Warsaw, Poland – September 24, 2024 – Storware, a European leader in enterprise data backup and recovery, renowned for its stability and seamless integration capabilities, has announced a strategic partnership with VergeIO, the leading provider of ultraconverged infrastructure. This collaboration addresses the growing market demand for turnkey solutions that deliver an integrated data center operating environment with end-to-end backup, disaster recovery, and robust protection against ransomware.
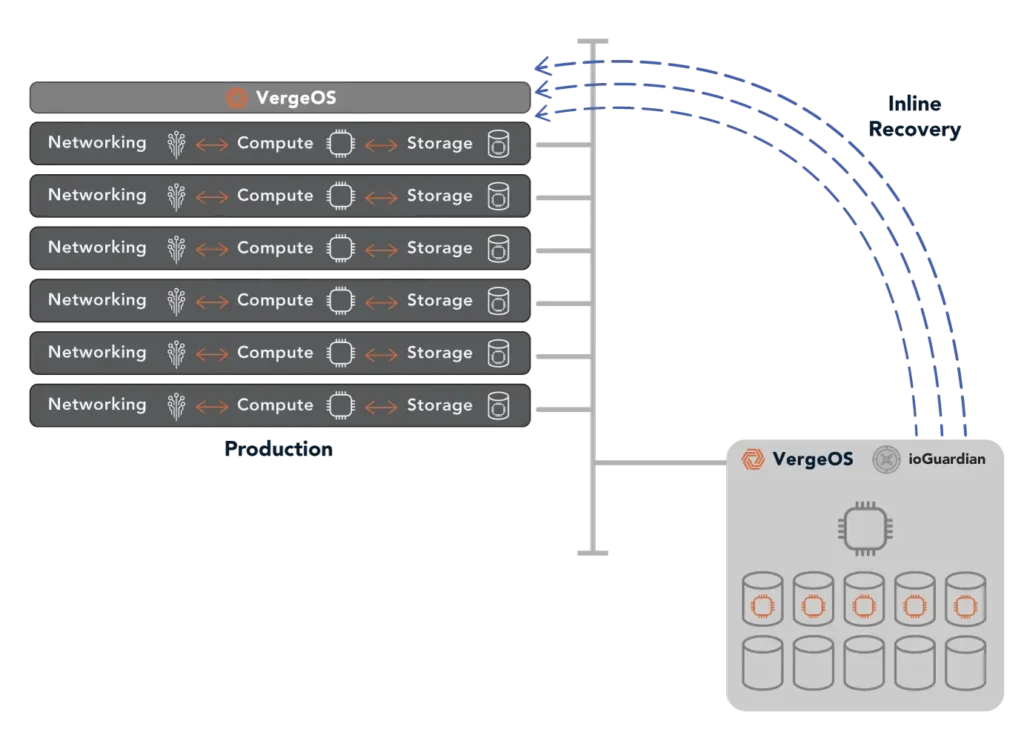
VergeIO, a pioneer in VMware alternatives, offers effortless solutions for deploying powerful platforms using existing hardware while enhancing data resiliency and performance. The VergeOS software is more than just a VMware alternative—it provides superior efficiency, leading to better performance, scalability, hardware resiliency, upfront cost savings, and significant long-term reductions in total cost of ownership (TCO). The flexible, hardware-agnostic approach simplifies project launches with minimal technical setup while maintaining high availability and workload scalability.
The collaboration between Storware and VergeIO strengthens data security, ensuring confidentiality and business continuity. This partnership offers significant benefits for businesses of all types and sizes, enabling them to build robust infrastructures for a wide range of environments, including secure research (HPC), hyperconverged data centers, and multi-tenant private clouds.
Key Benefits of the Partnership:
- A unified solution for simplifying data center virtualization and infrastructure management.
- Enables organizations to build or scale IT environments using end-to-end software rapidly, minimizing costs and deployment times.
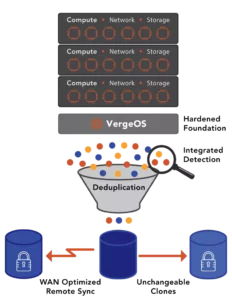
- Storware Backup and Recovery integrates seamlessly with VergeOS, offering a centralized console for managing backup tasks while supporting the creation of fully encapsulated virtual data centers.
- The hardware-agnostic infrastructure supports evolving business demands and accelerates growth.
- Significant reduction in total cost of ownership (TCO) as environments scale.
“The Storware-VergeIO partnership is not just about collaboration; it’s about creating synergy between innovation and expertise to accelerate technological transformation,” said Jan Sobieszczanski, CEO of Storware. “We’re excited to offer a joint solution that combines VergeOS’ unique ultraconverged infrastructure with Storware’s powerful Backup and Recovery capabilities. Together, we’re ready to tackle emerging market challenges head-on.”
Yan Ness, CEO of VergeIO, added, “Integrating Storware Backup and Recovery with VergeOS provides customers with confidence as they transition from VMware. The combined solution enhances cybersecurity with rapid backups, including incremental and differential backups, granular recovery options, and automated backup scheduling. This partnership makes virtualization and moving to fully functional, resilient virtual data centers a turnkey solution.”
About VergeIO
VergeIO is the future of virtualization and the leading VMware alternative. Unlike hyperconverged infrastructure (HCI), VergeIO’s ultraconverged infrastructure (UCI) collapses the traditional IT stack (compute, storage, and networking) into a single, integrated data center operating environment: VergeOS. This approach allows organizations to achieve greater workload density, improved data resiliency and simplified IT management using their existing hardware—resulting in lower costs and higher availability. VergeOS delivers better performance, scalability, hardware resiliency, and significant upfront and long-term cost savings.
For more information, visit www.verge.io.
About Storware
Storware is a European enterprise data backup and recovery solutions provider recognized for its stability and comprehensive platform integration. Storware secures data across virtual machines, containers, cloud environments, and applications, including Microsoft 365. It supports a variety of backup destinations, such as file systems and object storage, and acts as a proxy for enterprise backup providers. Established in 2013 in Warsaw, Poland, Storware continues expanding its reach through a robust global distribution and partner network.
Connect with Storware on Facebook, LinkedIn, or visit storware. eu for more information.
Media Contacts:
Tasha Kobzarenko
Product Marketing Manager, Storware
[email protected]
Judy Smith
JPR Communications, representing VergeIO
[email protected]
(818) 522-9673