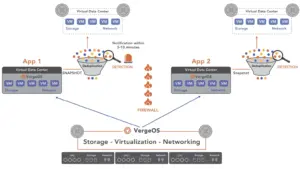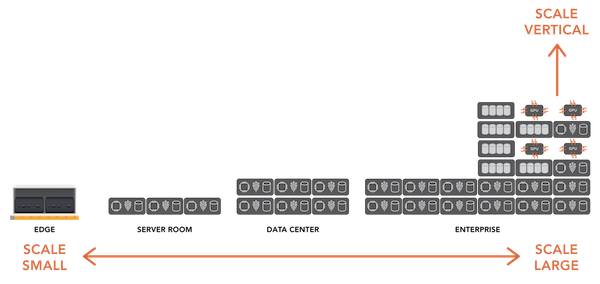
Scaling infrastructure in three dimensions lowers the cost of equipping, operating, and upgrading the data center. The problem is that traditional three-tier (compute, storage and networks) can’t scale beyond a single silo. IT professionals will also find that even hyperconverged infrastructure (HCI) falls short if they measure its scaling capabilities against all three dimensions. Ultraconverged infrastructure (UCI) is the first infrastructure to move beyond HCI to deliver a cohesive data center operating system that integrates the traditional three tiers instead of stacking them, enabling a three-dimensional scale.
Scaling Infrastructure Large
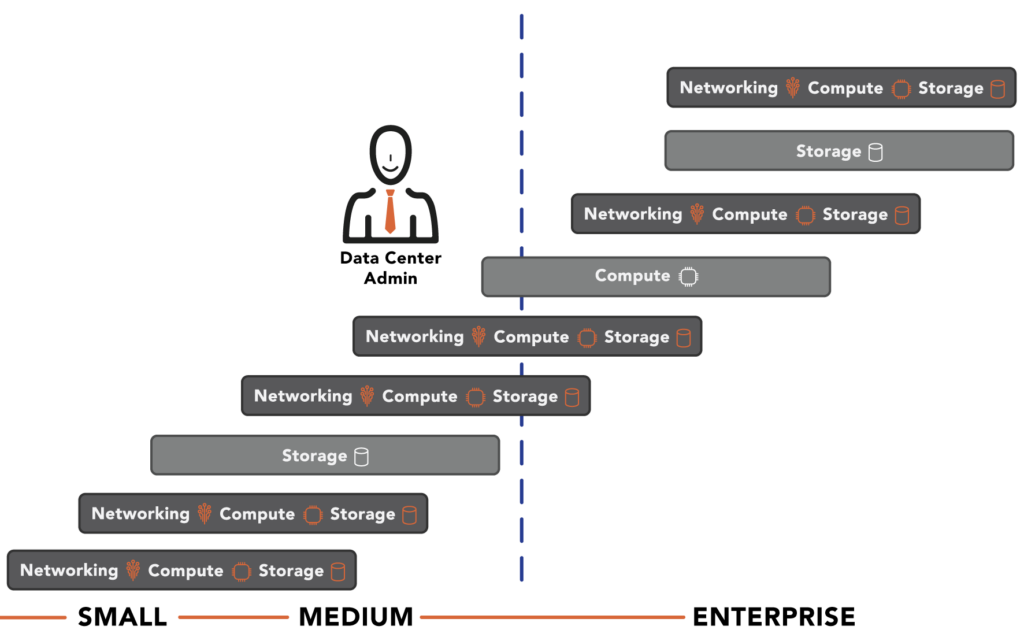
The industry needs an infrastructure that can scale large to meet the large enterprise’s or service provider’s demands. Enterprise data centers can no longer create a silo of infrastructure for each workload, and service providers can no longer afford to oversubscribe resources to enable the mixing of different customers’ workloads within their infrastructure.
Scale-Out is not Scaling Infrastructure in Three Dimensions
The challenge with scaling large is that neither traditional three-tier architectures nor HCI can meet this requirement. Of course, HCI vendors claim that scale-out addresses this requirement because you can increase capabilities by “just adding a node.” Is just adding a node enough?
Since HCI vendors borrow the hypervisor used in their solutions and make no optimizations, their claims that computing power increases with each additional node are disingenuous. It is true that with HCI, you can add more nodes to increase storage capacity and, to some extent, increase storage performance. Adding more nodes falls short of addressing the storage problem because HCI does not integrate virtualization, storage, and networking; it layers them on top of each other. As a result, storage performance is constantly burdened by the virtualization tax, and that tax rate increases as the number of nodes increase.
The impact is that HCI can’t scale large and maintain any sense of efficiency. Customers who have bought into the HCI philosophy almost always limit their per cluster node count to eight or fewer. They then create separate clusters for each use case, but the resources within those clusters are captive to that cluster.
UCI Scales Beyond Scale-Out
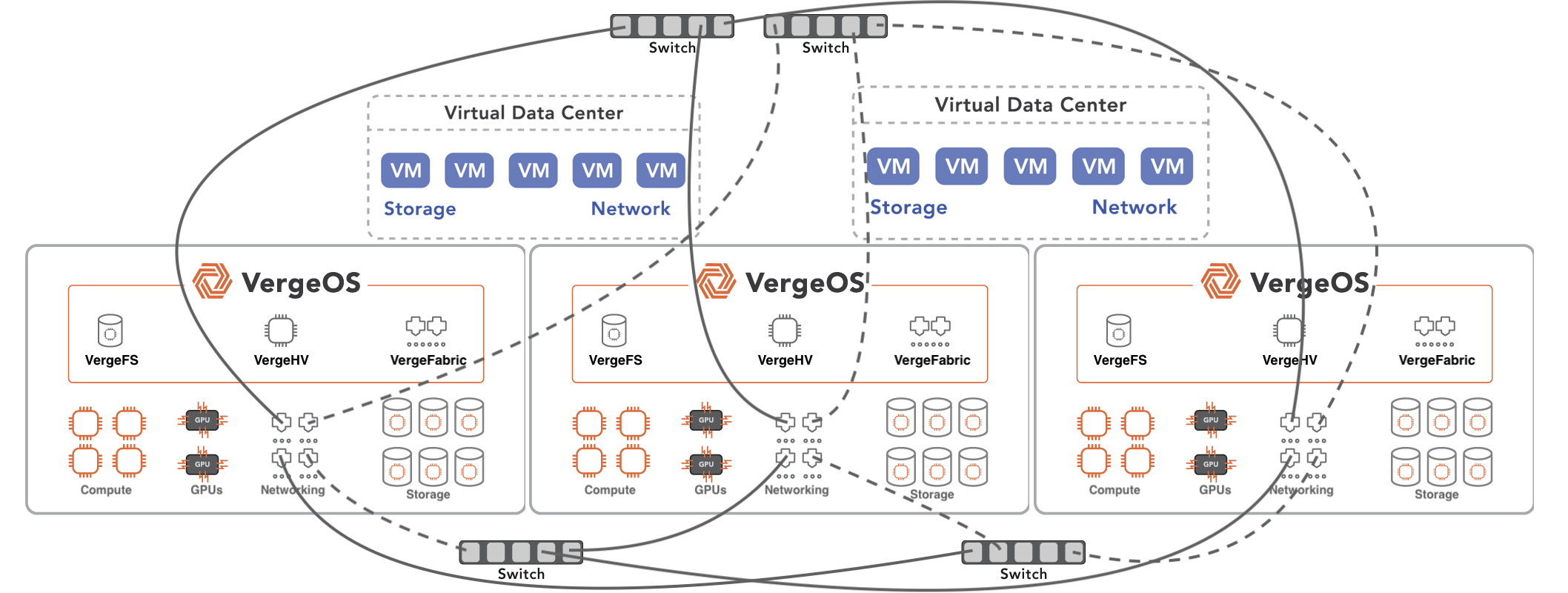
VergeIO goes beyond traditional HCI with its Ultraconverged Infrastructure (UCI). Unlike HCI, where storage and networking services are virtual machines of a borrowed hypervisor, VergeIO’s VergeOS tightly integrates the hypervisor, storage, and networking into a cohesive data center operating environment. One of the benefits of this integration is the ability to deliver unprecedented scale.
VergeOS delivers:
- A near elimination of the virtualization tax, which doesn’t increase as node count increases
- Storage and networking services run as equal citizens to the hypervisor, not as virtual machines
- Clusters are used to group nodes of specific capabilities, but those resources are globally pooled and are available to all or specific virtual machines.
The result is complete workload consolidation into a single point of operations and management. See our UCI vs. HCI comparisons page for more details or register to watch our upcoming webinar “Beyond HCI – UCI The Next Step in Data Center Evolution.”
Scaling Infrastructures Small
There is another infrastructure dimension that organizations need help addressing, scaling small. The need for a small scale can be as simple as scaling to meet the needs of a server room for a medium-sized business. However, enterprises increasingly require small scale as they deploy Edge strategies. These strategies need Edge Computing power.
HCI Can’t Scale Small
Traditional three-tier solutions are vastly inappropriate for both use cases, and most HCI solutions require starting with three nodes, making them too large for the use case. The few that can start with two nodes can’t scale large, meaning IT will have to acquire a brand-new architecture if the business grows. The infrastructure that scales small and scales large must be one and the same.
UCI Scales to the Edge
The efficient VergeIO UCI design enables VergeOS to also scale small in addition to scaling large. A VergeOS solution can run on two mini-servers, like Intel’s Next Unit of Computing (NUC), and deliver data center power in shoe-boxed-sized space. It doesn’t even need a switch because VergeOS has true network functionality built in. For server rooms, two mid-range servers may be all you need to collapse that server room into a server shelf.
The efficiency of VergeOS can leverage small servers to support a dozen or more virtual machines and offer incredibly high performance. In particular, the Edge Computing use case needs a global management capability that enables data center IT to manage, operate and perform changes to Edge-based instances.![]()
Scaling small requires more than just running on one or two servers. These infrastructures must be reliable and easy to operate. Edge Computing locations are often hard to visit for servicing. There is also the potential for one organization to have hundreds or even thousands of edge locations. For the server room, mid-range data center use case, there is generally a small and bustling IT team with many balls to juggle. In both cases, the entire data center operation often runs on that infrastructure. If it is down, so is the business.
For example, one of our most recent customers is a Ski Resort responsible for three mountains of slopes. They use VergeOS to host all their mission-critical workloads. If their VergeOS solution is down, they can’t sell passes, you can’t ski, and you can’t even buy food while you wait for the applications to come back up. The highly available VergeOS UCI solution has never missed a beat so that you can ski to your heart’s content.
Scaling Infrastructures Vertically
Most data centers have many workloads, each with different requirements regarding computing power, storage performance, and storage capacity. In most cases, addressing these mixed workload requirements will require different types of servers (node) and storage configurations.
HCI Can’t Mix Nodes (well)
Vertical scaling is a problem facing most legacy HCI architectures. They can’t mix nodes of different types, at least not efficiently. In most cases, the nodes within the cluster must be nearly identical. While some vendors claim that you can add capacity nodes, it often comes with an asterisk. One vendor even suggests that you turn off deduplication when adding nodes for capacity. They are concerned that their inefficient deduplication process will impact the performance of the other high-performance nodes. Isn’t a high-capacity situation the reason you want deduplication?
UCI Supports Mixed Nodes, Without Compromise
VergeOS can group like nodes into separate clusters yet combines the capabilities of those nodes into a global resource pool. The resources within the global pool can then be designated to a particular workload or made universally available to all workloads.
VergeOS is a data center operating system, not HCI, with storage and networking running as virtual machines. If the organization’s needs are mainstream, then a single cluster with a standard node type will do the job. However, multiple clusters empower complete workload consolidation for data centers with many use cases. Within a single VergeOS instance, you can have multiple clusters with specific capabilities:
- A cluster of high-end Intel CPUs and NVMe Flash
- A cluster of mid-range AMD CPUs and SAS Flash
- A cluster of servers with GPU and Storage Class Memory
- A cluster of servers with high-capacity hard disk drives
- A cluster to limit licensing costs, like in the Oracle Cluster use case
You can have as many nodes within each cluster as you need. The resources within the cluster are then made available through the global resource pool. The resources within the global pool are allocated to virtual data centers (VDC). VDCs encapsulate an entire data center, all the virtual machines (VMs), networks, and storage settings, as well as user management and security. Resources within the global pool can be dedicated to a VDC or made universally available to all VDCs, enabling complete workload consolidation while assuring consistent workload performance.
Conclusion
Scaling infrastructure in three dimensions lowers the cost of equipping, operating, and upgrading the data center as the hallmark of UCI solutions like VergeOS. With it you can scale small, large, and vertically. A common platform that can scale in any dimension makes life easier for IT professionals.
There is even a fourth dimension, deep. Deep scaling is the ability to maximize the investment and capabilities of each node within each cluster within the UCI solution. We’ll explore deep scaling in a future blog.
The result of Scaling infrastructure in three dimensions (or four) is:
- Dramatic reduction in upfront and long-term costs
- Significantly easier to operate
- Better protection from ransomware and disasters
- IT Professionals that get to go home before the sun goes down and sleep well at night
Learn More
- Subscribe to our Digital Learning Guide on the VergeIO Architecture.
- Attend our Live webinar Beyond HCI and learn about the next step in Data Center Infrastructure.
- Watch our on-demand webinar “How to Eliminate the Data Center Scale Problem.”
- Watch our on-demand LightBoard Deep Dive on the VergeIO architecture.
- Test our software for yourself with our free Test Drive.
- Meet — View our Technical Calendar to meet one-on-one with one of our technical experts to learn more.