Storage vendors force you to replace your storage system every four to five years, so understanding the total cost of SAN replacement is critical for IT professionals to learn. After all, replacing a SAN (storage area network) or NAS (network attached storage) has more expenses than just buying the new hardware.
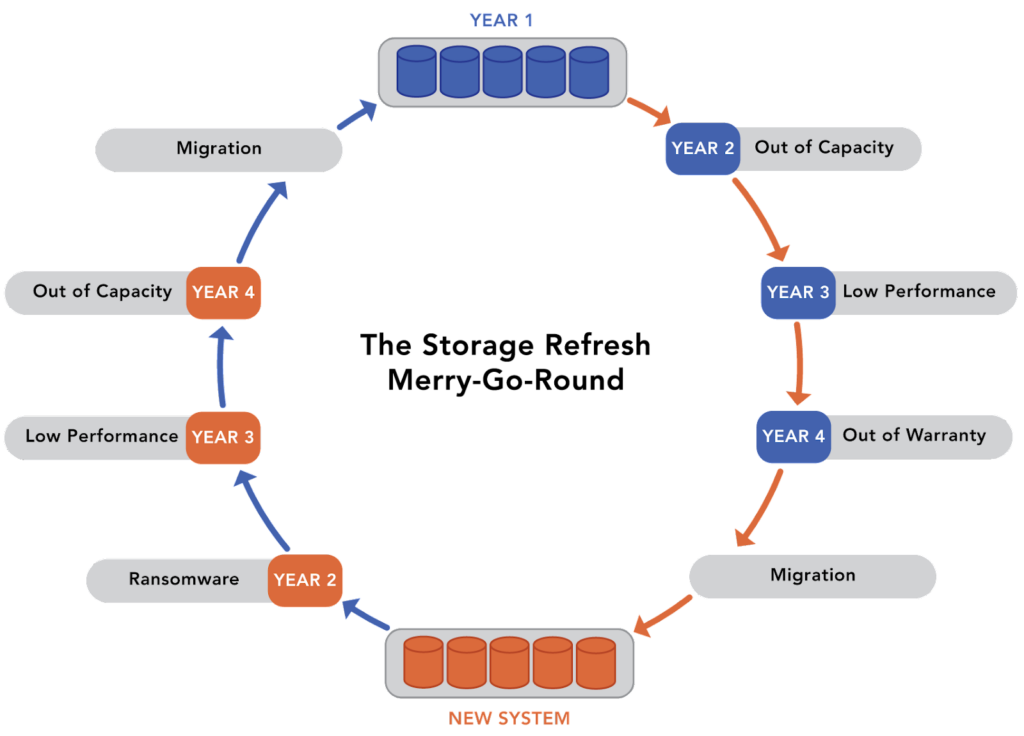
There are many reasons for replacing a SAN or a NAS. At the top of the list are artificial end-of-life, inability to meet new performance or capacity demands, lack of flexibility to support new hardware innovations, and inadequate protection from new, modern threats like ransomware. The result is a never-ending storage refresh merry-go-round.
There are five components to understanding the total cost of replacing a SAN:
1. The Cost of SAN Identification
The first element of the total cost of replacing a SAN is identifying a set of potential storage replacement candidates. The IT team has to play the role of storage industry analyst to find the right storage system to meet their current and future needs. When done correctly, this process can take weeks; when done hastily, this process can lead to the purchase of a storage system that doesn’t quite meet the current requirements or is more expensive than necessary. Since most IT staffs are shorthanded and stretched too thin, the chances of not selecting the right SAN or NAS replacement candidates are high.
2. The Cost of SAN Proof of Concepts
After making a short list of potential replacement storage systems, IT must evaluate and test each manufacturer’s claims. Creating a test environment that can simulate a real-world workload has always been challenging; now, supply chain issues and staff shortages make testing almost impossible. Most vendors can’t just send you software and let you install their storage solution on available hardware. Instead, they must ship you pre-configured hardware and be heavily involved in your evaluation’s proof of concept phase. It can take months just to get the storage system so you can test it. You also have to ask yourself, “if I can’t install it myself, how hard will it be to support and operate it after they leave?”
3. The System Cost
While all vendors claim an impressive return on investment (ROI), they will not give you the system for free. You need to pay for it and hope it lasts long enough that your organization will realize the ROI. There are two keys to being able to realize a solid ROI. First, the upfront cost must be low enough that the organization can afford the system. Second, the operational costs can’t be too burdensome, and third, the system has to stay in operation long enough for the ROI to be realized.
4. The Cost of SAN Migration
Once the new storage system is selected and IT completes its evaluation, it must migrate data to the new system. The larger the environment, the more challenging the migration process becomes. In most cases, IT must identify and purchase special software tools to help with the migration. The average time to migrate from an old storage system to a new one is more than 90 days. In most cases, it is more than six months. Both the old and the new storage systems must stay active during this time (which doubles power and cooling costs), increasing backup complexity and is a cause of many operational errors. By the time the migration is complete, IT is only three years away from having to start the process all over again.
5. The Cost of Learning a New System
Once data is migrated to the new storage system. IT administrators must learn the new system’s software. There will be new methods to create volumes, configure drive redundancy, take and retain snapshots, and implement replication. There are often some features missing on the new system, causing IT to create new workarounds.
The Problem with “Stretching” The Current System
To avoid the storage refresh ordeal, many organizations will try to stretch the serviceable life of their current storage system. If the system continues to meet performance or capacity demands, this stretch typically involves buying extra out-of-warranty maintenance from the manufacturer or a third party. These out-of-warranty contracts are costly and more challenging to support.
There is also a stretching cost of lost capabilities because the storage system can’t provide improved performance or increased capacity as soon as users or applications need it. Lack of performance or capacity has a ripple effect on the networking and compute tiers, which increases the cost of those infrastructures. At some point, stretching the storage system leads to a break in data access or response time, leading to scrambling through the storage refresh process.
Storage Silos and Three-Tier Architectures Amplify the Costs
One of the biggest challenges with storage replacement is the fragmentation within the data center. The data center is islands of separate workloads. Each of these islands typically has its own computing infrastructure, sometimes its own network infrastructure, and almost certainly its own storage system. While a storage system typically requires refresh or replacement every four to five years, the separate storage islands mean that most organizations have six or seven different storage systems. As a result, IT is almost continuously replacing storage systems and managing data migration processes.
How to Get off the Storage Refresh Merry-Go-Round
Getting off the merry-go-round requires consolidating infrastructure so that IT has only one entity to manage instead of six or seven. It means a storage infrastructure that’s flexible enough to meet today’s and tomorrow’s needs and support both legacy and future storage hardware. The new solution can’t compromise on features. It has to provide a robust set of data services that enable organizations to protect their data assets and assure their availability.
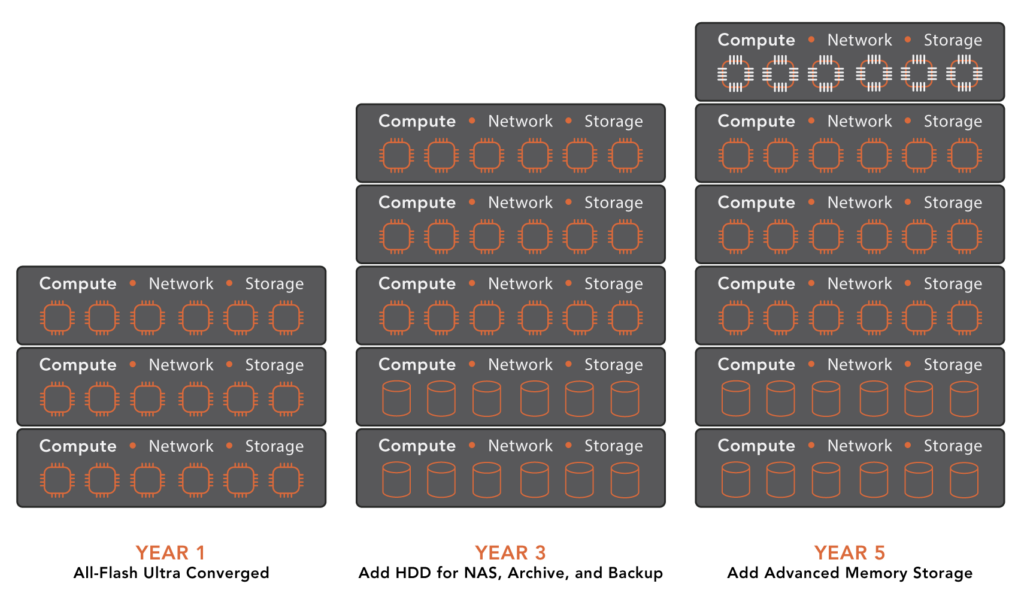
VergeIO’s VergeOS eliminates complicated data center processes like storage refreshes. We simplify IT and end storage refreshes by creating an ultraconverged infrastructure that collapses the data center tiers (compute, network, storage) into a unified, cohesive operating environment.
Next Steps
- Learn more about VergeIO’s storage capabilities (don’t compromise data)
- Register for a free test drive (don’t wait months for a POC)
- Watch our On-Demand Webinar “Three Infrastructure Questions IT Leaders Must Answer in 2023”


