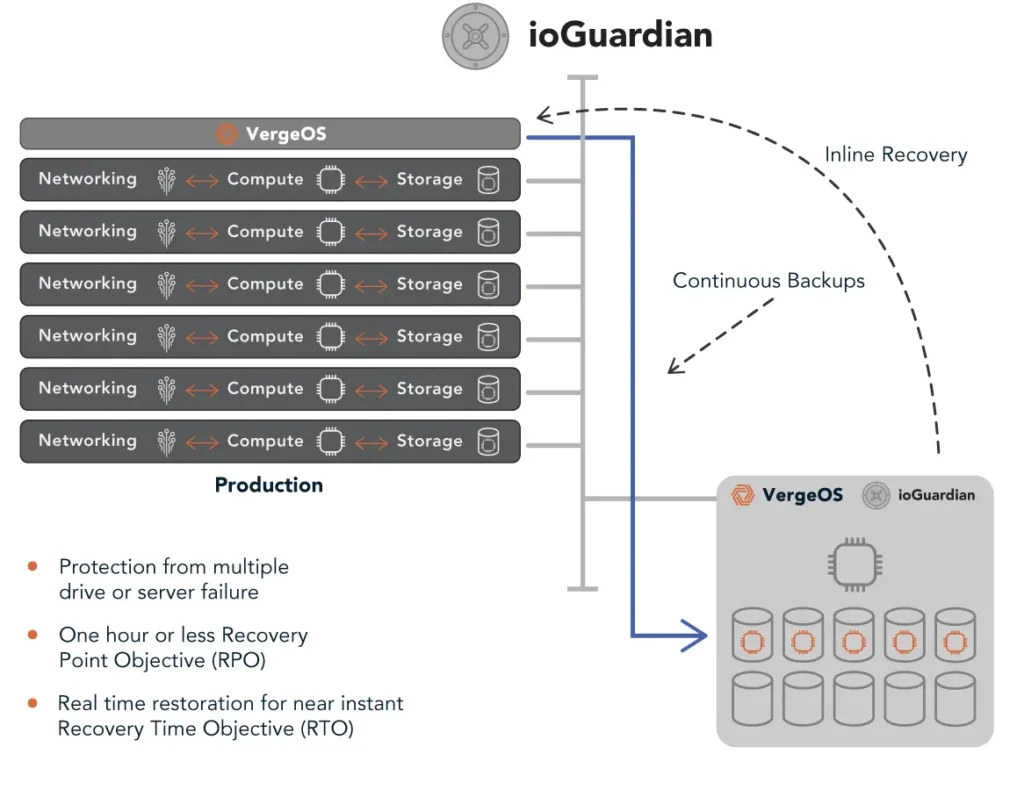
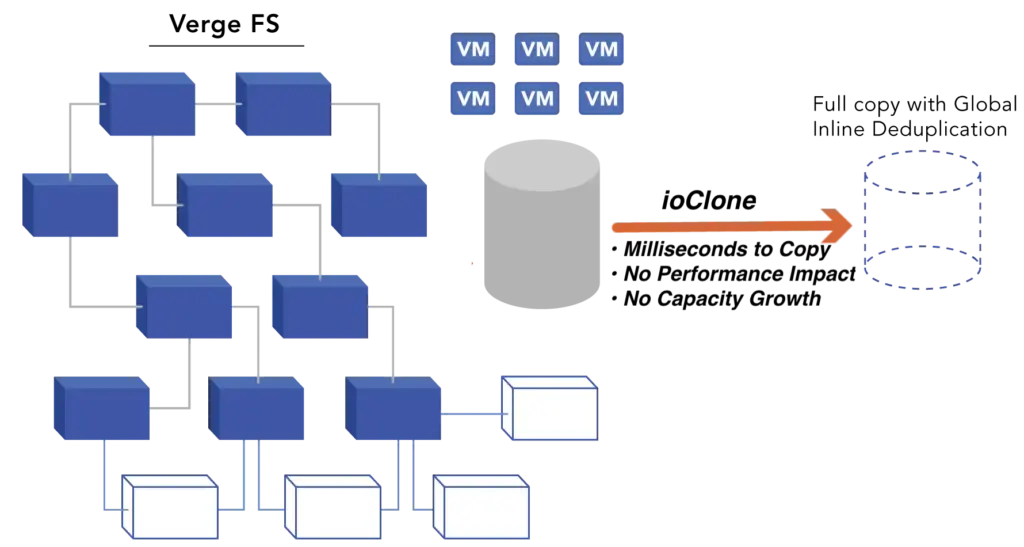
VergeOS handles layer one. Replication Factors distribute data across cluster nodes as a distributed mirror. ioGuardian sits beside RF and actively serves data during failures rather than only accelerating repair. A production VergeOS cluster running RF2 with ioGuardian survived the failure of four of six servers, with zero downtime and zero data loss. ioClone produces fully independent snapshots of entire instances or specific VMs as read-only objects an attacker cannot modify. Global inline deduplication runs across the cluster, so snapshots and replication do not consume duplicate capacity.
Storware Backup and Recovery handles layer two, and the architectural fit is deliberate. For deeper context on how the platform layer drives recovery readiness, see our companion piece on how VergeOS and the backup tier split the DR job.
Key Terms
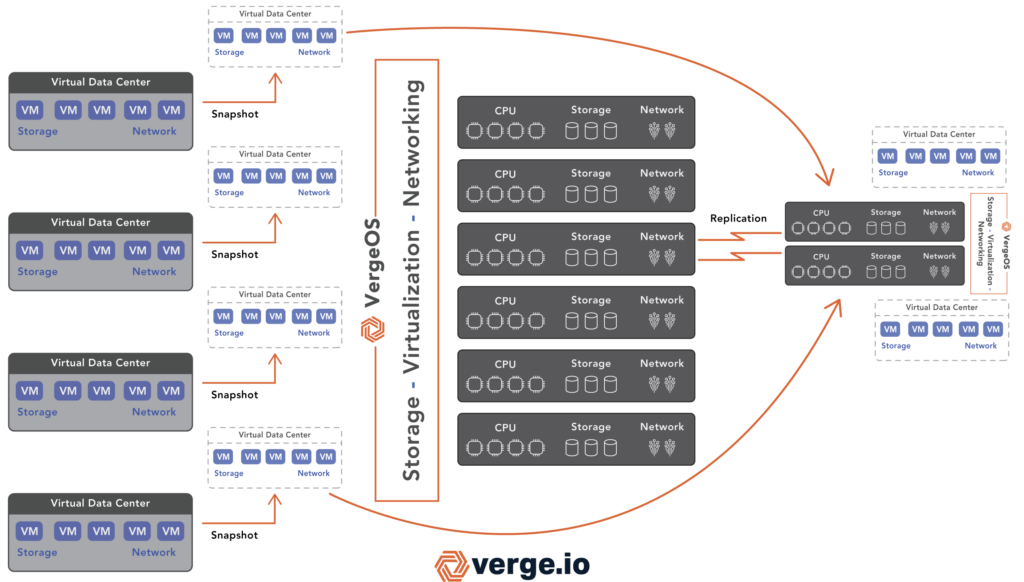
VergeOS data resilience model. RF2 distributes data across cluster nodes as a distributed mirror. RF3 distributes data as a triple mirror.
VergeOS technology that actively serves data during cluster failures rather than only accelerating repair. Survived four-of-six node loss with zero downtime in a production customer environment.
VergeOS independent snapshot mechanism. Produces full copies of entire instances, virtual data centers, or individual VMs as read-only objects with no parent dependencies.
Storware licensing model under which a single agreement covers all supported hypervisors and platforms. Removes the per-platform billing barrier during a hypervisor migration.
Virtual-to-virtual migration capability that recovers a workload backed up from one hypervisor onto a different destination hypervisor. Critical during transition windows.
Why Consider Storware as a Layer-Two Partner
Storware is a data protection platform built specifically for the multi-hypervisor world that VMware-exit migrations create. Breadth is the architectural feature. The platform supports VMware, VergeOS, Proxmox, Nutanix AHV, Red Hat Virtualization, OpenStack, oVirt, KubeVirt, and several KVM variants under a single management plane. A team running two hypervisors during a transition window manages one product, one policy model, and one recovery workflow rather than two of each.
The licensing model reinforces the architecture. Storware operates on a universal license that covers all supported platforms under one agreement. Protecting both VMware and VergeOS during the parallel-operation window produces no additional license fee. The transition becomes a budgeted operational state rather than a billing event.
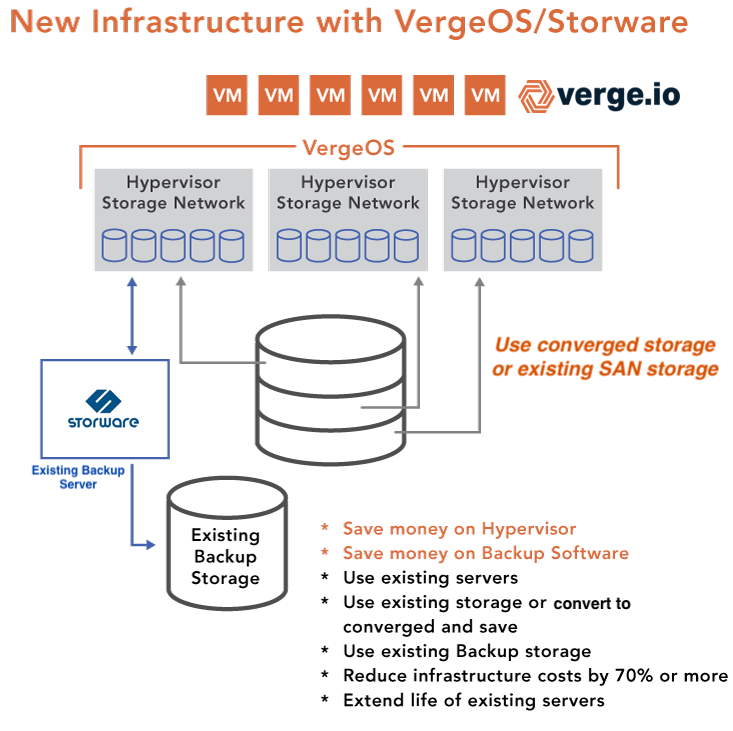
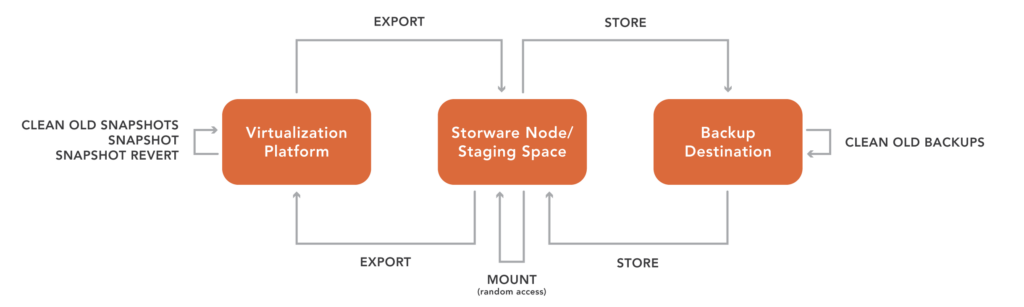
The integration with VergeOS is direct and documented. The Storware Server holds metadata, exposes a RESTful API, and manages policies. The Storware Node deploys as a VM inside the VergeOS cluster or as an external system with network access. Backup jobs use VergeOS ioClone snapshots as the source, read through an NFSv4 share served by a VergeOS NAS service, and apply changed block tracking so incremental jobs transfer only changed data. Synthetic forever-incremental support consolidates the backup chain at the destination, removing the need for periodic full re-runs against production. Supported destinations include NFS, SMB, S3 and Azure Blob object storage, Dell PowerProtect Data Domain via DD Boost, and tape.
Cross-hypervisor recovery is the capability that pays off the design. Storware supports V2V conversion across several platform pairs, including VMware-to-OpenStack and several KVM-based combinations. A workload protected on VMware can be recovered onto VergeOS as a planned migration step rather than as an emergency procedure. An architect builds a parallel VergeOS cluster on existing hardware, recovers protected VMware VMs onto that cluster through Storware, and validates the recovery before committing to migration. The data path during this kind of staged recovery is the same one used in production, so the operation is rehearsed, not improvised.
The Ransomware Layer Is the Real Test
Ransomware reshaped what backup means. The numbers explain why the architecture has to change.
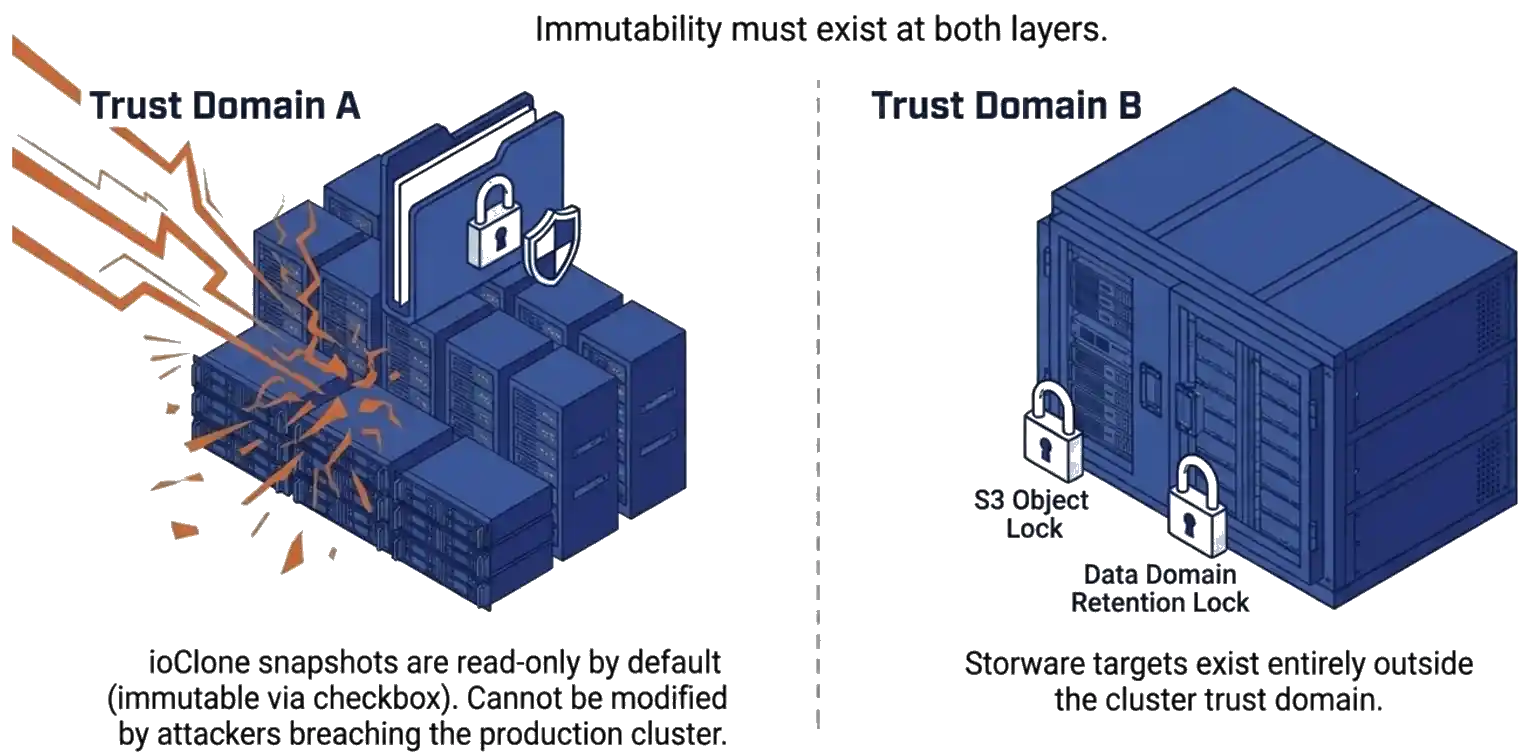 The numbers point to a single architectural answer. A backup that lives in the same trust domain as production has been compromised by definition once an attacker reaches the production system. Immutability has to exist at both layers. ioClone snapshots inside VergeOS are read-only by default and can be set to immutable by checking a box. As a result, they cannot be modified by an attacker who reaches the production cluster. Storware adds immutable storage targets, such as S3 Object Lock and Data Domain Retention Lock, outside the cluster trust domain. Recovery from in-cluster snapshots is near-instant. Recovery from the Storware tier is slower but provides the long-term retention horizon for compliance and forensic analysis.
The numbers point to a single architectural answer. A backup that lives in the same trust domain as production has been compromised by definition once an attacker reaches the production system. Immutability has to exist at both layers. ioClone snapshots inside VergeOS are read-only by default and can be set to immutable by checking a box. As a result, they cannot be modified by an attacker who reaches the production cluster. Storware adds immutable storage targets, such as S3 Object Lock and Data Domain Retention Lock, outside the cluster trust domain. Recovery from in-cluster snapshots is near-instant. Recovery from the Storware tier is slower but provides the long-term retention horizon for compliance and forensic analysis.
Practical implementation is straightforward. Use ioClone snapshots for short-window recovery, typically 30 minutes to 30 days. Use Storware backups with immutable destinations for the long-term horizon, typically a year or longer, depending on compliance requirements. Test both monthly. The 25-point gap in Backblaze’s data between expected and actual recovery times is directly attributable to how often teams rehearse.
Who Owns Which Layer
| VergeOS (Layer 1) | Storware (Layer 2) | |
|---|---|---|
| Hardware failure resilience | Primary | — |
| In-cluster snapshot protection | Primary | — |
| Long-term retention | — | Primary |
| Cross-hypervisor recovery | Supports | Primary |
| Air-gapped immutable storage | — | Primary |
| Ransomware-resistant snapshots | Primary | Supports |
| Universal multi-platform licensing | — | Primary |
The VMware Exit Data Protection Decision
VMware exit data protection in 2026 is no longer a single-product decision. The infrastructure stack is being rebuilt under transition pressure. The data protection tier needs to span source and destination platforms during that transition. The cost of getting either layer wrong is measured in budget cycles. The architecture that survives places independent protection at each level and treats the transition window as a planned operational state.
For architects evaluating this design, the practical next step is a paired proof-of-concept on existing hardware. Stand up a small VergeOS cluster, deploy a Storware Server and Node against it, protect a VMware VM, and recover it onto VergeOS through Storware. A week with the running system communicates more than any document.
The full white paper, Resilience Without Lock-In, walks through the complete two-layer architecture, the Storware reference implementation against VergeOS 4.13 and higher, sizing recommendations for the NAS service, cross-hypervisor recovery scenarios, and the role-by-role comparison of which product owns which layer. Read the white paper →