The question came up during our webinar on the flash and memory supercycle, and it is worth a full answer. If flash is expensive and scarce, do hard drives provide a way out? The short answer is no. The longer answer explains why — and points to a better path forward.
Key Takeaways
- Hard drives are not an escape from the flash and memory supercycle — HDD supply is tightening for the same reason flash supply is: AI infrastructure demand.
- RAM is the root cause. Every VMware host consumes tens of gigabytes before a single VM starts, thereby increasing cost pressures on both DRAM and flash simultaneously.
- The supercycle is a consumption problem, not a capacity problem. Platforms that waste flash and RAM are the issue — adding cheaper storage does not fix wasteful architecture.
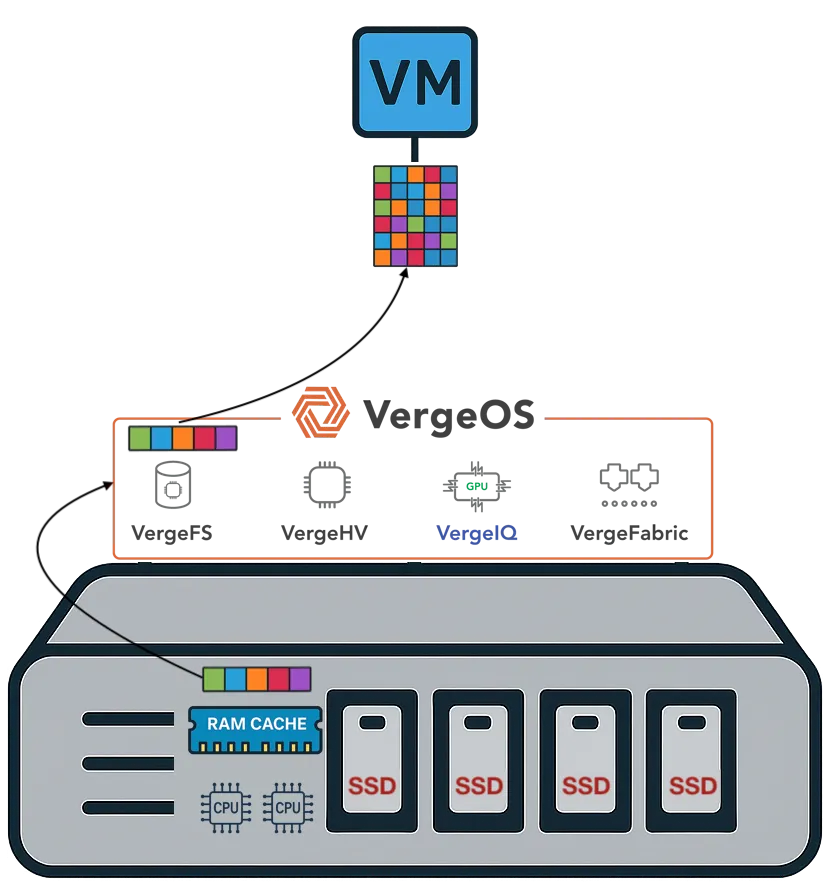
- VergeOS global inline deduplication runs before data is written, reducing flash consumption at the storage layer and enabling the cache to hold only unique data blocks.
- Hard drives still have a legitimate role for cold archive data and predictable tiering — VergeOS supports live VM migration between storage tiers, including HDD.
The Appeal Is Understandable
Hard drives are cheap relative to flash and seem like a viable solution to the flash and memory supercycle. A petabyte of spinning disk still costs a fraction of an equivalent flash footprint. If your flash capacity is constrained by price or supply, adding hard drives looks like a logical pressure valve.
Key Terms
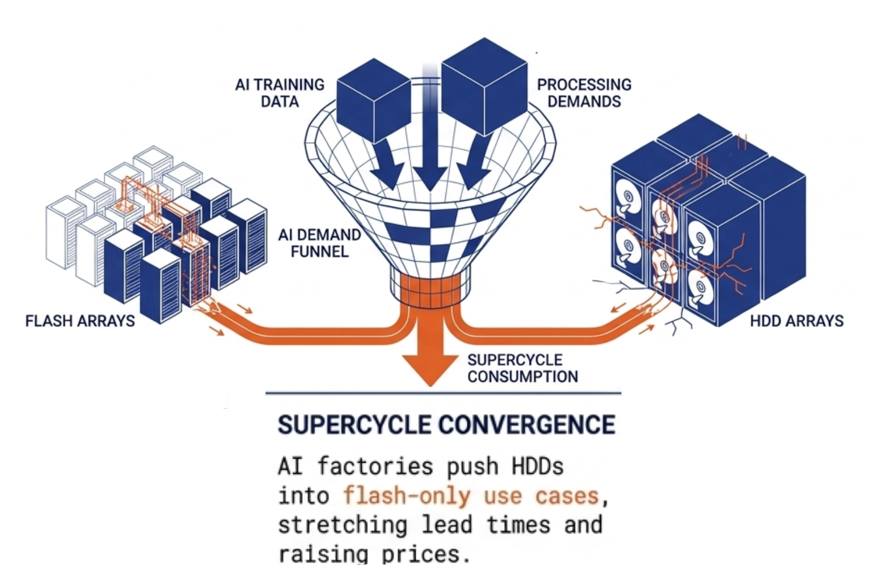
The problem is that the valve is closing. HDD supply is tightening alongside flash supply. AI infrastructure is consuming hard drives for training data storage at the same pace it consumes flash for active workloads. As flash supply continues to tighten, AI factories are pushing hard drives into use cases that were previously flash-only. HDD prices are rising and lead times are stretching. The supply chain disruption that created the flash supercycle is now touching spinning disk as well.
Hard drives are not an escape from the supercycle. They are increasingly part of it.
HDDs Never Really Left the Performance Problem
IT moved away from day-to-day HDD use for good reasons. Hard drives are slow. Latency is measured in milliseconds, not microseconds. Performance is unpredictable under mixed workloads. A single failed drive forces a rebuild that hammers performance across the entire array for days. Flash wears out, but flash failure is trackable and trending — you can see it coming. A hard drive can fail without warning on a Tuesday afternoon.
Tiering helps, but only at the margins. Automated tiering moves older data down to spinning disk based on access age. The formula assumes that data will rarely, if ever, become active again. That is not reality. When dormant data becomes active, users want it now, regardless of how old it is. For anything IT actually touches — active VMs, databases, application data — hard drives create performance unpredictability that most organizations cannot accept.
Manual tiering through live migration of workloads across storage tiers gives more control than age-based automation. VergeOS supports live migration of VMs between storage tiers, including hard disk tiers, and that capability is especially useful when performance spikes are predictable. With VergeOS automation, you can script moving a VM to an HDD tier when its I/O demands are low and back to flash before demand heats up. Even if that happens daily, live VM migration with automation makes it operationally trivial — and the performance impact is barely noticeable.
RAM Is the Root Cause of the Flash and Memory Supercycle

Before addressing flash consumption, it is worth establishing why the flash and memory supercycle are connected problems. RAM is at the center of both.
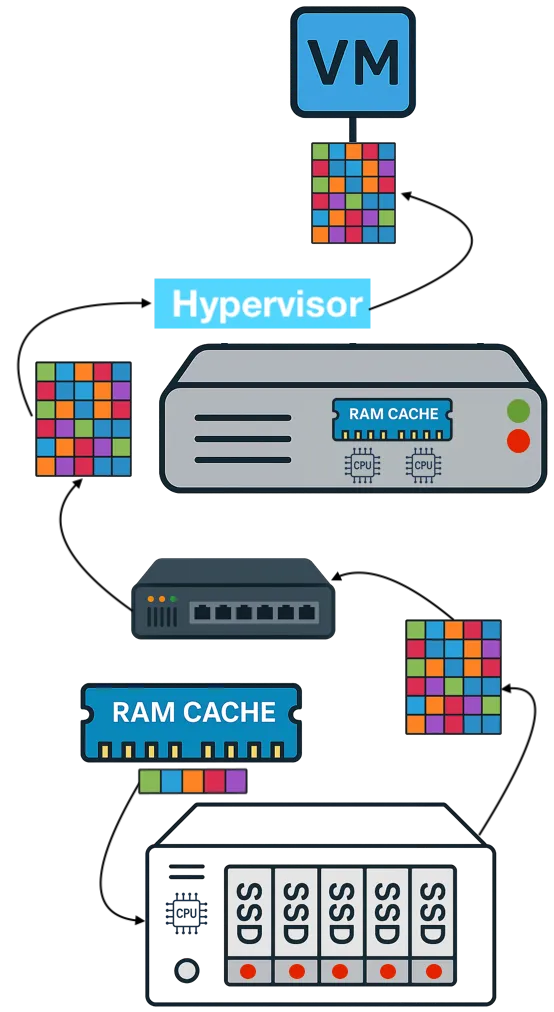
DRAM prices are up 171% year-over-year and analysts project that pressure extending through 2027 and beyond. Every VMware host consumes significant RAM before a single VM starts. vSphere, vSAN, vCenter, and NSX together consume tens of gigabytes of platform overhead per host. Organizations running VMware on flash-heavy HCI configurations face a compounding problem: they are paying inflated prices for the RAM that runs the stack and inflated prices for the flash the stack writes to.
VergeOS attacks RAM consumption at the platform level. The entire VergeOS stack — hypervisor, storage, networking, and data protection — runs at 2–3% memory overhead. Global inline deduplication ensures that only unique data blocks are added to the read cache. Because the underlying storage pool is already deduplicated before data reaches the cache, the cache naturally holds only unique blocks without running a separate deduplication algorithm. That same cached block can then serve dozens of VMs simultaneously across every node in the cluster. The result is greater cache effectiveness per gigabyte of RAM, meaning organizations get more workload capacity from existing servers without forcing a server refresh at supercycle prices. We cover the full scope of what the supercycle means for infrastructure economics here.
The Second Flash and Memory Supercycle Problem: Consumption
The drive portion of the flash and memory supercycle is not primarily a capacity problem. It is a consumption problem. Platforms built on VMware consume more flash than necessary — because of virtualization overhead, because of how data is written, because of the architectural assumptions baked into virtualization stacks that were designed when flash was cheap and plentiful.
If you reduce the amount of flash your infrastructure consumes, you need less of it. That changes the economics without depending on hard drives to fill the gap. We looked at exactly how much more expensive a traditional storage refresh has become in The Even Higher Cost of a Storage Refresh in 2026.
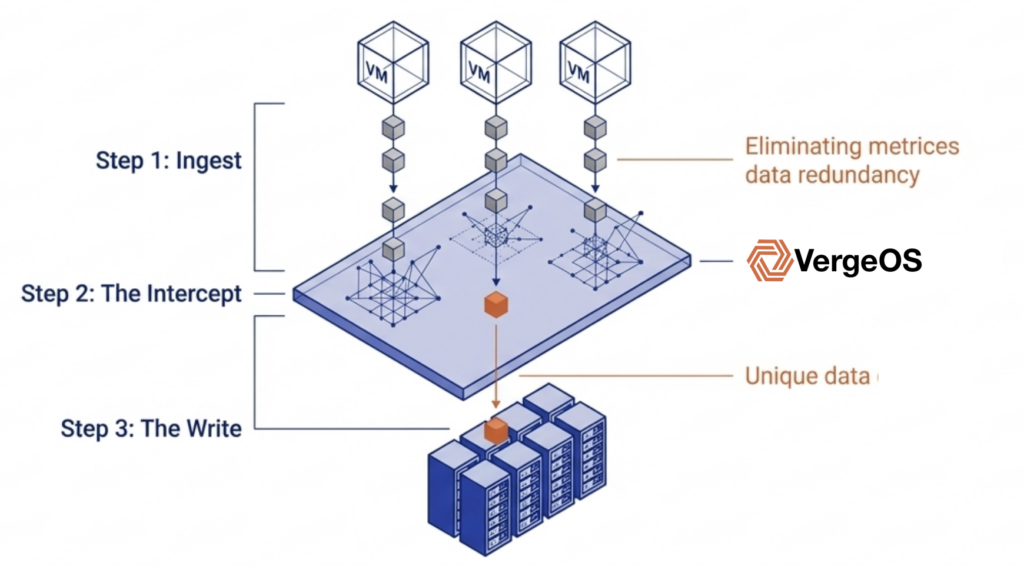
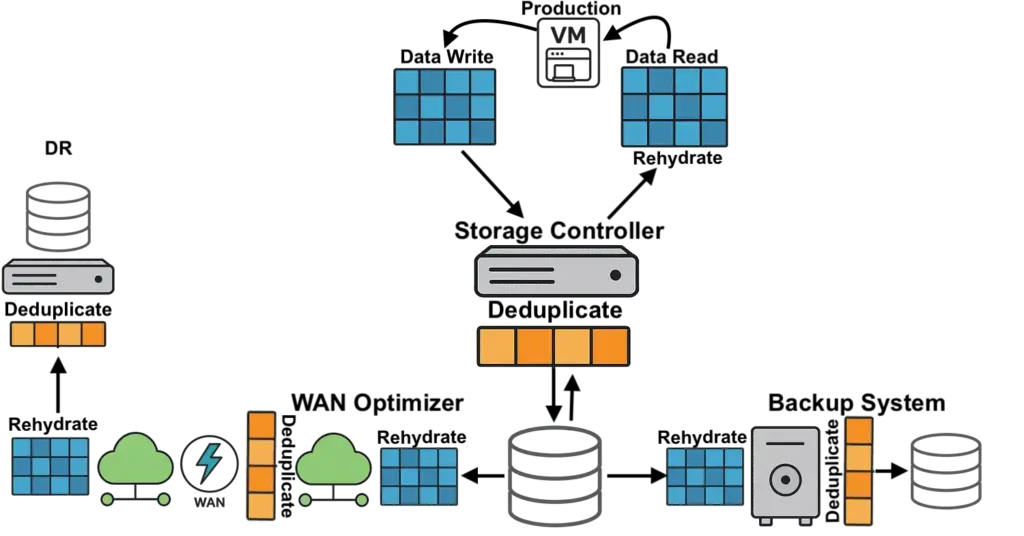
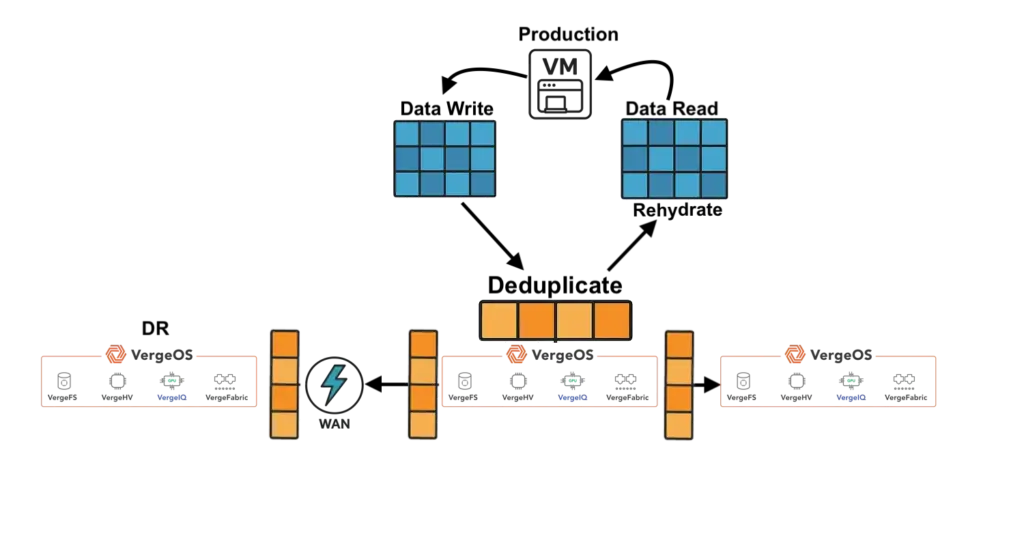
VergeOS addresses flash consumption directly. Global inline deduplication runs at the storage layer before data is written. Because the storage pool is already deduplicated, the read cache naturally holds only unique data blocks. That cache is global — the same cached block serves dozens of VMs simultaneously across all nodes in the cluster. Topgolf reduced storage from 20 TB per venue to 5 TB per node — not by adding hard drives, but by eliminating redundant data before it ever reached the drive. Alinsco Insurance migrated off VMware and vSAN onto the same VxRail hardware with the same internal SSDs and gained capacity headroom without adding a single drive.
That is the answer the flash-and-memory supercycle actually calls for. Not cheaper storage on the bottom of a tiered stack, but a platform that requires less storage at every tier.
Hard Drives Still Have a Role
This is not an argument against hard drives entirely. Your infrastructure — whether an ultraconverged solution like VergeOS or a dedicated array — should support HDDs as a tier. As discussed with live VM migration between tiers, the performance impact of an HDD recall can be minimized, particularly when performance demands are predictable. Cold archive data, backup target storage, compliance archives, and long-retention datasets are all appropriate candidates for HDD tiers. If your infrastructure has a genuine cold data problem, tiering to hard drives is a sound approach.
The mistake is expecting hard drives to solve a hot data efficiency problem. Your active workloads do not care that HDDs are cheaper. They care about latency and consistency. As HDD supply tightens alongside flash, even the cost saving argument weakens.
What Actually Solves the Flash and Memory Supercycle
The organizations navigating the flash and memory supercycle without major budget pain share a common trait: they run platforms that consume less of what is scarce. Less RAM per workload. Less flash per VM. Fewer servers per site. Data availability and protection capabilities that let them run safely on refurbished hardware — servers and storage — without the risk of workload outages or data loss. The next five years of IT infrastructure will be defined by exactly this kind of platform flexibility. You need to run infrastructure that requires less.
VergeOS was built with this efficiency at its core — not as a feature added after the fact, but as an architectural decision that affects every layer from the hypervisor to the storage pool to the network. The supercycle exposed the cost of platforms that were not built this way. Hard drives do not fix that. A more efficient platform does.
Will hard drive prices come down as flash prices rise?
Can I use hard drives in a VergeOS cluster?
What is automated tiering and does it actually solve the flash supercycle problem?
How does VergeOS reduce flash consumption?
Is it safe to run VergeOS on refurbished hardware?
Not reliably. HDD demand is rising in parallel with flash demand because AI infrastructure is consuming spinning disk for training data storage at scale. Lead times are stretching and prices are rising across both storage types. The supply chain disruption that created the flash supercycle is now touching HDDs as well. Waiting for prices to normalize on either front is not a strategy.
Yes. VergeOS supports mixed storage configurations including HDD tiers within the same cluster. You can use hard drives for cold archive data, backup targets, or tiered workloads. VergeOS supports live migration of VMs between storage tiers — including moving a VM from flash to HDD and back — with automation that makes the transition operationally transparent.
Automated tiering moves data from faster flash storage to slower hard disk storage based on access age. It is useful for genuinely cold data, but does not solve the supercycle problem. Your hot data tier is still flash, flash is still expensive, and automated tiering does nothing to reduce how much flash your platform consumes. The supercycle is a consumption problem. Tiering is a placement strategy.
VergeOS runs global inline deduplication at the storage layer before data is written to disk. Because the underlying storage pool is already deduplicated, the read cache naturally holds only unique data blocks — without running a separate deduplication algorithm inside the cache. That same cached block serves dozens of VMs simultaneously across all nodes in the cluster. The result is fewer total writes to flash, lower effective capacity requirements, and dramatically better cache hit rates per gigabyte of installed storage.
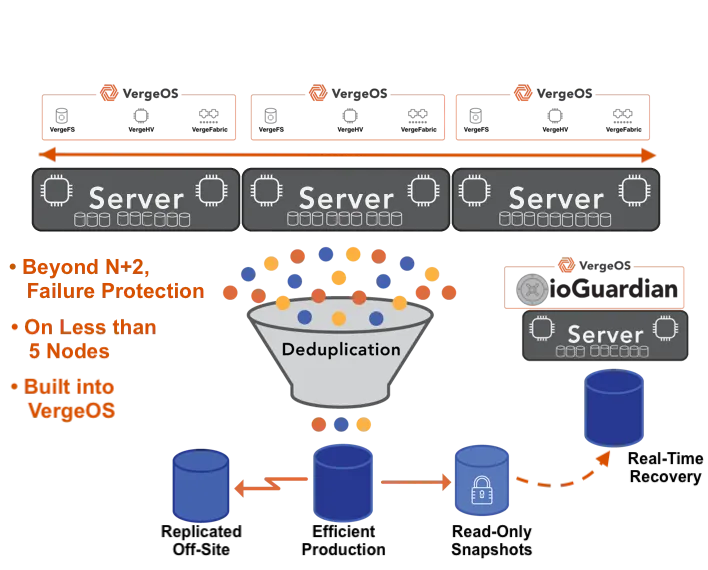
Yes. VergeOS is designed to run safely on commodity and refurbished x86 hardware, including refurbished NVMe drives. Global inline deduplication reduces total writes per drive, directly extending drive life. ioGuardian provides RF2+/RF3+ data protection via synchronous replication — when a drive fails, surviving copies serve data at full speed with no reconstruction and no degraded mode. The combination of reduced write load and fault-tolerant replication makes refurbished hardware production-safe.
 DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.
DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.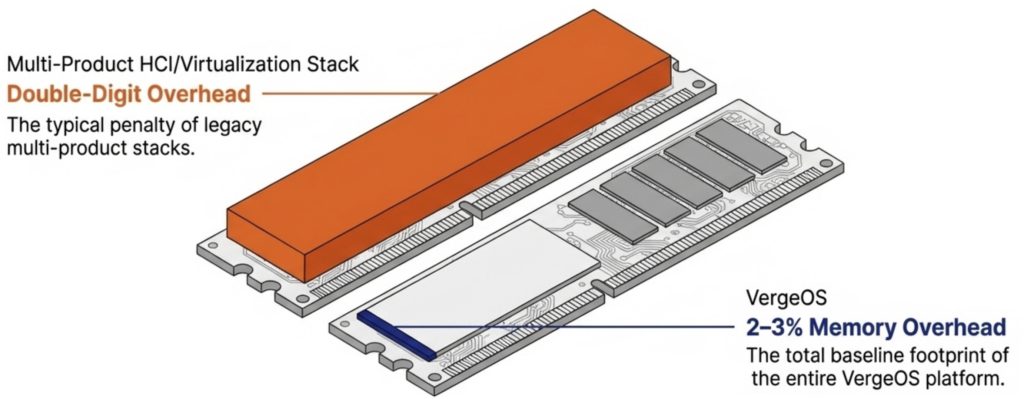 It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.
It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.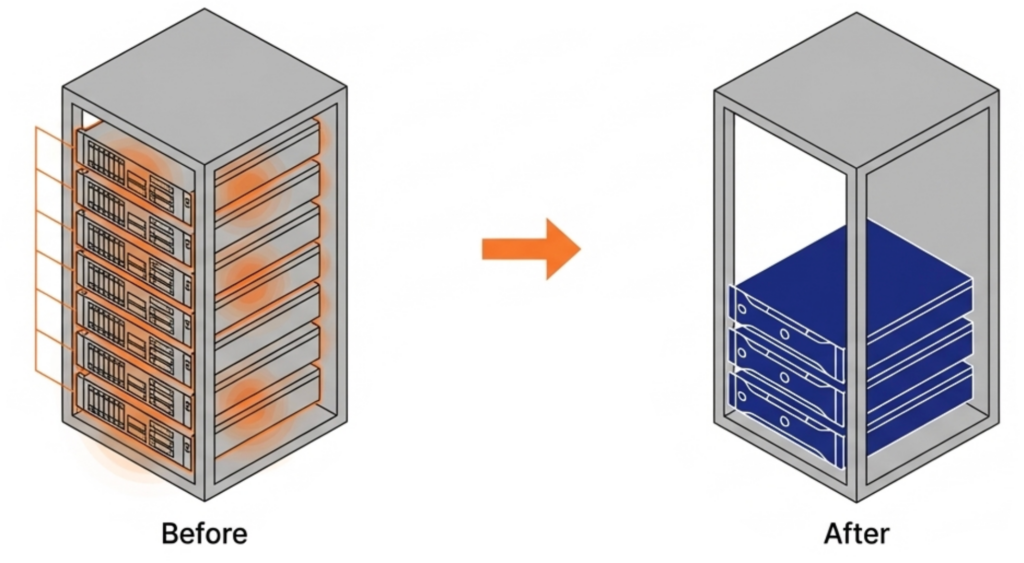 VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production.
VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production. The consolidation math works across an entire fleet. An organization running 100 six-node VMware clusters that consolidates to 100 three-node VergeOS clusters frees 300 servers for repurposing, retirement, or spare parts — during a supercycle where replacement hardware is both expensive and slow to ship.
The consolidation math works across an entire fleet. An organization running 100 six-node VMware clusters that consolidates to 100 three-node VergeOS clusters frees 300 servers for repurposing, retirement, or spare parts — during a supercycle where replacement hardware is both expensive and slow to ship.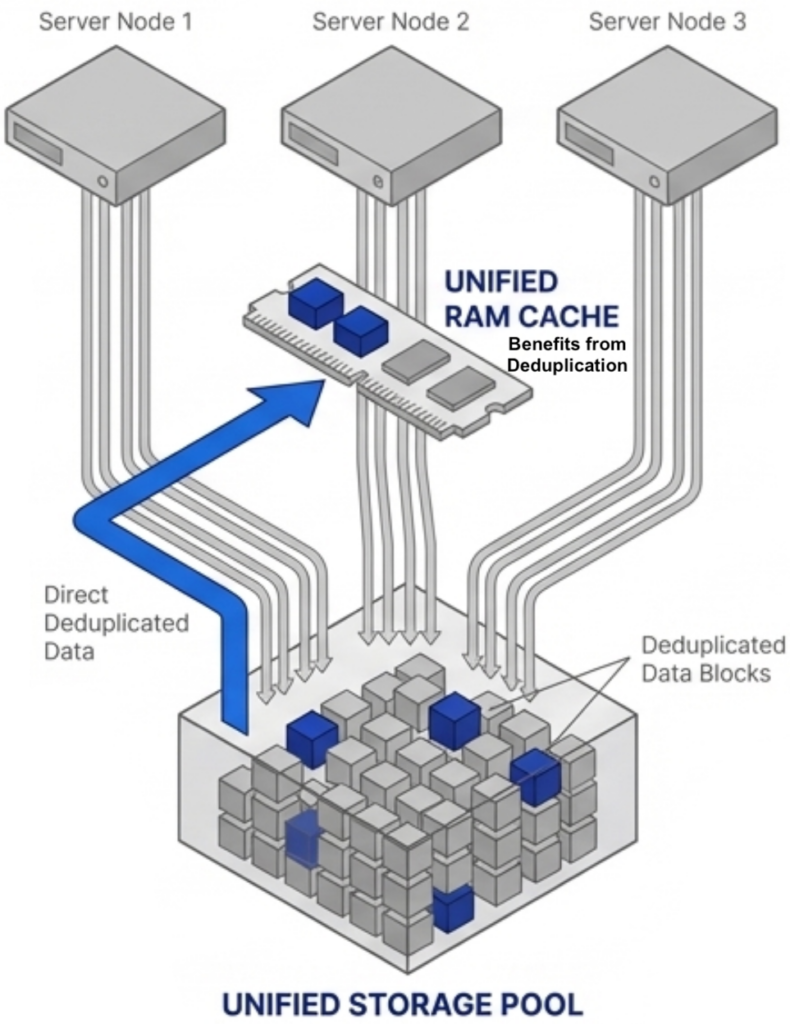 Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.
Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.