While it used to be a project for highly regulated industries, designing a compliant IT infrastructure is now on the project list for many organizations. We saw this evidence in the InBrief session with TruthInIT a few weeks ago. Questions around compliance were some of the most commonly asked.
The top three requirements for designing a compliant IT Infrastructure are:
- Security and Privacy
- Data Protection and Retention
- Disaster Recovery
One of the challenges faced by IT is the varying compliance requirements within an organization, with some departments having stricter needs than others. Addressing the compliance needs of each department can be a significant challenge. Additionally, creating a compliant infrastructure can be both expensive and complex, often requiring multiple products.
Securing a Compliant IT Infrastructure
When designing a compliant IT infrastructure, the initial step is to ensure its security through the implementation of strong authentication mechanisms and robust access controls. Occasionally, a department with stringent compliance requirements may require customized networking or storage configurations.
Certain departments may have unique data privacy needs and must ensure that their data is not accessible to other departments. Privacy measures may include dedicated computing and storage resources for specific departments or ensuring a certain level of performance.
Security without Silos
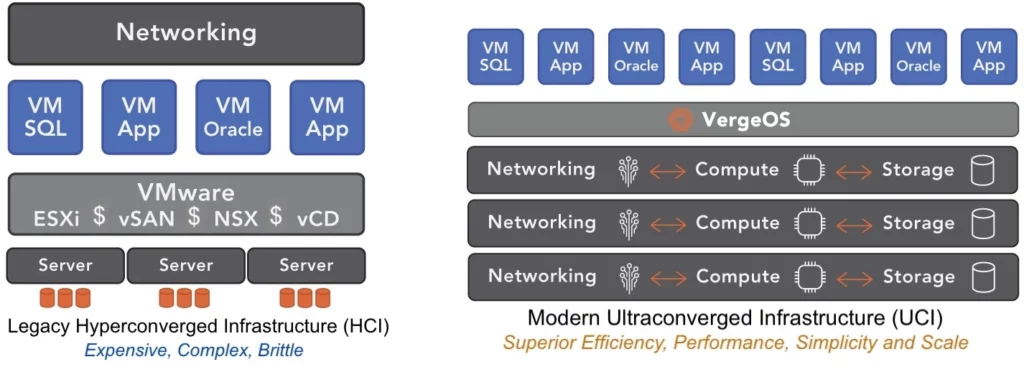
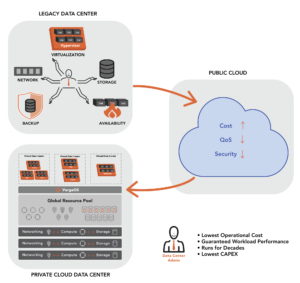
Many organizations are required to create secure environments by building separate infrastructure silos, each tailored to the unique needs of a department or use case. However, silos of infrastructure are costly and lead to additional compliance requirements for protection, retention, and disaster recovery.
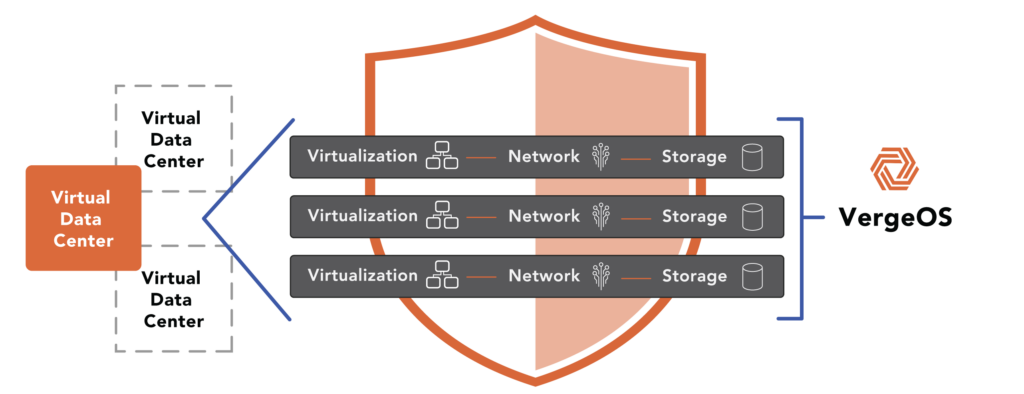
Fortunately, VergeOS offers a solution with its Virtual Data Center (VDC) technology. Similar to how a virtual machine encapsulates a physical server, a VDC encapsulates an entire data center. By utilizing VergeOS, customers can establish a VDC for each department, meeting all the aforementioned needs. Each VDC can have its own access controls, authentication requirements, and user management functions.

The Power of Virtual Data Centers
VDCs also allow for allocating specific computing and storage resources to particular departments, preventing other departments from accessing those assets. IT can effectively create a unique compliant IT Infrastructure for each department as needed. Plus, the VDC provides flexibility to reallocate resources when the department or workload no longer needs them. or IT can allocate more resources as a project ramps up. Organizations can create a highly compliant VDC for regulated functions and a more general-purpose VDC for other use cases.
A key benefit is that IT can manage all VDCs from a single user interface and run on the foundational operating environment, VergeOS. This reduces complexity by using a single piece of software and enables the management of all VDCs through a single interface. It also lowers costs through more efficient resource allocation and higher utilization.
Perfect Compliant IT Infrastructures with Recipe Marketplace
Another key benefit of VergeOS is it also includes a Recipe Marketplace, which enables customers to pre-build complete data centers and then deploy them with the click of a button. This makes quickly deploying HIPAA or PCI-compliant VDCs easy. Also, because of the recipe engine, you can deploy them perfectly every time without worrying about missing that one setting that could otherwise move your VDC from compliant to non-compliance.
The combination of VDCs and the Recipe Marketplace makes IT more agile. Usually, if the organization needs a PCI environment and a HIPAA environment, IT would normally build two separate silos and then have them independently audited for compliance. If the organization needs another compliant environment, then they have to stand up another separate silo and then have that silo audited. IT must resubmit a compliant silos for another round of auditing if it needs to scale by adding additional computing power or storage capacity.
Without VDC and the Recipe Marketplace, IT must build each environment to handle the capacity and throughput of where it will end, which may take years to scale to, if ever. With VDCs and the Recipe Marketplace, IT can share resources across a variety of compliant environments. Once IT creates a“golden” VDC for each use case and it passes the audit (PCI/HIPAA), then IT can spawn nested VDCs each time the organization has a new request. No additional auditing is required.
To learn more, check out this VergeOS Architecture Deep Dive with our CTO, Greg Campbell.
Protecting and Retaining Data for a Compliant IT Infrastructure
It is essential to protect the IT resources of every department within an organization from data loss or hardware failure. When designing a compliant IT infrastructure, however, some departments may have more stringent requirements than others. To meet these needs, IT often has to use multiple products. In most cases, separate backup and retention products are necessary, even if the processes can be applied across departments. It is common for data between departments with different compliance needs not to intermix. As a result, each silo requires a sub-silo of data protection.
Protection and Retention without sub-silos
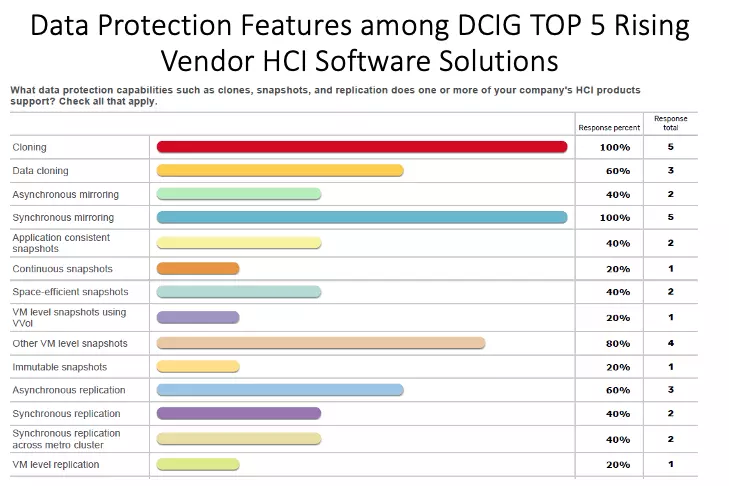
With VergeOS, you can customize data protection and retention strategies for each VDC, and the platform includes built-in tools to meet the unique needs of every department. While many solutions offer snapshot capabilities, most are limited by performance issues, restricting the number of active snapshots and how long they can be retained. Deleting snapshots to free up disk capacity can also be a tedious and lengthy process.
As a result, many customers opt for data cloning, creating copies for backup and archiving purposes. However, managing multiple copies is time-consuming, costly, and requires additional storage capacity. It also increases the likelihood of errors since IT needs to integrate two or three separate processes.
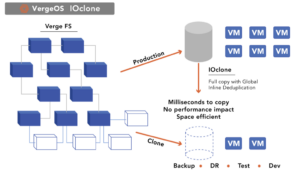
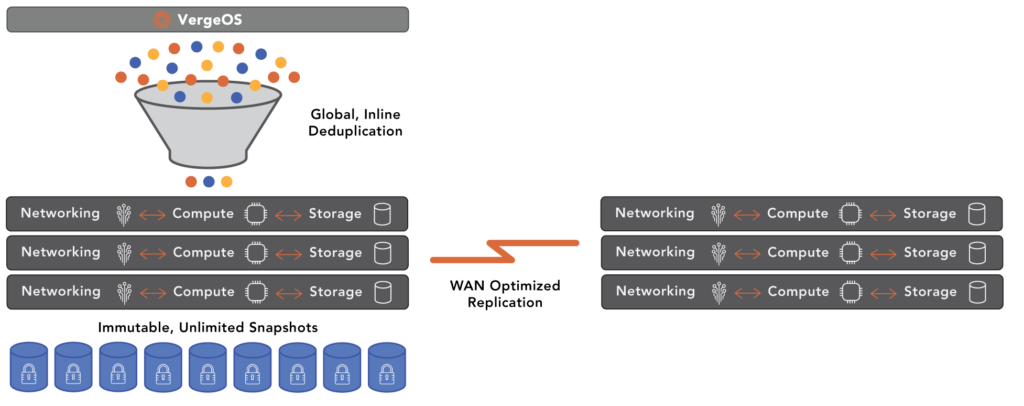
VergeOS’s IOclone, combines the best capabilities of snapshots and clones by leveraging our unique Global Inline Deduplication technology, which is at the core of VergeOS instead of a bolted-on afterthought. IOclone enables each snapshot to be independent of the VM or Virtual Data Center it is copying. Still, because of the deduplication process, these copies are made in milliseconds and are space efficient. IOclone snapshots are also immutable so that nothing can alter them, which is often another compliance requirement.
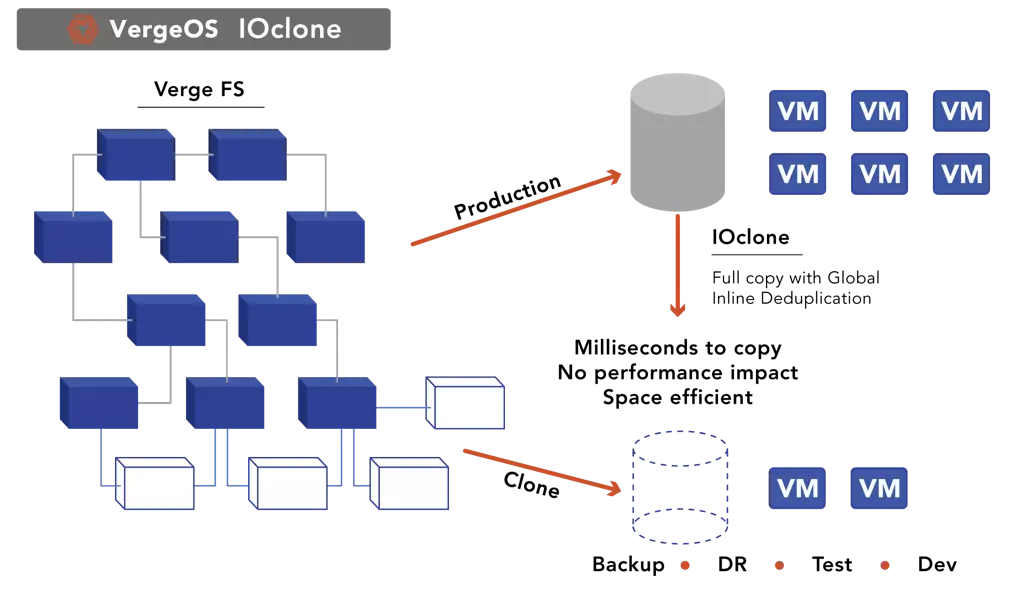
The independence of IOclone’s snapshots means that VergeOS customers can have an almost unlimited number of snapshots. IT can repurpose those snapshots for other use cases or applications and can retain them indefinitely without impacting performance.
To learn more about the differences between snapshots, clones, and how IOclone brings the best of both technologies together, watch our on-demand TechTalk, “TechTalk: Deep Dive on Virtual Infrastructure File Systems.”
Recovering a Compliant IT Infrastructure After Disaster
There are strict disaster protection regulations that apply to data centers. Designing a compliant IT infrastructure requires additional measures to ensure preparedness, which can be quite demanding. IT may need to establish a separate DR silo with specific products to meet compliance requirements. Moreover, the DR site must meet the same standards as the primary site, which adds more complexity and cost.
A DR Strategy Minus DR Silos
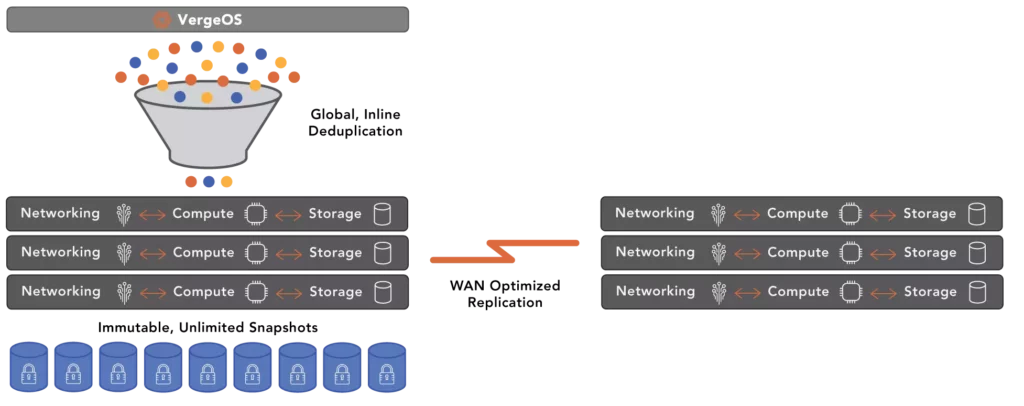
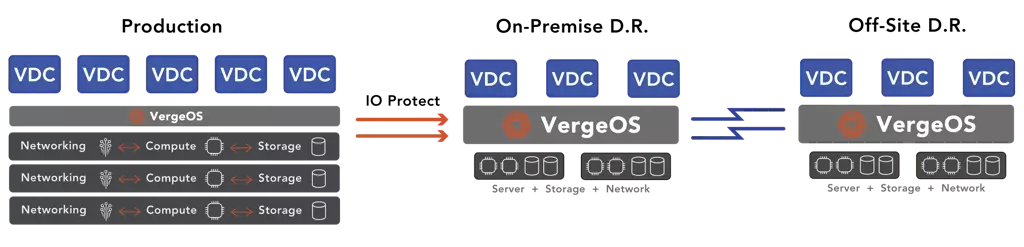
VergeOS’ IOprotect also leverages our Global Inline Deduplication to provide Wide Area Network (WAN) intelligent data movement between locations. Multiple physical data centers can replicate to a single DR data center, but redundant data between them will not be sent.
Virtual Data Centers (VDCs) play a crucial role in disaster recovery. With each department’s data center encapsulated within a replicated VDC, all the necessary information is readily available for quick recovery in case of a disaster. This makes it possible for IT to bring departments back online within minutes after a site failure without the need to consult a DR runbook or the need for ad-hoc fine-tuning to reconfigure network, security, or storage policies. VergeOS’ IOprotect capability is so cost-effective you can have an on-premises DR and an off-premises DR for 50% less than the cost of your current DR strategy, enabling you to be prepared for both major and minor disasters.
To dive deep into VMware disaster recovery (DR) Sign up for our Video Learning Guide – Each week, our experts take you through a critical part of making your infrastructure environment more resilient.
Conclusion
Designing a compliant IT infrastructure usually means a significant increase in IT spend and consumption of IT administrative time. Creating separate silos for compliant departments within the organization also leads to increased long-term costs and the inability to adapt the infrastructure to the organization’s future demands flexibly.
VegeOS, through its VDC technology, enables IT to create compliant IT infrastructures while leveraging existing hardware dynamically. It also provides capabilities like IOclone and IOreplicate to meet the data protection, data retention, and disaster recovery requirements for IT.
You can try out the full power of VergeOS right now without having to borrow hardware. Signup for a test drive, and we will create a VDC just for you. You can then create your VMs and even compliant and non-compliant VDCs.