Zia Yusuf spent his career building the partner ecosystems that carry infrastructure to market. On July 7, 2026, he invested in VergeIO and joined its board, the latest and most telling example of VMware executives joining VergeIO. He is not the first. Five weeks earlier, VMware’s former Chief Technology Officer made the same move. The pattern is now hard to miss, and Yusuf’s decision explains what it means for the partners and customers leaving VMware behind.
Key Takeaways
- Zia Yusuf, former SVP of Strategic Ecosystem and Industry Solutions at VMware, invested in VergeIO and joined its board to help build the go-to-market and partner strategy.
- He is the second senior VMware leader to join in weeks, after former CTO Kit Colbert. One built the ecosystem, the other set the technology.
- The common thread is the private cloud operating system, a single codebase that replaces the four-vendor virtualization stack.
The Leader Who Built VMware’s Partner Engine

Zia Yusuf, Board Member & Investor, VergeIO.
Yusuf led VMware’s Strategic Ecosystem and Industry Solutions organization from 2021 to 2024. His teams built the joint solutions and partner programs that carried VMware to market through Dell, the hyperscalers, system integrators, independent software vendors, and OEMs. Before VMware, he ran the global partner group at SAP, a network of more than 7,000 partners, and earlier advised technology companies on go-to-market as a Senior Partner at Boston Consulting Group. Few people have spent more time inside the machinery that takes enterprise infrastructure to the customer.
That background is the reason his move matters. Yusuf now advises the VergeIO board on go-to-market and partner ecosystem strategy, and his read on VergeOS is a market one. Partners can build a durable business on a single platform that lowers the customer’s total cost of ownership. “The signal I look for is an architecture that gives partners something durable to sell,” Yusuf said. VergeOS is that architecture, and he joined to build the route it takes to reach the customer.
Key Terms
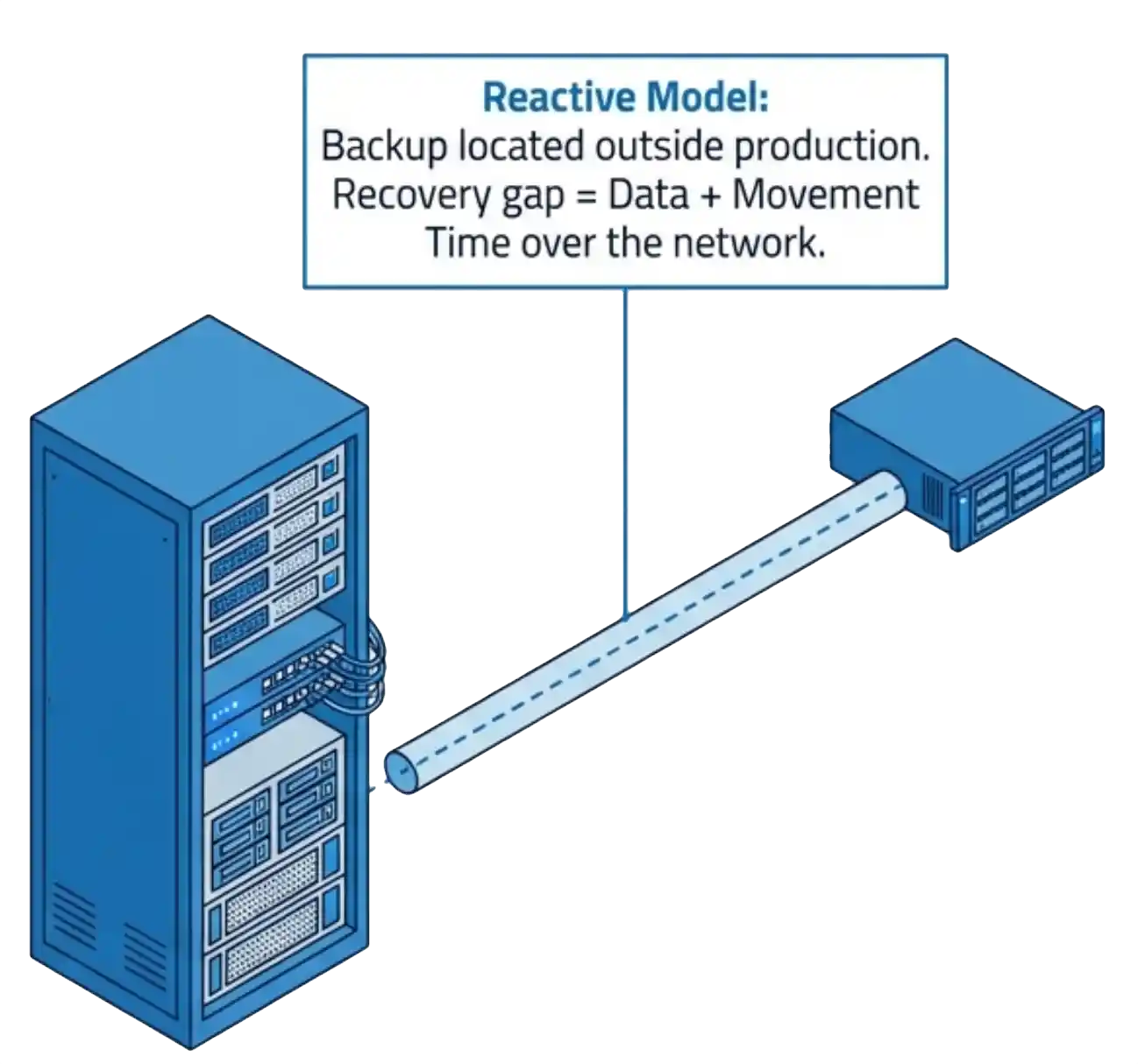
Private cloud operating system (PCOS). A single operating system that runs virtualization, storage, networking, and tenancy as native functions from a single codebase, rather than four separate products behind a single management screen. It delivers the promise of Private Cloud to the enterprise.
The hypervisor tax. Each layer of the stack consumes memory and CPU, resources that cost more than ever. Every core and gigabyte the infrastructure takes for itself is one the virtual machines do not get, so customers overprovision their hardware to leave enough headroom for their applications.
Why a Partner Leader Sees an Opening Now
Yusuf is reading a market in motion. Broadcom’s changes to the VMware partner program moved the channel to an invitation-only model and left many established resellers without a flagship platform to recommend. Broadcom has narrowed its focus to its largest accounts, and the broader base of customers and the partners who serve them now rank as a lower priority. That underserved majority is the opening. Those customers turn to their partners for guidance, looking for infrastructure that costs less, does more today, and carries them into AI workloads tomorrow. A leader who built the partner side of VMware now points that community to the answer.
The Precedent: Kit Colbert

One codebase for today’s VMs and tomorrow’s AI workloads.
Yusuf is the second VMware leader to back VergeIO in weeks. On June 2, Kit Colbert, VMware’s former Chief Technology Officer, invested and joined the board. Colbert set VMware’s technical direction for two decades and led 2,400 engineers until Broadcom’s 2023 acquisition. Where Yusuf judged the route to market, Colbert judged the technology, and he reached the same conclusion about the architecture. Two leaders, two seats, one verdict.
What the Pattern of VMware Executives Joining VergeIO Means
The exit from VMware is not a swap of one hypervisor for another. It is a move to a private cloud operating system, a single codebase ready for the container and AI workloads that come next. The ecosystem builder and the technologist looked at the same company from different seats and agreed.
| Leader | Role at VMware | What the investment validates |
|---|---|---|
| Zia Yusuf | SVP, Strategic Ecosystem and Industry Solutions, 2021 to 2024 | The route to market. Partners can build a lasting business on the platform. |
| Kit Colbert | Chief Technology Officer, 2021 to 2023 | The architecture. A single codebase beats four products stitched behind a GUI. |
The Verdict
Zia Yusuf built the partner side of one of the largest infrastructure companies in the industry, and he chose to put his money and his name behind VergeIO. Kit Colbert reached the same place from the engineering side. That agreement, from two people who know exactly how VMware worked, is the reason the pattern matters.
Read the announcements and hear the strategy firsthand:
Frequently Asked Questions
Who is Zia Yusuf?
He led VMware’s Strategic Ecosystem and Industry Solutions organization from 2021 to 2024 and ran the global partner group at SAP before that. He now advises the VergeIO board on go-to-market and partner ecosystem strategy.
Did he invest his own money?
Yes. Yusuf invested in VergeIO and joined its Board of Directors, as did former VMware CTO Kit Colbert weeks earlier.
What is VergeOS?
VergeOS is a private cloud operating system. It runs virtualization, storage, networking, and tenancy as functions of one operating system, written from a single codebase.
Where can I hear more?
Zia Yusuf and VergeIO SVP of Sales Chris Lehman host a live webinar on July 16, 2026. Registration is open now.