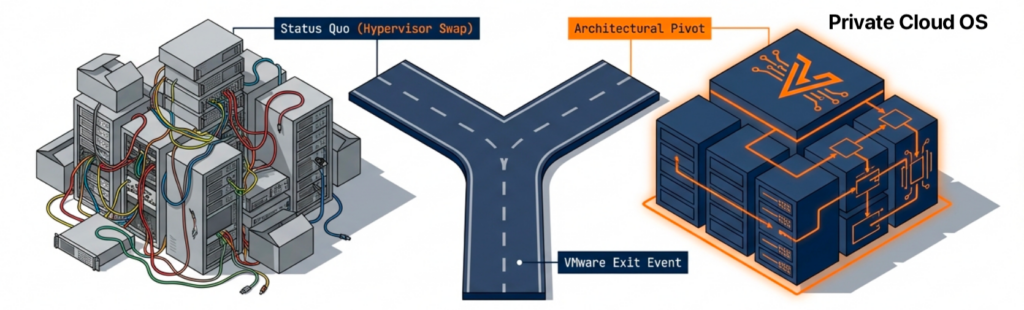
To be more than a hypervisor swap, IT professionals need to look for an AI-ready VMware alternative. The Broadcom acquisition has rewritten the economics of virtualization, and many IT teams are still trying to escape renewal costs that no longer justify the value received.
Treating the VMware exit as a single-platform replacement project is a mistake, especially since the next infrastructure decision is already taking shape around AI. That decision arrives faster than most teams expect, and the platform selected during the VMware exit determines whether private AI becomes practical or prohibitively expensive.
An AI-ready VMware alternative now has to pass two tests. The platform has to replace VMware without forcing an application redesign, and it has to support the AI workloads that will land in the data center next.
Key Takeaways
- An AI-ready VMware alternative has to pass two tests: replace the platform today and run AI workloads tomorrow.
- A platform that solves virtualization but not AI forces a second infrastructure decision a year or two later.
- Test AI readiness on existing hardware before committing to a replacement.
Why an AI-Ready VMware Alternative Matters Now
Many organizations begin their AI journey with public services. That approach removes the need to purchase infrastructure, hire specialists, or learn new operational models. The problem is that most successful AI projects eventually encounter limits that are difficult to solve from outside the organization.
Cost
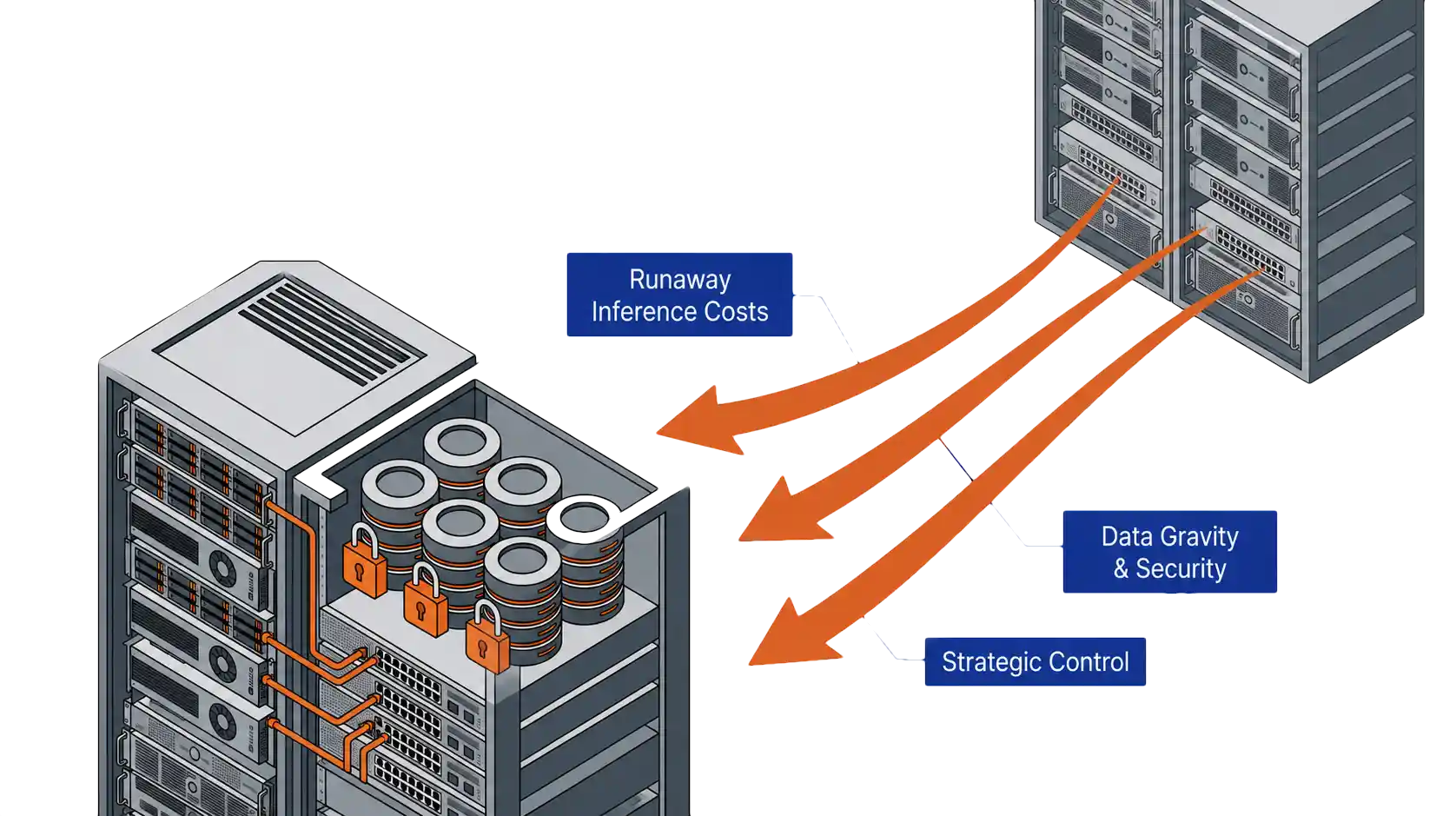
Public AI platforms charge for every interaction (Token Costs). A handful of occasional questions costs little, and an assistant used by hundreds of employees, a document analysis platform processing millions of records, or a customer-facing application serving thousands of daily requests creates a very different economic picture. Recurring inference costs grow faster than expected, and at some point, owning the infrastructure costs less than renting for every transaction.
Data Gravity
The most valuable AI systems depend on internal documents, customer records, operational procedures, financial data, and institutional knowledge. Moving that data into external AI environments introduces governance, compliance, security, and operational concerns. The more valuable the data, the stronger the incentive to keep the AI system close to the source.
Strategic Control
AI is rapidly becoming part of an organization’s competitive advantage. When customer service workflows, software development assistance, and decision support systems depend entirely on external providers, pricing changes, model updates, and availability decisions remain outside the organization’s control.
Not every AI workload belongs in the data center, and public AI services continue to play an important role. Most organizations will identify a set of AI workloads that cost less, are governed more cleanly, and operate more strategically on their own infrastructure. The platform selected during the VMware exit is also the foundation for those workloads. An AI-ready VMware alternative pulls both jobs together from day one.
Key Terms
What to Look For in an AI-Ready VMware Alternative
Most organizations begin their VMware evaluation with a familiar checklist. Those requirements remain important. The first job of any VMware alternative is replacing the platform that already runs the business.

Migration Simplicity
Existing VMware workloads should move without application redesign, operating system changes, or lengthy conversion projects. The migration process should preserve virtual machines, networking, and storage configurations and minimize downtime. Less time rebuilding workloads means faster realization of savings.
Feature Parity
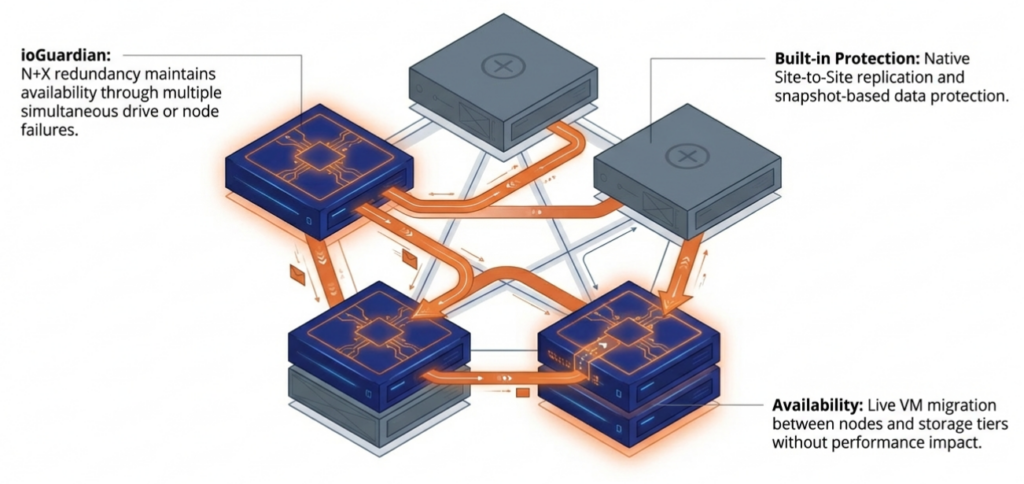
High availability, live migration, snapshots, distributed resource management, virtual networking, and integrated storage services need to operate as mature production capabilities, not features that require workarounds to reach the same outcome.
Stronger Protection
A VMware migration is the opportunity to improve recovery capabilities, not duplicate them. Native replication, immutable snapshots, ransomware detection, rapid recovery workflows, and integrated disaster recovery all belong in the evaluation.
Operational Simplicity
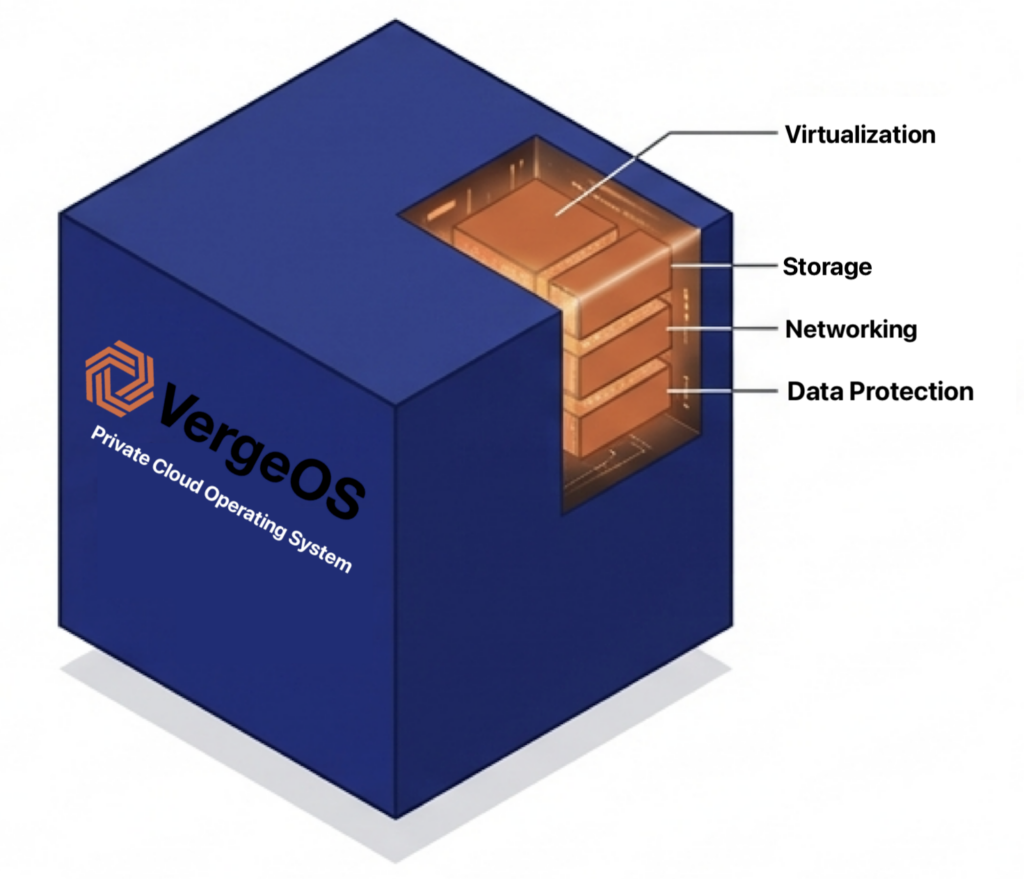
Many organizations left VMware over more than licensing. They also became frustrated with a virtualization stack that had evolved into multiple products, each with its own management, upgrade, troubleshooting, and expertise. Storage, networking, virtualization, security, automation, monitoring, and recovery became independent layers, often behind a unified interface that hid the seams.
The platform should reduce operational complexity, not recreate it. A unified architecture should run virtualization, storage, networking, protection, and automation as part of a single system. The default decision of swapping hypervisors, replacing VMware with another loosely integrated stack, exchanges one form of complexity for another. The goal is simplification, not substitution.
Licensing Simplicity
Licensing costs were the catalyst for leaving VMware in the first place. Replacing one complicated licensing structure with another postpones the problem. The alternative should deliver predictable economics that hold steady as the environment grows and not penalize the organization for increasing density, which is the consequence of a “per-core” licensing model.
These five requirements form the foundation of an AI-ready VMware alternative, and they are where most evaluations stop. None of them answers the next infrastructure question. They determine whether a platform replaces VMware, not whether that same platform supports the AI workloads many organizations will bring into their own data centers. A platform can satisfy every item on this checklist and still force a second infrastructure decision a year or two later. The missing consideration is AI readiness.
The Missing Criterion of an AI-Ready VMware Alternative
The search for an AI-ready VMware alternative begins where most evaluations end. Many platforms start to fall short on feature parity with VMware. Most also lack a clear path to AI. Some require separate platforms or additional licensing to support containers. Others support GPUs through disconnected infrastructure. Many force organizations to build, operate, and support an entirely separate AI environment.

The result is a platform that solves today’s virtualization challenge and creates tomorrow’s infrastructure challenge.
As AI workloads move into the private data center, requirements change. Containers become as important as virtual machines. GPU resources become shared infrastructure. AI services need the same data, protection, networking, and recovery framework as the rest of the business.
A platform that cannot meet those requirements forces a second infrastructure decision. New hardware gets purchased, a separate AI environment goes online, and a second team starts supporting it. The organization that set out to simplify operations ends up adding complexity.
The better approach is to select an AI-ready VMware alternative that handles both traditional virtualization and private AI from day one.
Kubernetes as a First-Class Workload
Most modern AI applications deploy as containers. Kubernetes should operate on the same infrastructure as virtual machines and share the same networking, protection, and disaster recovery framework. Containers should not require a separate infrastructure stack.
GPU Sharing and Virtualization
GPUs are among the most expensive resources in the data center, and few organizations justify dedicating an entire accelerator to a single workload. The platform should support NVIDIA vGPU 20 and universal Multi-Instance GPU (MIG) so AI inference, VDI, engineering, and analytics workloads share one physical GPU.
Integrated AI Runtime
Running private AI should not require building a separate AI platform. Solutions such as VergeIQ deploy private language models, retrieval-augmented generation applications, document analysis systems, and AI assistants directly on the cluster that already hosts virtual machines and containers.
Storage Performance
Inference workloads depend on rapid access to models, embeddings, and vector databases. Infrastructure delivering millions of IOPS with sub-millisecond latency on standard NVMe eliminates the bottlenecks that traditionally justified dedicated AI infrastructure.
Architectural and Operational Simplicity
AI should not introduce another set of servers, storage systems, and management tools, nor require a dedicated infrastructure team. The goal is one platform that supports virtual machines, containers, GPUs, and AI services within a single operational framework managed by the same infrastructure team.
That is where many VMware alternatives fall short. They solve the virtualization problem and leave the AI problem for next year. Organizations that avoid a second platform decision choose a platform that handles both from day one.
VMware Exit: Today’s Checklist vs. Tomorrow’s Workload
| Capability | Virtualization-First Checklist | AI-Ready VMware Alternative |
|---|---|---|
| Containers | Separate cluster, separate license | Kubernetes as a first-class workload |
| GPU support | Optional add-on, often per-host | vGPU and MIG sharing across workloads |
| AI runtime | Build it yourself | Integrated runtime (VergeIQ) |
| Storage | Tuned for VM I/O | NVMe-native, sub-millisecond latency |
| Operational model | Separate team for AI | One team, one operational framework |
Prove an AI-Ready VMware Alternative on Hardware You Already Own
Evaluating an AI-ready VMware alternative does not require new hardware. The best proof of concept runs on the cluster already sitting in the data center, whether VxRail, ReadyNode, or commodity servers. On that hardware, migrate a virtual machine, deploy a Kubernetes workload, and run a private AI inference workload.
Measure the migration effort. Measure the infrastructure needed to support containers. Measure how GPUs get shared and managed across workloads. The most telling question is whether one team can manage it all through a common operational framework.
The real test is not whether a platform runs virtual machines. Nearly every alternative does that. The test is whether the platform becomes the foundation for the next decade of infrastructure. If virtual machines, containers, GPUs, and AI services each require different platforms, tools, and teams, then the evaluation has already produced its answer.
Organizations evaluating an AI-ready VMware alternative have one opportunity to make a single platform decision. The harder requirement is picking the platform that eliminates the need for another infrastructure decision eighteen months from now.
Take a VergeOS Test Drive and see how virtual machines, Kubernetes, GPU virtualization, and VergeIQ operate on a single platform. Greg Campbell and former VMware CTO Kit Colbert walk through the architecture live on June 11. Registration is open.
 That plan made sense in 2024. The renewal was expensive but predictable — Broadcom had only completed the acquisition a year earlier, many organizations still had time remaining on existing contracts, and buying one more year to evaluate alternatives was a reasonable call. The servers were a known quantity. The budget math was uncomfortable but manageable. What changed is not the plan — it is the price of executing it. The two line items that seemed controllable have both moved against you at the same time, and the combined number no longer looks like buying time. It looks like paying a premium to stay on a platform you have already decided to leave.
That plan made sense in 2024. The renewal was expensive but predictable — Broadcom had only completed the acquisition a year earlier, many organizations still had time remaining on existing contracts, and buying one more year to evaluate alternatives was a reasonable call. The servers were a known quantity. The budget math was uncomfortable but manageable. What changed is not the plan — it is the price of executing it. The two line items that seemed controllable have both moved against you at the same time, and the combined number no longer looks like buying time. It looks like paying a premium to stay on a platform you have already decided to leave. The server market shifted in late 2024 and has not corrected. DRAM contract prices rose 58–63% quarter over quarter in the first half of 2026, driven by AI infrastructure buildout at the hyperscaler level that locked up supply before enterprise buyers could compete. This cycle has been characterized as a
The server market shifted in late 2024 and has not corrected. DRAM contract prices rose 58–63% quarter over quarter in the first half of 2026, driven by AI infrastructure buildout at the hyperscaler level that locked up supply before enterprise buyers could compete. This cycle has been characterized as a 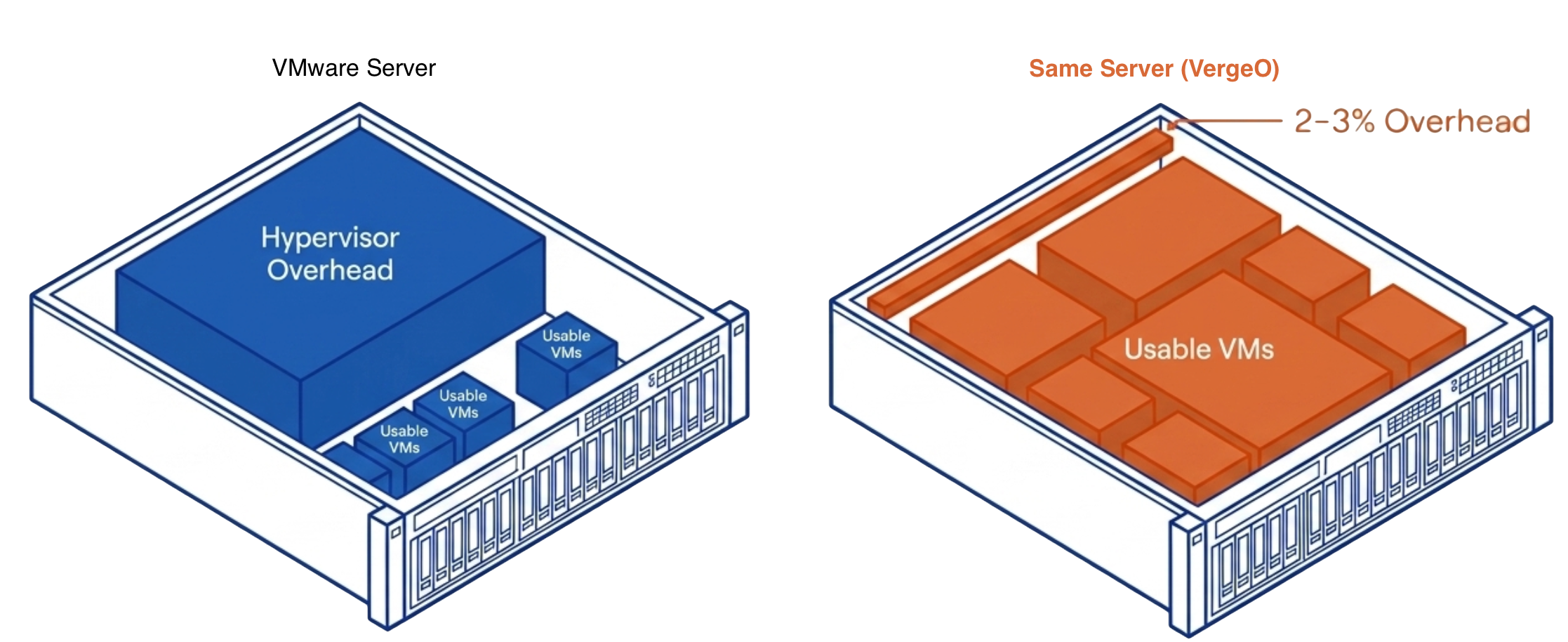 VergeOS changes the math at every layer where the conventional path breaks down. The starting point is hardware: VergeOS installs on any x86 server already in the data center. The servers the organization was planning to buy are no longer required. The $40,000 nodes, the three-to-six-month lead times, the OEM quote that expires before the purchase order clears — none of that applies. The migration starts on the day the organization decides to move, on hardware already powered on and already running workloads.
VergeOS changes the math at every layer where the conventional path breaks down. The starting point is hardware: VergeOS installs on any x86 server already in the data center. The servers the organization was planning to buy are no longer required. The $40,000 nodes, the three-to-six-month lead times, the OEM quote that expires before the purchase order clears — none of that applies. The migration starts on the day the organization decides to move, on hardware already powered on and already running workloads.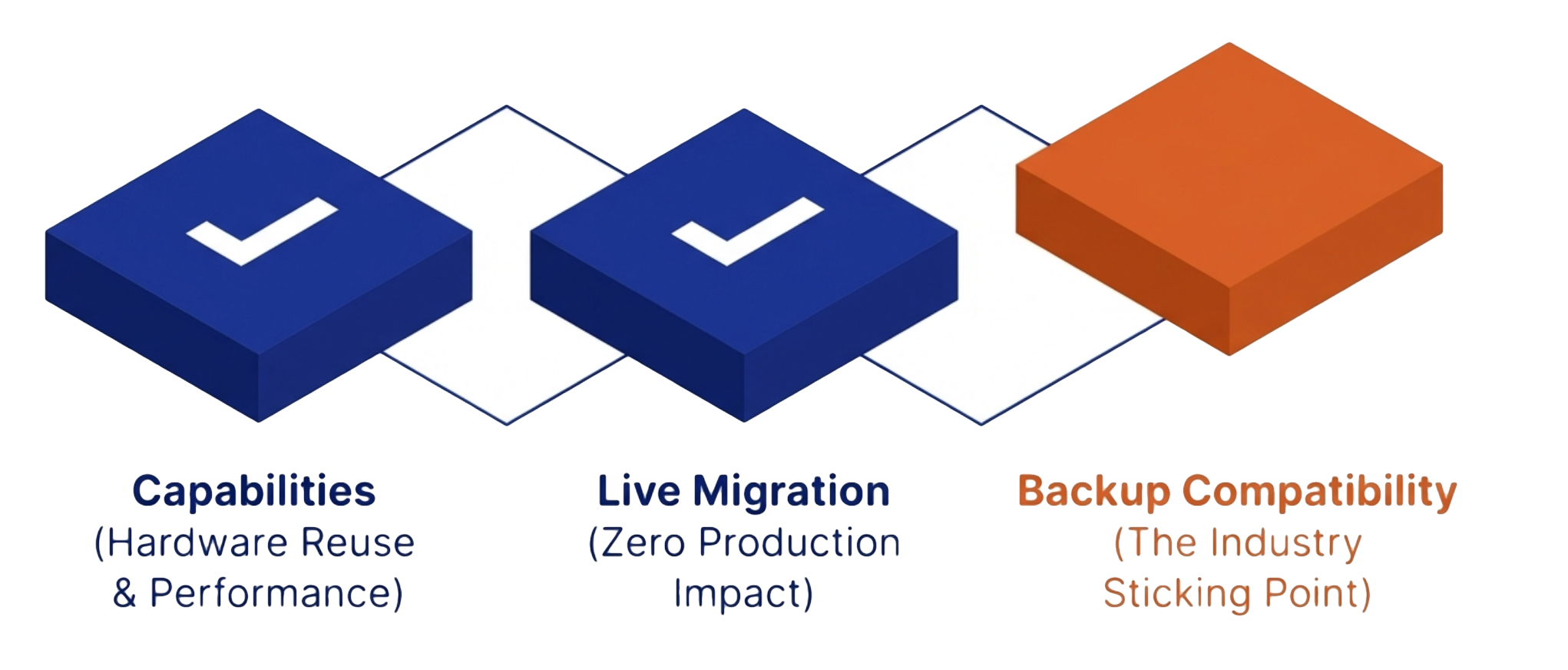
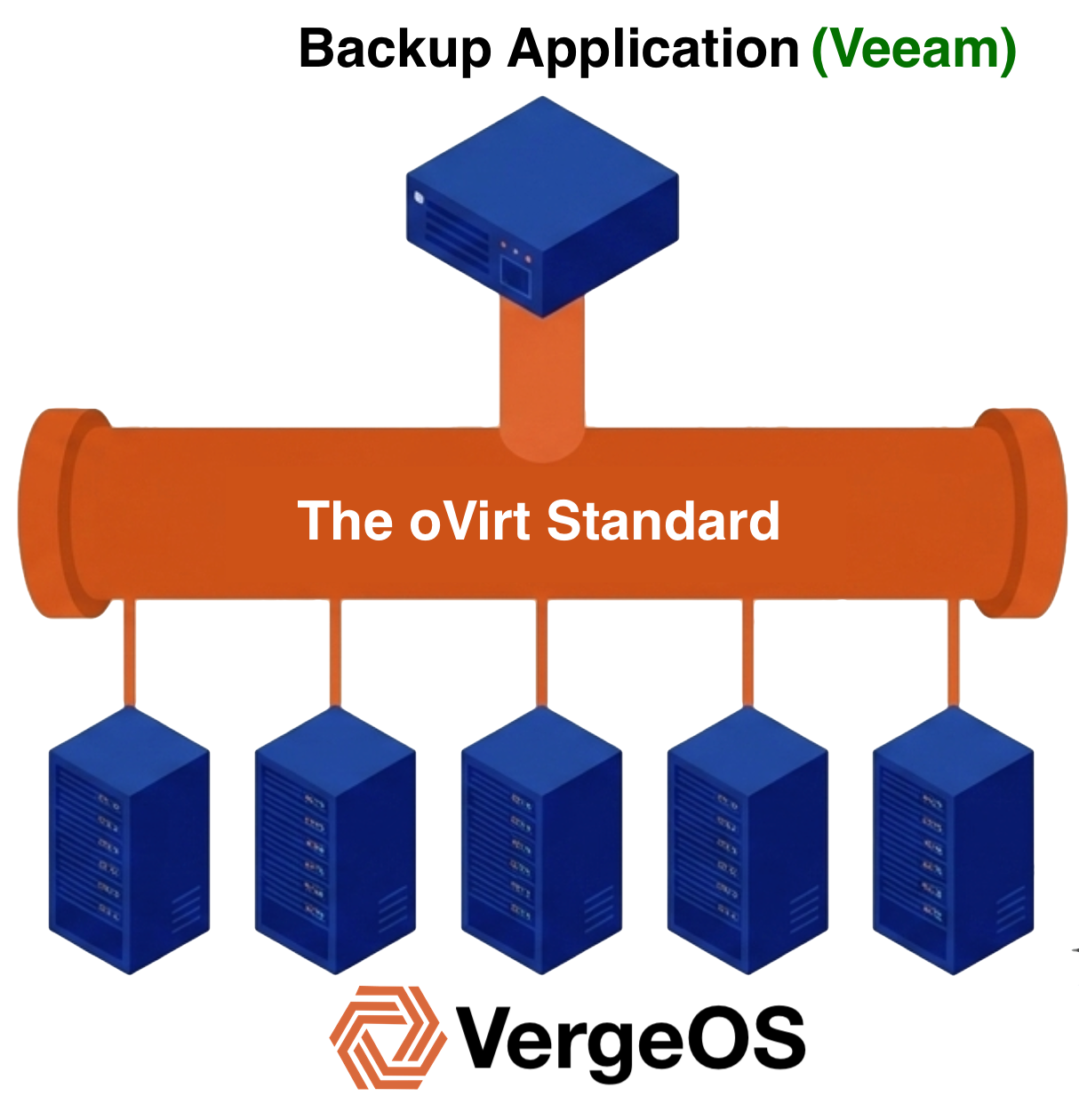 The oVirt API is the established interface for KVM-based virtualization environments. VergeIO did not invent it. No single backup vendor created it. It emerged as an industry decision, a deliberate architectural strategy by major backup vendors to support the growing ecosystem of open-source hypervisor platforms through a single, common interface.
The oVirt API is the established interface for KVM-based virtualization environments. VergeIO did not invent it. No single backup vendor created it. It emerged as an industry decision, a deliberate architectural strategy by major backup vendors to support the growing ecosystem of open-source hypervisor platforms through a single, common interface. It would have been nice to have oVirt compatibility on day one, however, the delay created an unexpected advantage. Without a third-party backup integration to lean on, VergeIO took on the responsibility of building advanced, industry-leading data availability, protection and disaster recovery capabilities directly into the VergeOS platform.
It would have been nice to have oVirt compatibility on day one, however, the delay created an unexpected advantage. Without a third-party backup integration to lean on, VergeIO took on the responsibility of building advanced, industry-leading data availability, protection and disaster recovery capabilities directly into the VergeOS platform.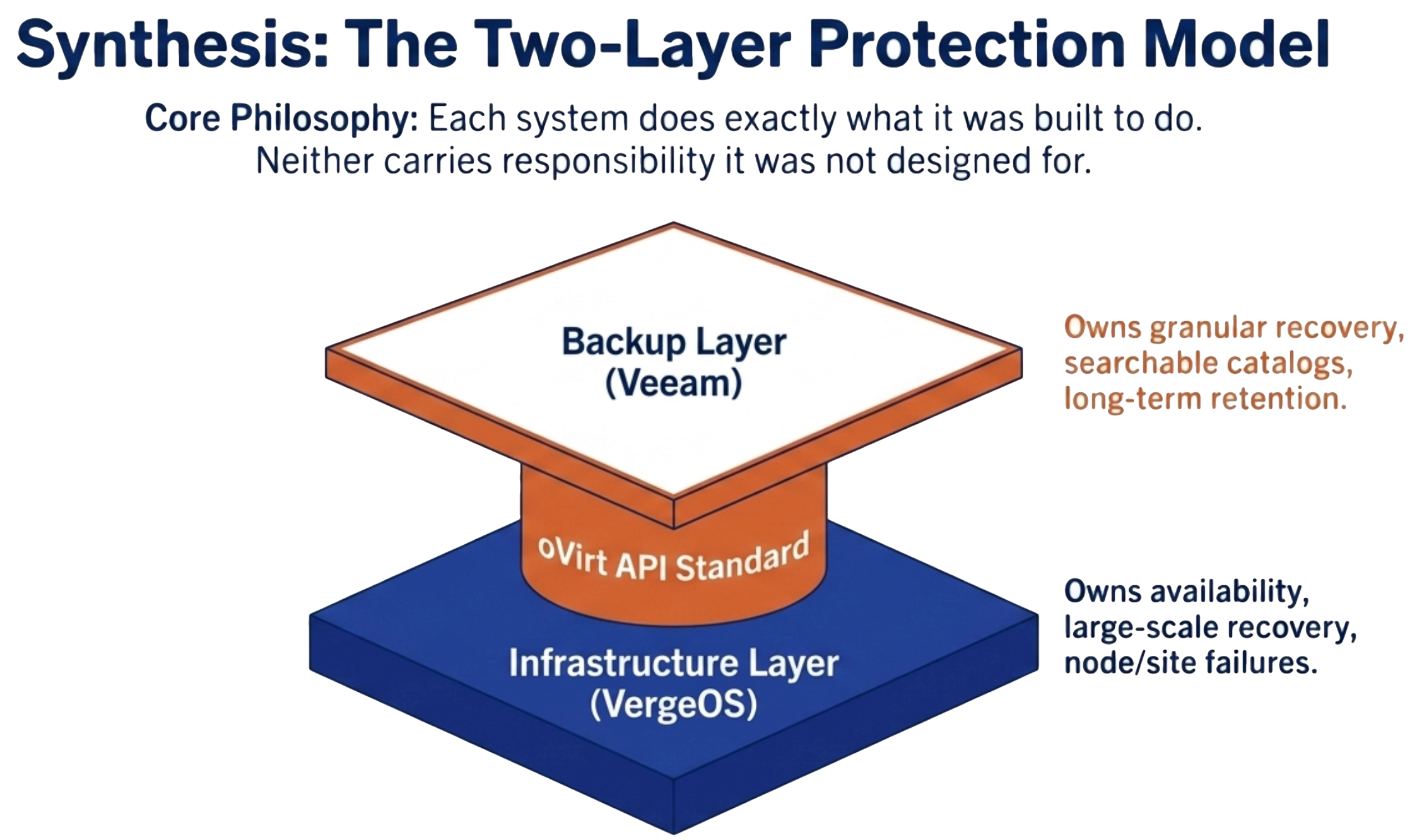 The integration is straightforward. An oVirt-compatible backup platform, like Veeam connects to VergeOS without modification on either side. No custom plugin. No professional services engagement. No changes to existing backup policies, schedules, or SLA tiers.
The integration is straightforward. An oVirt-compatible backup platform, like Veeam connects to VergeOS without modification on either side. No custom plugin. No professional services engagement. No changes to existing backup policies, schedules, or SLA tiers.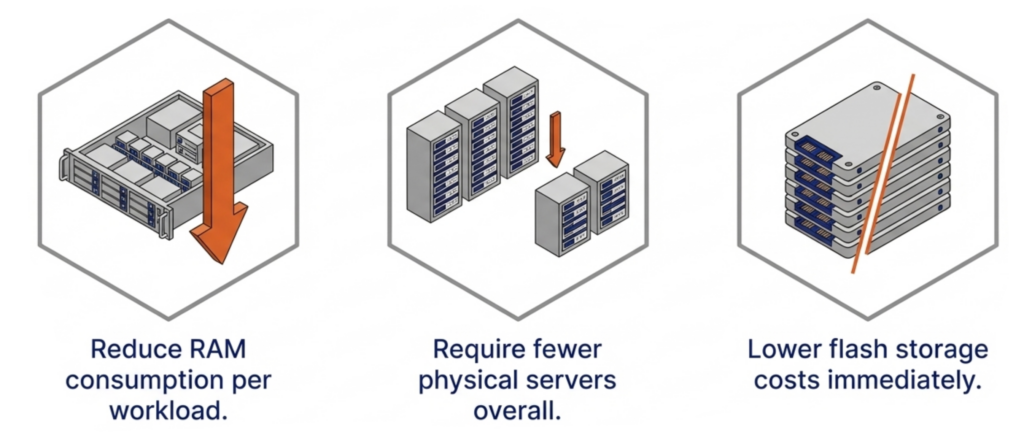 DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.
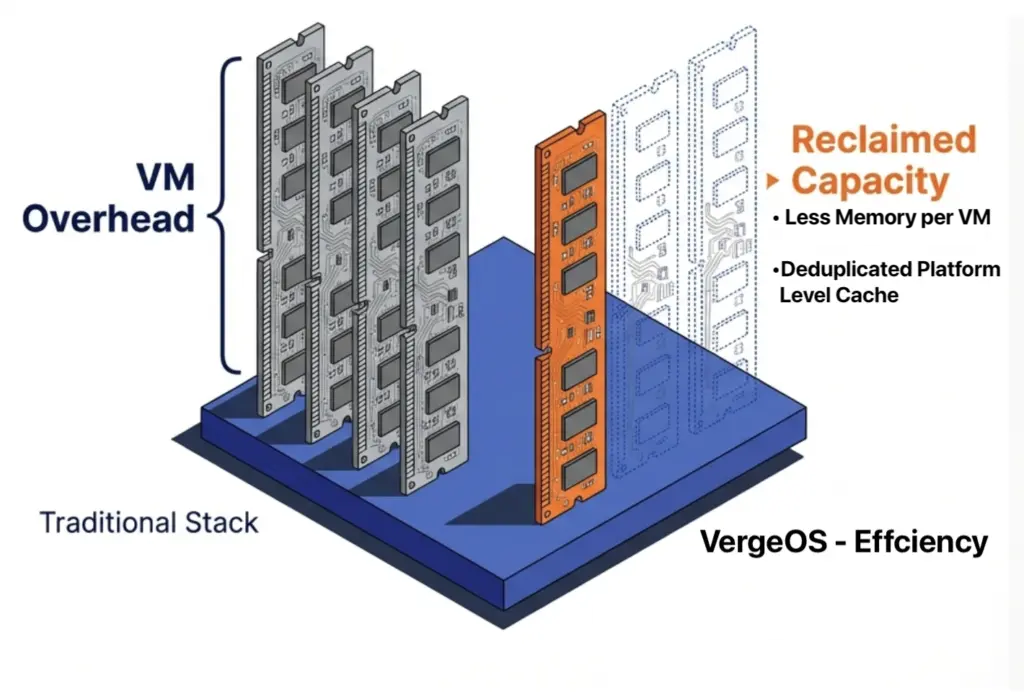
DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.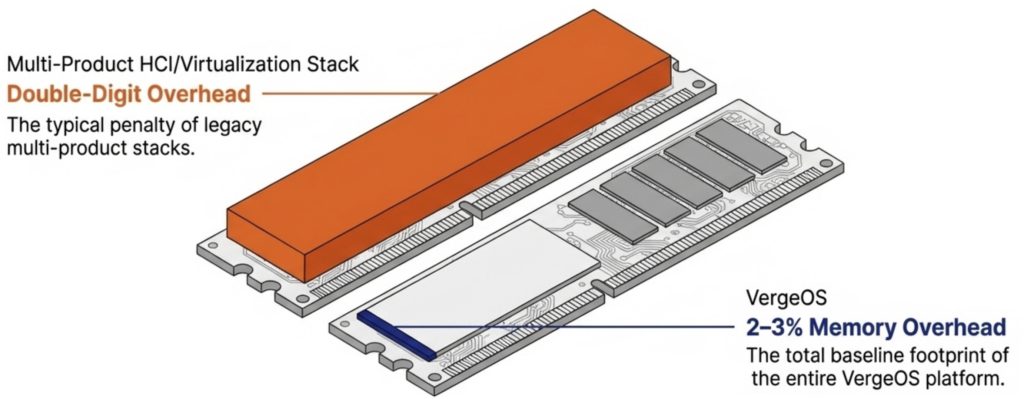 It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.
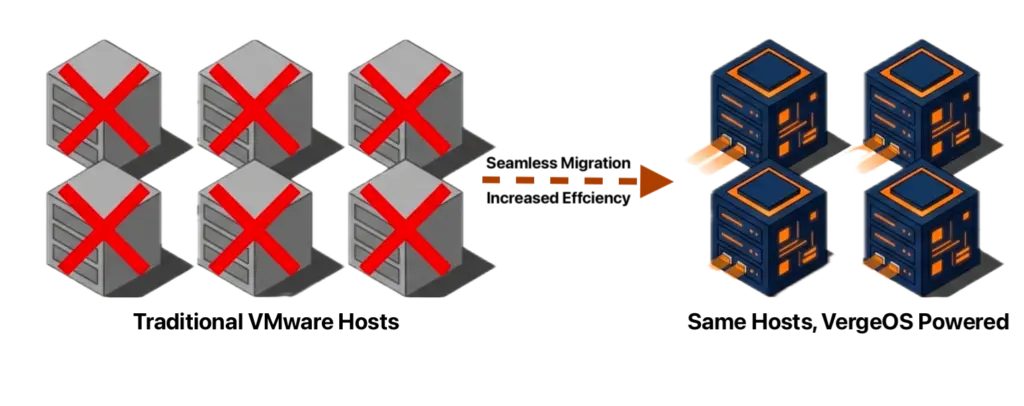
It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.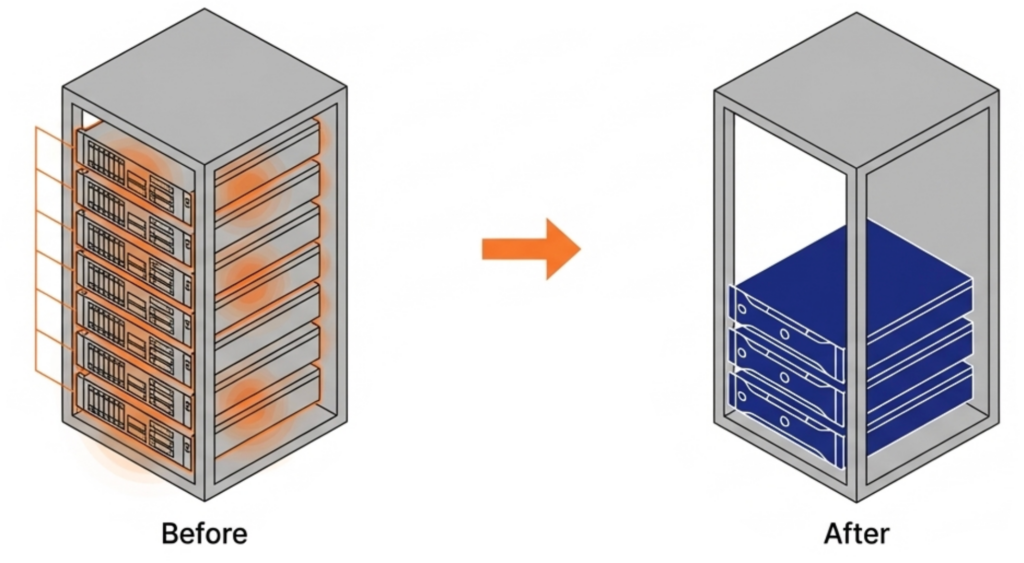 VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production.
VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production.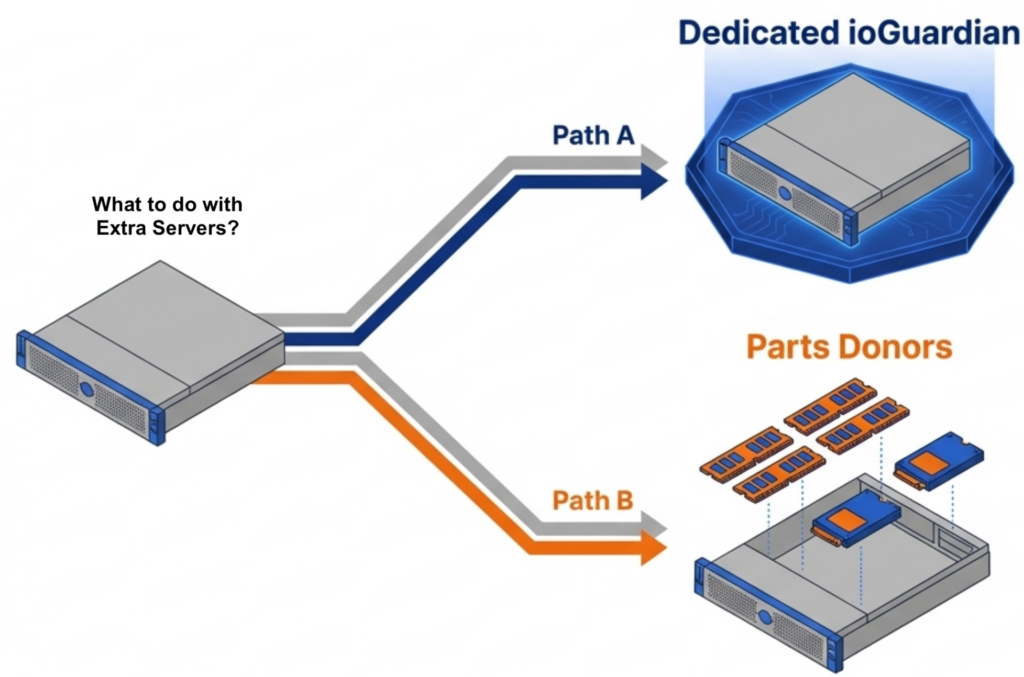 The consolidation math works across an entire fleet. An organization running 100 six-node VMware clusters that consolidates to 100 three-node VergeOS clusters frees 300 servers for repurposing, retirement, or spare parts — during a supercycle where replacement hardware is both expensive and slow to ship.
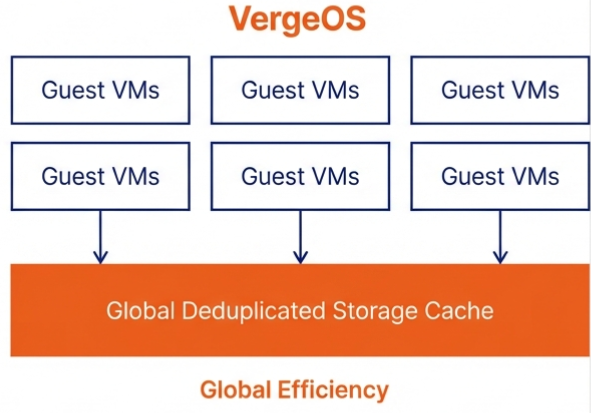
The consolidation math works across an entire fleet. An organization running 100 six-node VMware clusters that consolidates to 100 three-node VergeOS clusters frees 300 servers for repurposing, retirement, or spare parts — during a supercycle where replacement hardware is both expensive and slow to ship.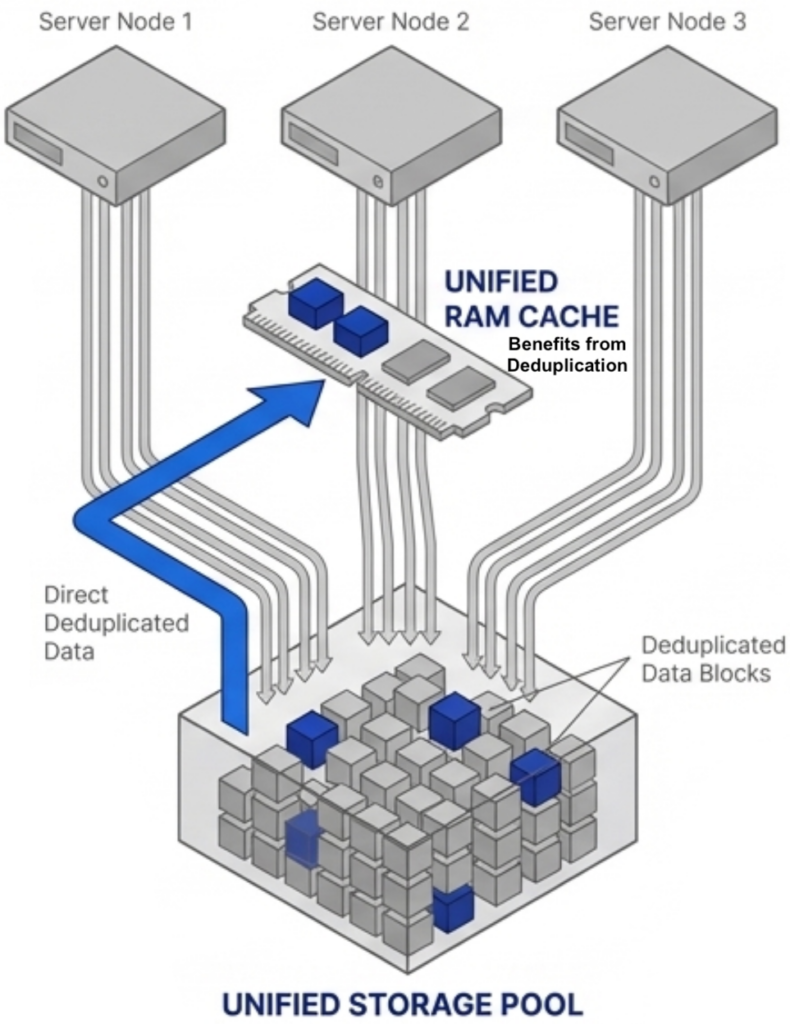 Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.
Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.