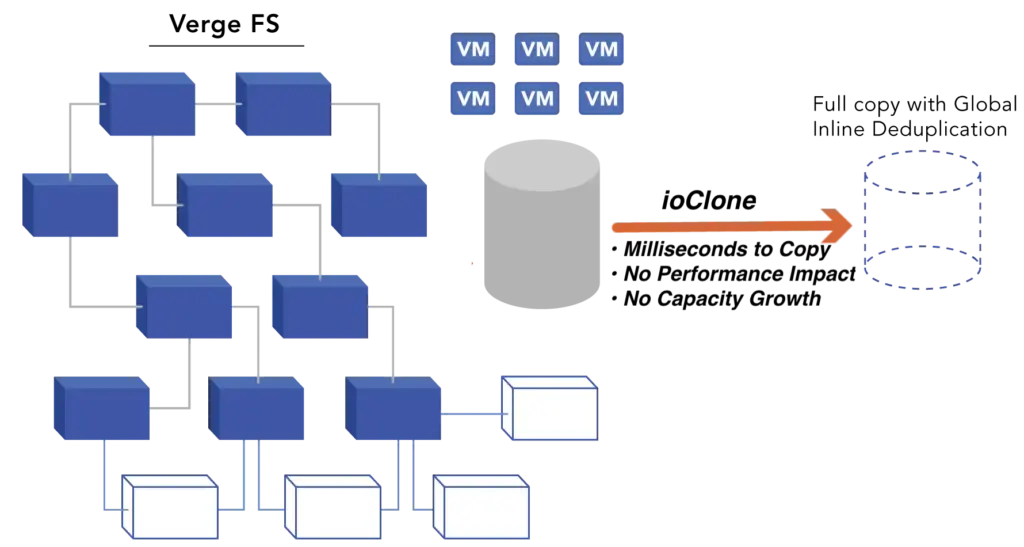
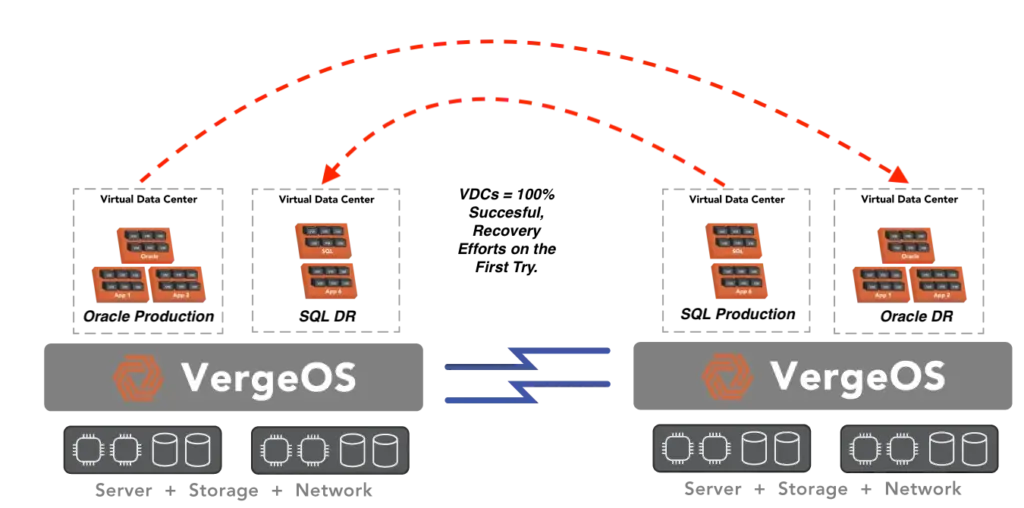
In addition to planning for natural and man-made disasters, it’s crucial to have a secondary hypervisor ready, in preparation for potential changes in your hypervisor’s licensing model or other technical challenges. Having a secondary hypervisor ready to go, similar to having a disaster recovery (DR) site, and with the right software, it can fulfill many of the obligations of a traditional DR solution.
What to Look for in a Secondary Hypervisor
A Secondary Hypervisor for Hardware Protection
The reasons to have a secondary hypervisor ready are essential for more than just hedging against unexpected increases in licensing costs. Sometimes, hypervisor vendors remove hardware support, forcing you to upgrade servers long before they have outlived their usefulness. Look for a secondary hypervisor that can not only support the existing hardware, but one that may even be more efficient at utilizing it, breathing new life into old systems.
A Secondary Hypervisor for Increased Resiliency
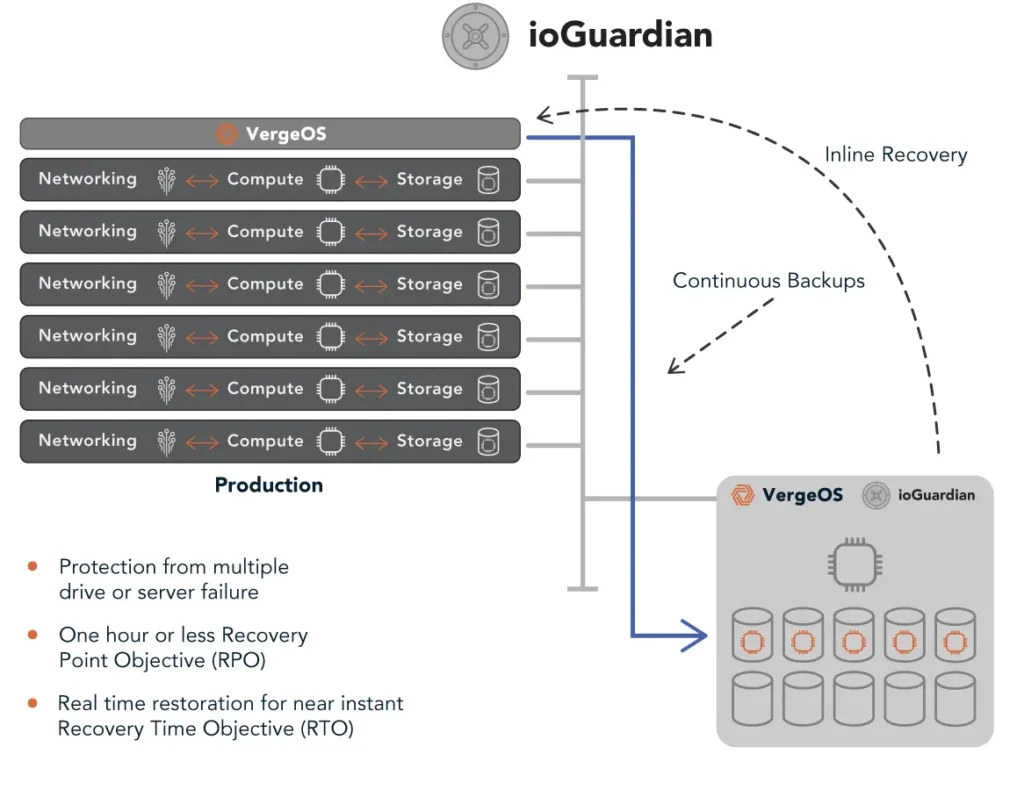
Another reason to have a secondary hypervisor ready is to improve resiliency. Hardware seems to have plateaued in terms of reliability, but users’ patience with downtime has not. They want continuous access to applications and data regardless of how many hardware failures the environment is experiencing. Look for a secondary hypervisor that can provide you with resiliency beyond surviving one or two drive failures or a server failure. It should also provide better data resiliency in addition to hardware resiliency. Look for a secondary hypervisor that can execute snapshots more frequently and retain those snapshots indefinitely without impacting performance.
A Secondary Hypervisor for Improved DR Operations
DR planning and operations are two of the most challenging aspects of a DR strategy. Ensuring that everything works the first time, according to plan, requires practice. Success can also be improved by eliminating as many variables as possible. The challenge facing most IT professionals is that they have to sew together a wide variety of products to capture all the different components within their production data center. Then, they have to reassemble all these components at the DR site with the added stress of the disaster occurring around them.

It is essential to have a secondary hypervisor ready to compare DR operations side-by-side with the current hypervisor. Look for a secondary hypervisor that provides infrastructure-wide protection, which enables all the elements of infrastructure to be encapsulated into a single object. The encapsulation means there is only one component to worry about instead of half a dozen or more. It also eliminates the need to ensure consistent capture between the different components.
A Secondary Hypervisor for Better Support
Protecting against the decline in the quality of technical support is another reason to have a secondary hypervisor ready. If IT can’t get assistance in resolving issues in a timely matter, if outsourced support isn’t able to help with deep technical issues, or if you are unable to speak with a live person to help resolve an issue, then knowing you can get better, faster resolution with an alternative solution is invaluable.
Look for a secondary hypervisor that can provide live person-to-person technical support that understands that infrastructure support involves helping you get their software to work with various hardware. Also, ensure that the support team has direct access to developers if a particular thorny issue arises.
A Secondary Hypervisor Evaluation Process
Evaluate Secondary Hypervisors
Research and evaluate alternative hypervisors that can meet your organization’s needs. Consider factors such as compatibility, performance, and cost. Make sure it meets the above requirements so that you don’t give up features or capabilities. It should run on your existing hardware, not force you to buy new hardware for something that initially is part of a DR strategy. If, for example, the original hypervisor vendor has removed support for legacy servers, but the new hypervisor supports them, they become an ideal foundation for launching a secondary hypervisor.
Implement a Continuous Migration Strategy
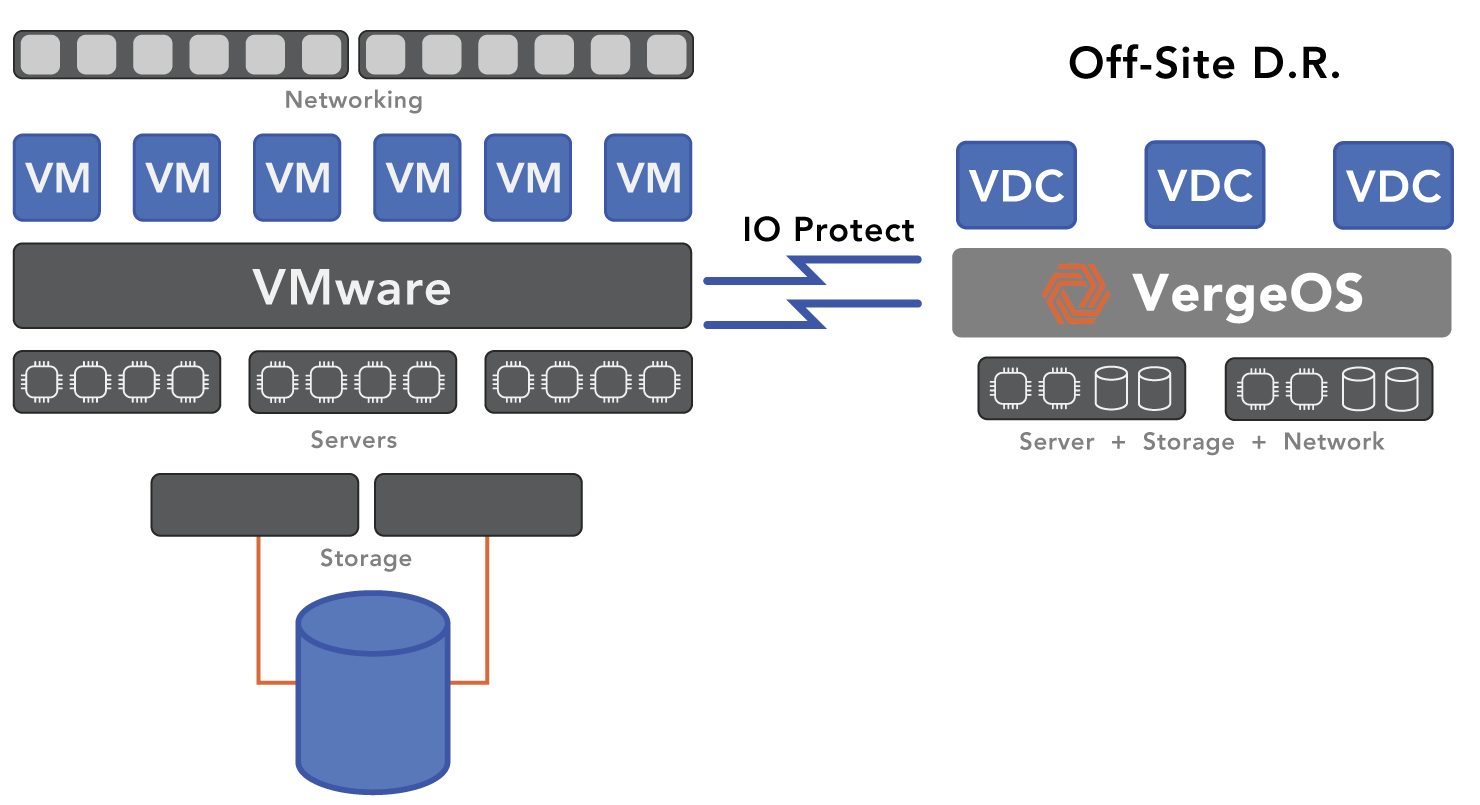
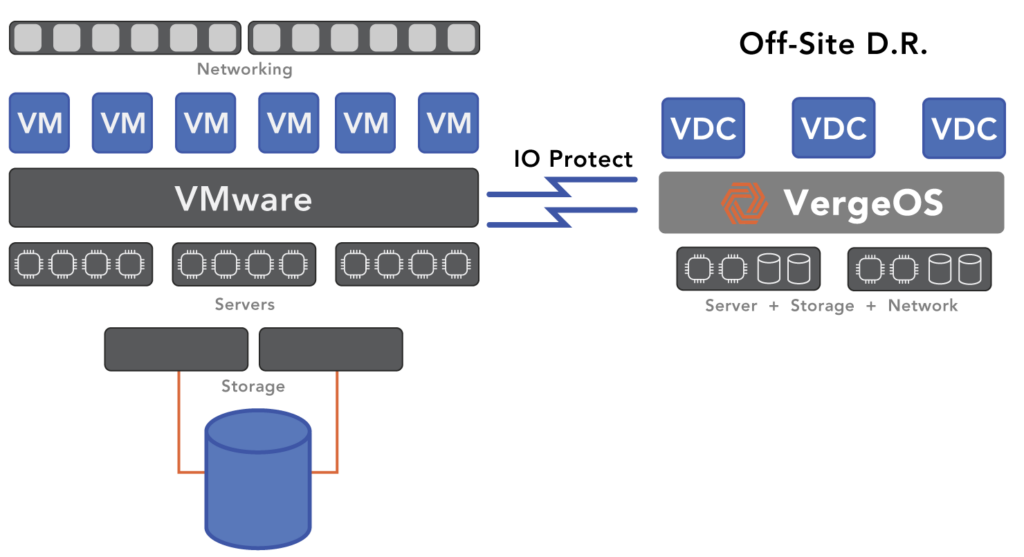
Develop and implement a migration strategy to transition from primary hypervisor to secondary hypervisor. Utilize tools like VergeIO’s ioProtect, which allows you to back up all your virtual machines to a VergeOS instance and store them in VMware’s format. ioProtect also employs change block tracking (CBT) to keep VMs current so you can continuously update the VergeOS instance, ensuring it is always ready to go. A continuous migration strategy means the secondary hypervisor should be considered when comparing DR strategies.
Test the Secondary Hypervisor
Regularly test your secondary hypervisor environment to ensure it can seamlessly take over in case of a sudden licensing cost increase or any of the above issues arise. If the secondary hypervisor has a continuous migration capability, it can replace or augment your current DR strategy. If the solution includes global inline deduplication, then you can place the secondary hypervisor at the DR site and use it as the core of your DR strategy. Conduct simulated recovery scenarios to identify and address potential issues and gain experience with the secondary hypervisor.
Move the Secondary Hypervisor to Production
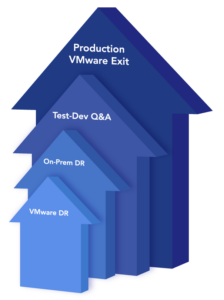
The potential cost savings of the secondary hypervisor and improved efficiencies may motivate you to move some workloads directly to it, even before there is a disaster or licensing surprise. Sometimes, these initial use cases are for testing and developing applications running on the original hypervisor, or you can use the secondary hypervisor for new workloads.
How VergeIO Can Help
VergeIO offers a solution, VergeOS, that is more than a secondary hypervisor. It is a complete data center operating system, which includes a hypervisor, storage, and networking services. It collapses the legacy IT stack into a single software that simplifies IT and lowers the total cost of ownership.
Part of VergeOS is ioProtect, designed explicitly for VMware customers looking to improve their disaster recovery capabilities while also providing a potential offramp if challenges with ESXi arise or if there is an unexpected increase in licensing costs.
In the event of a disaster—whether natural, man-made, or business-related—ioProtect enables you to convert these VMs to VergeOS VMs with a single click, resuming operations within seconds. This solution allows you to test VergeOS against VMware over an extended period while adding value through ongoing use.
Conclusion
Having a secondary hypervisor ready is not just a safety net; it’s a strategic advantage. It ensures that you are not locked into a single hypervisor, allowing you to adapt and pivot as needed. This level of preparedness can significantly mitigate risks associated with vendor lock-in, unforeseen price hikes, or changes in service levels.
Investing in a secondary hypervisor might seem like an additional cost upfront. Still, if that secondary hypervisor can add value by lowering the cost of disaster recovery and improving the success rate, the solution may more than pay for itself. This approach enables your organization to enjoy the long-term benefits without an initial cost outlay. It empowers your IT infrastructure with redundancy, ensures business continuity, and provides the freedom to choose the best solutions for your specific needs at any given time.
The path to a VMware alternative may appear challenging, but being proactive and diversifying your hypervisor strategy will position your organization for sustained success and resilience in the ever-evolving data center landscape.