IT professionals trying to implement disaster recovery (DR) plans that enable their organizations to survive, struggle to overcome DR cost and complexity. The problem is that most solutions don’t take a holistic approach. Instead, current solutions require IT to use a DR component for each tier of the data center infrastructure: storage, applications, and networking, which not only increases cost and complexity but lowers the likelihood that a recovery will be successful.
VergeOS’ holistic approach greatly simplifies DR to the extent that it “just works,” while lowering costs. In addition to unprecedented DR capabilities, VergeOS provides complete high availability and data protection. Learn in our upcoming live webinar and demonstration, “The Missing Fourth Tier of Convergence: High Availability, Data Protection, and Disaster Recovery.”
The DR Problem with Array-Based Replication

Storage systems are a primary focus of any DR solution. Replicating data from a primary site to a secondary site is table stakes for any enterprise solution, and most storage vendors provide such a capability with their products. However, including replication still requires IT to overcome DR cost and complexity issues and makes it very difficult for them to overcome DR cost and complexity.
Dedicated storage arrays, that include replication, often require the same or a very similar storage array in the DR site. As we discussed in our article “The High Cost of Dedicated Storage,” storage vendors already markup the cost of their solutions 5X to 10X the regular cost of hardware, and now, to protect their organizations from a disaster, IT must pay that markup twice.
Creating a separate disaster recovery process for the storage system creates complexity when executing recovery. Storage replication only replicates the data on that dedicated device. If the customer, as many do, has multiple storage systems from different vendors, they need a separate replication process for each system.
In addition, most customers do not place all their data on the storage area network (SAN) or the network-attached storage (NAS). Many customers at least boot their virtualized environments from local storage and many store critical aspects of the application on storage within those local servers. Also, array-based replication will not capture any network configurations and settings. Those need to be separately captured and applied at the disaster recovery site.
As a result, array-based replication, which is by far the most common means of complying with a disaster recovery requirement, is incomplete, complex, and expensive. It forces IT to manage a separate disaster recovery process for each storage system and maintain separate processes for the application tier and the network infrastructure.
The DR Problem with Hypervisor-Based Replication
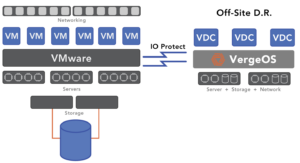
To overcome DR cost and complexity of array-based replication, some solutions will replicate at the hypervisor, from hypervisor vendors like VMware and standalone third parties like Zerto, now owned by HPE. These solutions capture and replicate data from a virtual machine perspective. The likelihood of success increases if the organization stores all its data within the virtual machines. However, most organizations do not and have separate data storage silos. Hypervisor-based replication also enables replication to disparate storage hardware.
There are challenges to hypervisor-based replication. First and foremost is the cost. These solutions are dramatically more expensive than even array-based replication. The second challenge is that hypervisor-based replication often will not pick up unique storage settings at each location, so the storage infrastructure has to be correctly maintained. Finally, hypervisor-based replication cannot capture all the unique network configurations unless the network is software-defined.
As a result, when performing a disaster recovery test or recovering from a declared disaster, hypervisor-based replication takes significant amounts of time to apply last-minute updates to the DR site, which delays the speed at which the organization can recover from the disaster. Each last-minute step is also a potential point for human error, which can delay the recovery process even further.
Solve the DR Problem with VergeOS

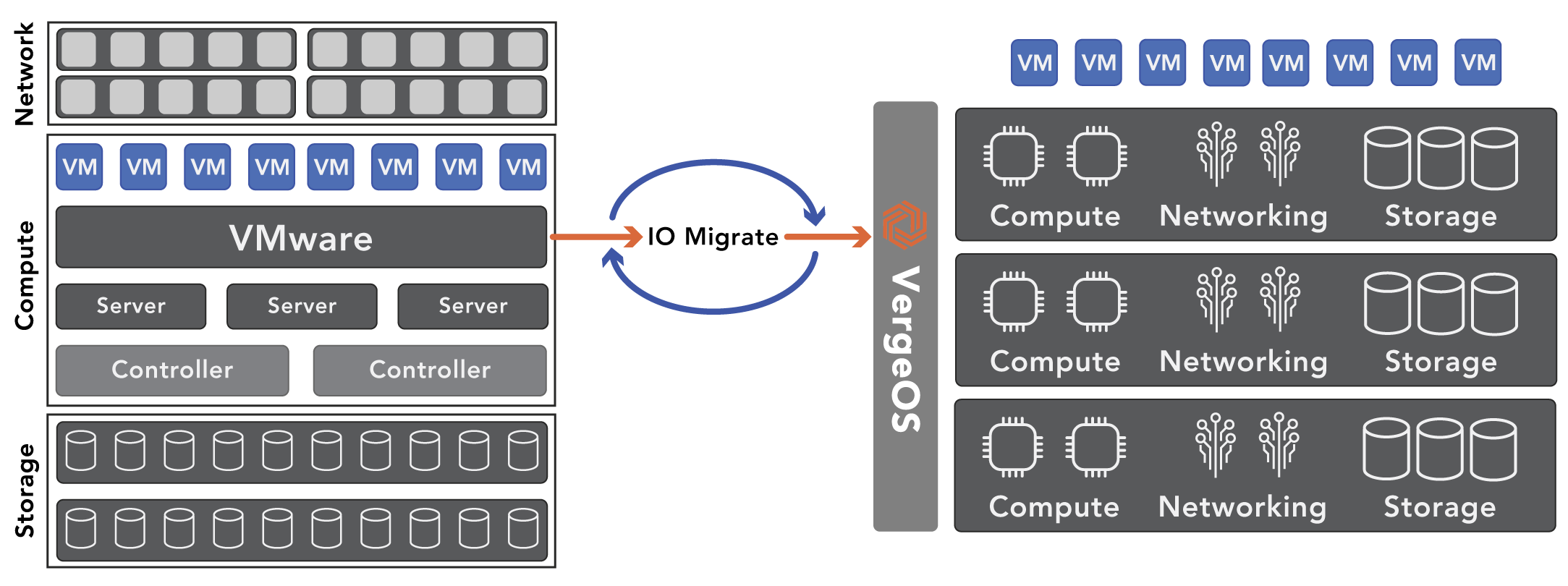
VergeOS’ unique multi-tenant virtual data centers (VDC) provide a holistic disaster recovery solution where every aspect of the data center is captured and replicated in a single movement, enabling IT to overcome DR cost and complexity.
A VDC is an encapsulation of the entire data center, similar to how a virtual machine is an encapsulation of a physical server. A VDC contains all of the components of the data center: all the VMs, all the network settings, and all the storage settings. This encapsulation means IT can perform VM-like movement functions to the entire data center.
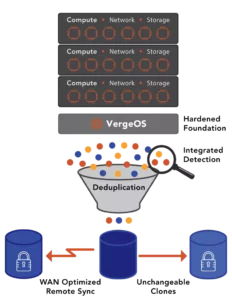
While there are many use cases for Virtual Data Centers, the most common is to implement them as part of a DR strategy. To establish a DR site, IT only needs to copy the VDC to their DR site and establish an asynchronous replication between the two. The remote VDC benefits from VergeOS always-on global inline deduplication. Multiple sites can replicate to a single disaster recovery site, and only data unique to the entire global footprint must be transmitted.
In the event of a disaster, the DR copy of the VDC is perfect, containing all the components and configuration settings of the original data center, even the network settings. The DR site can contain different server, storage, and network hardware than the primary, and everything will still function as expected because the VDC has abstracted everything from the physical hardware.
Every infrastructure component is securely stored at the DR site so that recovery occurs seamlessly without last-minute configuration updates. When IT needs to perform a DR test or recover from a real-life disaster, it “just works.”
IT just needs to make the VDC instance active and direct users to start logging into it. Most VergeOS customers report a dramatic reduction in the time and effort to perform their DR tests, and 100% of those impacted by an actual disaster have been able to execute a rapid, successful recovery. In short VergeIO customers have overcome DR cost and complexity.
Lowering Disaster Recovery Costs with VergeOS
Not only does VergeOS simplify disaster recovery, but it also lowers its costs. VergeOS is a single piece of software that integrates virtualization, storage, networking, as well as high availability, and disaster recovery into a cohesive operating environment. As a result, VergeOS includes all of the above functionality in the core software product at no additional charge. The cost savings are dramatic when comparing the cost of a multi-component disaster recovery solution to VergeOS’ holistic DR approach. Many customers report reducing their DR total cost of ownership (TCO) by 60% or more. When customers add the savings of eliminating double-marked-up storage costs and proprietary networking hardware, they can reduce their TCO by 80%.
Conclusion
IT professionals have long struggled to overcome DR cost and complexity. VergeOS offers a simplified and cost-effective DR solution integrated into the platform’s core instead of a never-ending series of expensive add-ons.
VergeOS integrates virtualization, storage, networking, high availability, and disaster recovery into a single software solution, eliminating the need for multiple components and significantly reducing the total cost of ownership (TCO). VergeOS’s multi-tenant virtual data centers (VDC) streamline the process, capturing all data center components in one movement, ensuring seamless recovery.
In today’s unpredictable business landscape, VergeOS revolutionizes disaster recovery, making it efficient and affordable for organizations.