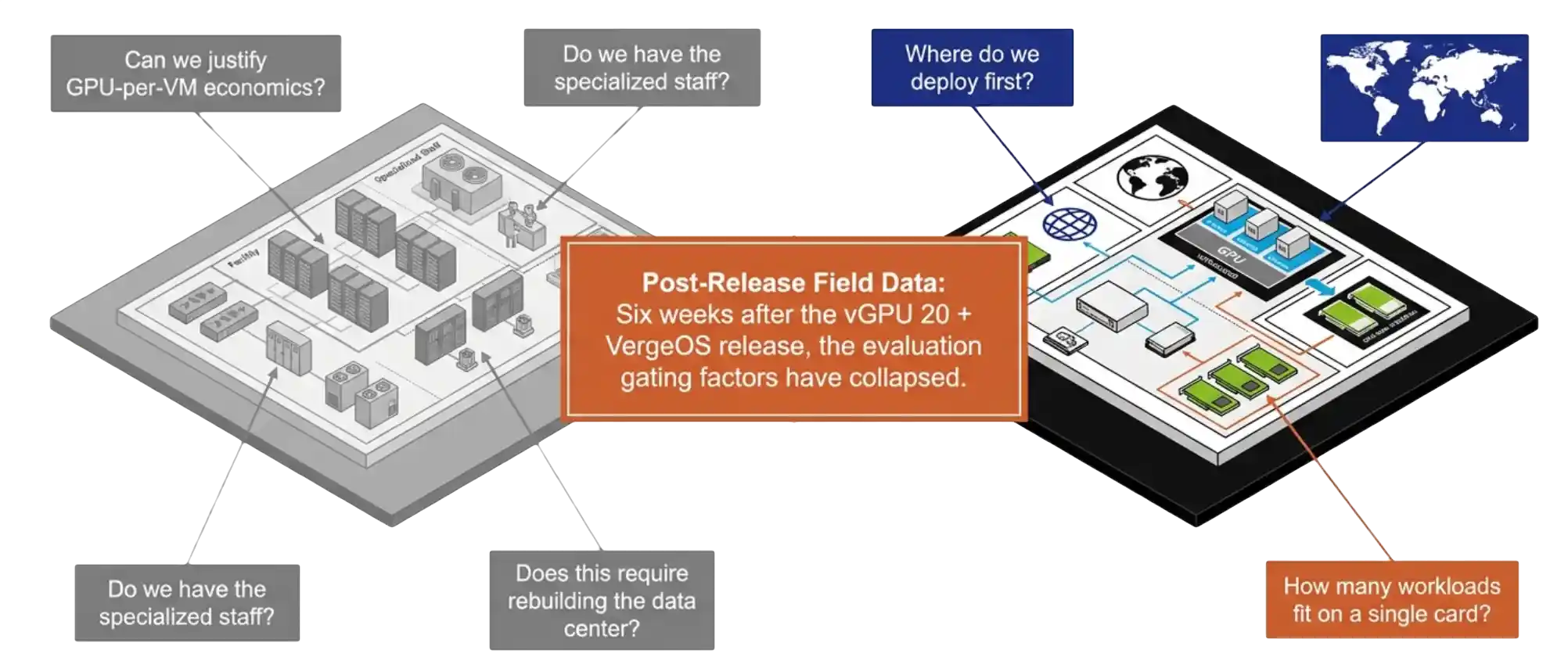
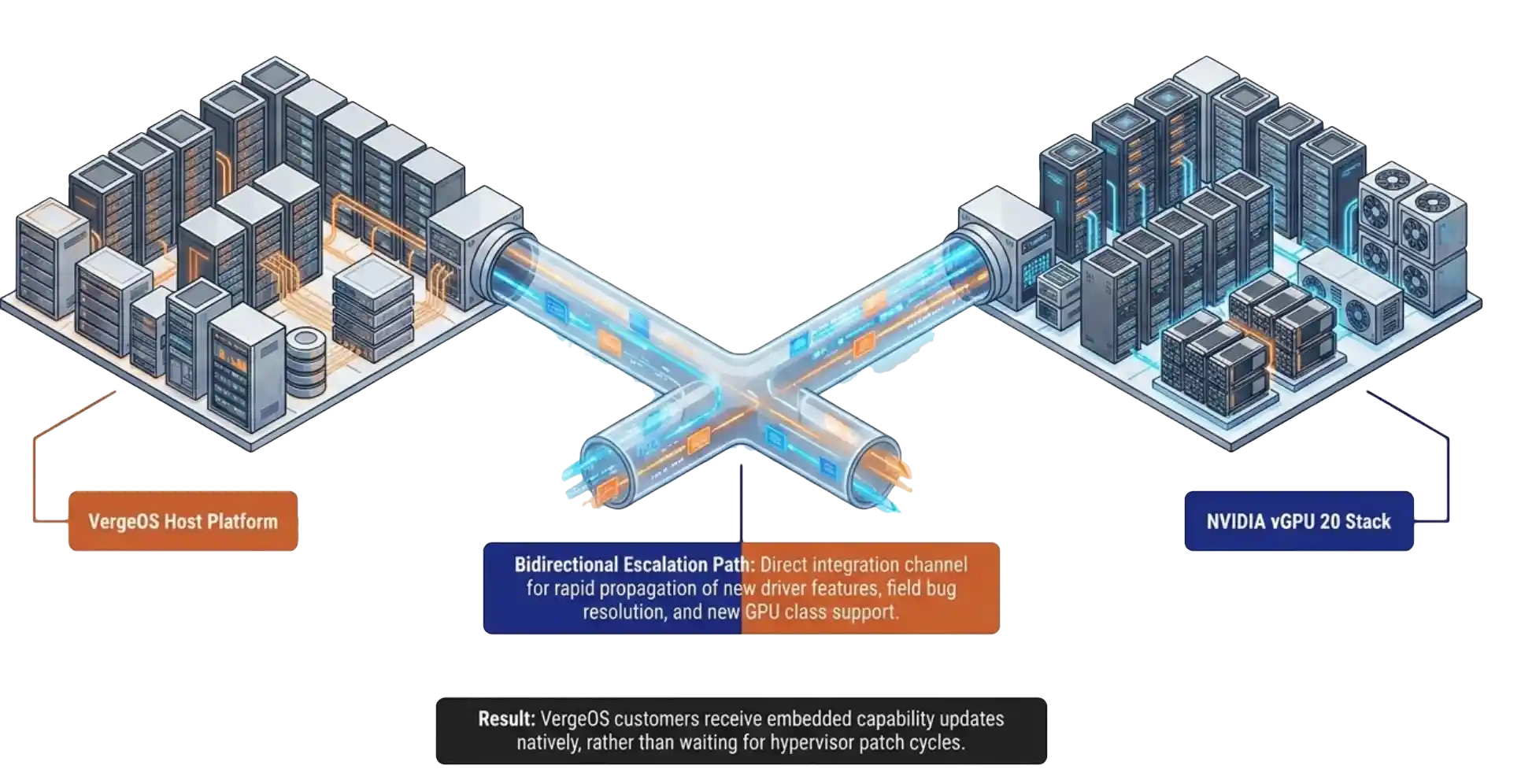
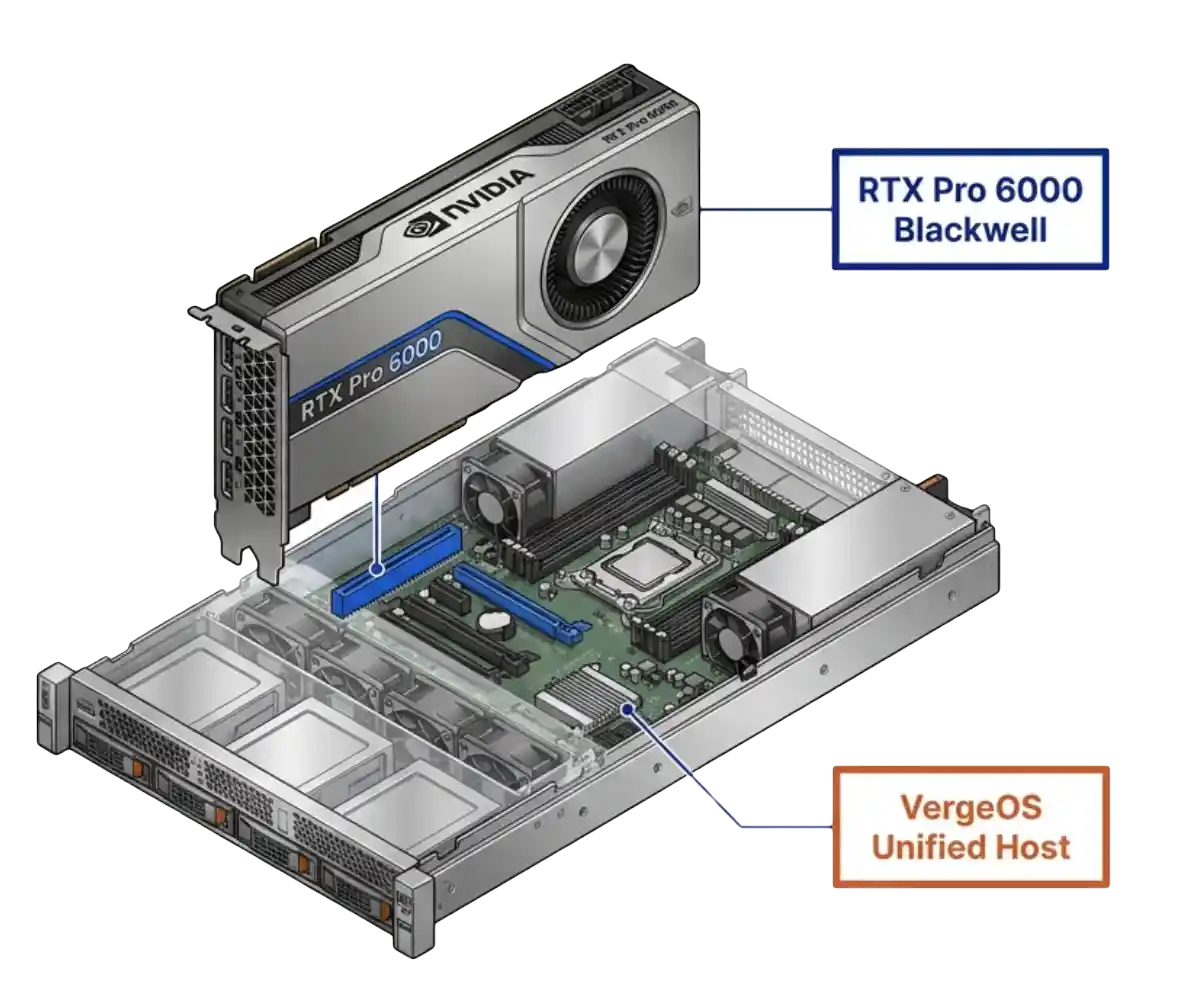
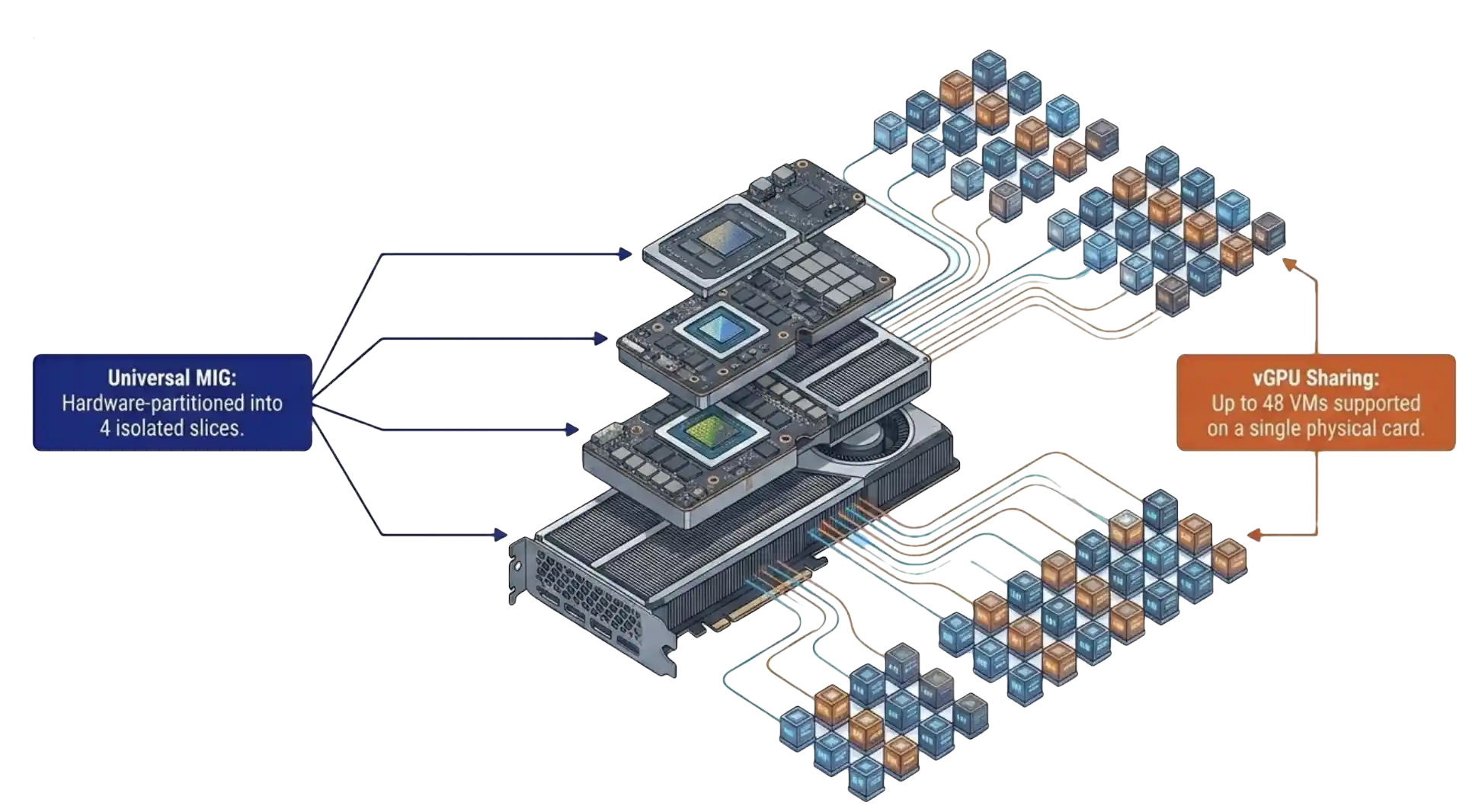
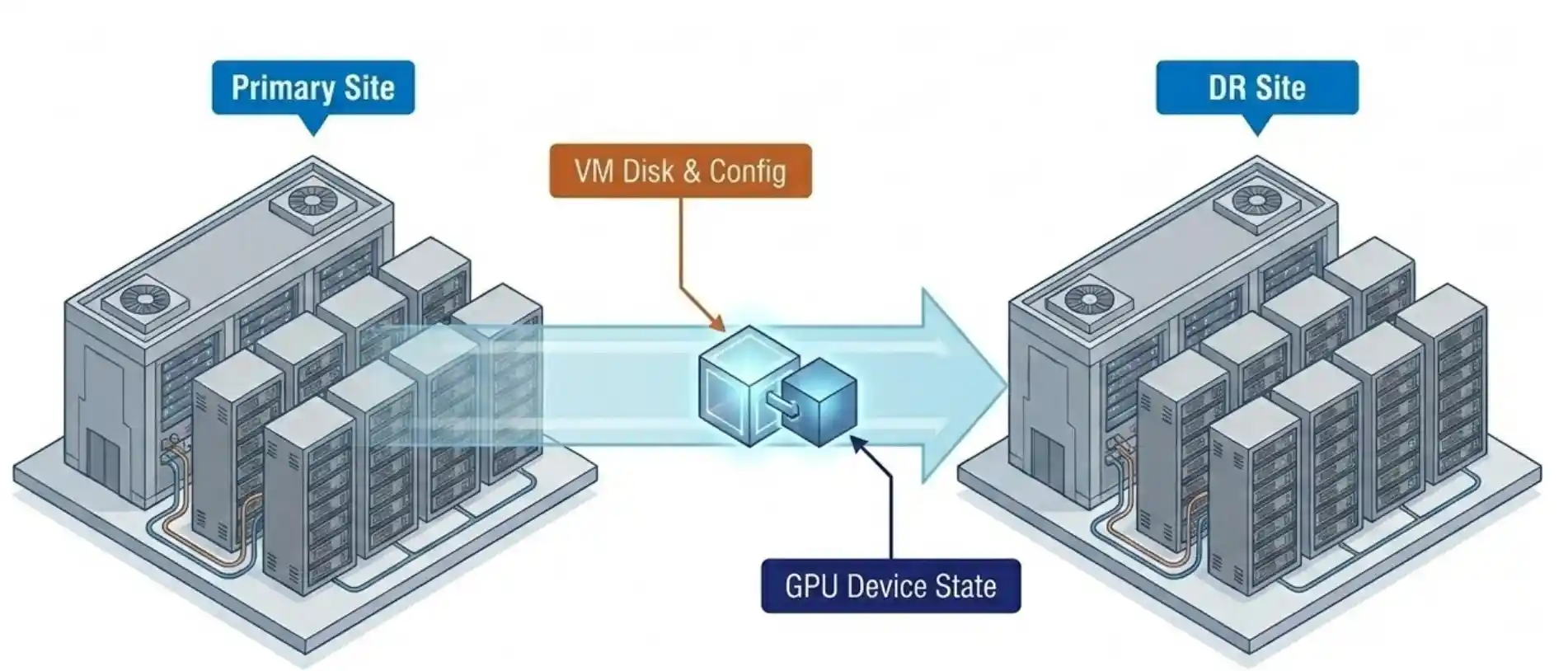
See how VergeOS turns NVIDIA vGPU 20 deployment into a point-and-click operation, with pass-through, vGPU, and MIG partitions configured through the same interface IT teams already use for compute, storage, and networking.
by George Crump
Filed Under: Videos
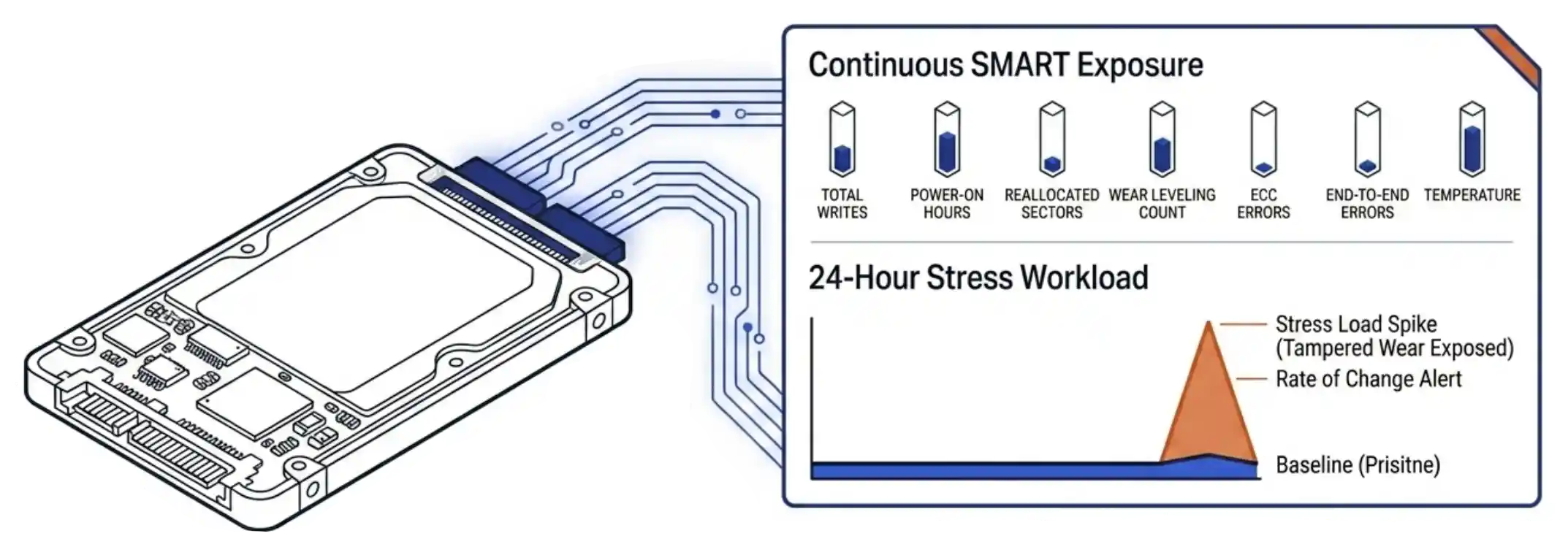 VergeOS exposes the seven primary SMART attributes on every drive in the cluster in real time: total writes, power-on hours, reallocated sectors, wear leveling count, ECC errors, end-to-end errors, and temperature. The exposure is continuous, not on-demand. A drive that arrives reporting twenty percent used wear gets watched against its reported state from the moment it joins the pool. Tampered drives reveal themselves quickly when actual write activity moves the counters faster than the reported state would predict. VergeOS alerting can be setup to warn you of signs of this behavior without you having to check in on every drive every day.
VergeOS exposes the seven primary SMART attributes on every drive in the cluster in real time: total writes, power-on hours, reallocated sectors, wear leveling count, ECC errors, end-to-end errors, and temperature. The exposure is continuous, not on-demand. A drive that arrives reporting twenty percent used wear gets watched against its reported state from the moment it joins the pool. Tampered drives reveal themselves quickly when actual write activity moves the counters faster than the reported state would predict. VergeOS alerting can be setup to warn you of signs of this behavior without you having to check in on every drive every day.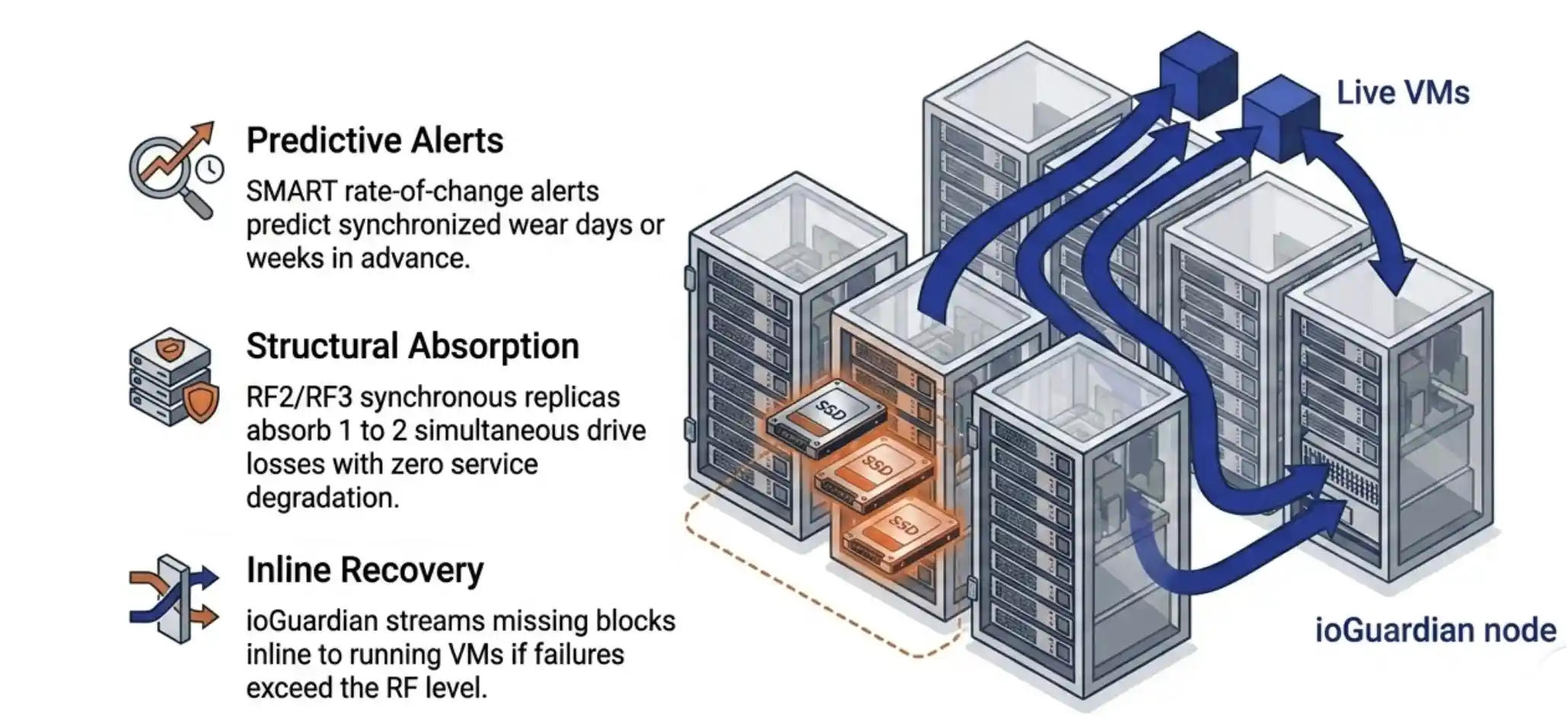 The platform handles correlated batch failure on three levels. The rate-of-change SMART subscription fires when multiple drives in a batch show wear advancing in synchronized patterns, giving the IT operator days or weeks of warning. RF2 (two synchronous replicas) absorbs the loss of any one drive without service degradation. RF3 (three synchronous replicas) absorbs two. The choice between RF2 and RF3 is a capacity question, and most customers run RF2 once they understand the layer above it.
The platform handles correlated batch failure on three levels. The rate-of-change SMART subscription fires when multiple drives in a batch show wear advancing in synchronized patterns, giving the IT operator days or weeks of warning. RF2 (two synchronous replicas) absorbs the loss of any one drive without service degradation. RF3 (three synchronous replicas) absorbs two. The choice between RF2 and RF3 is a capacity question, and most customers run RF2 once they understand the layer above it.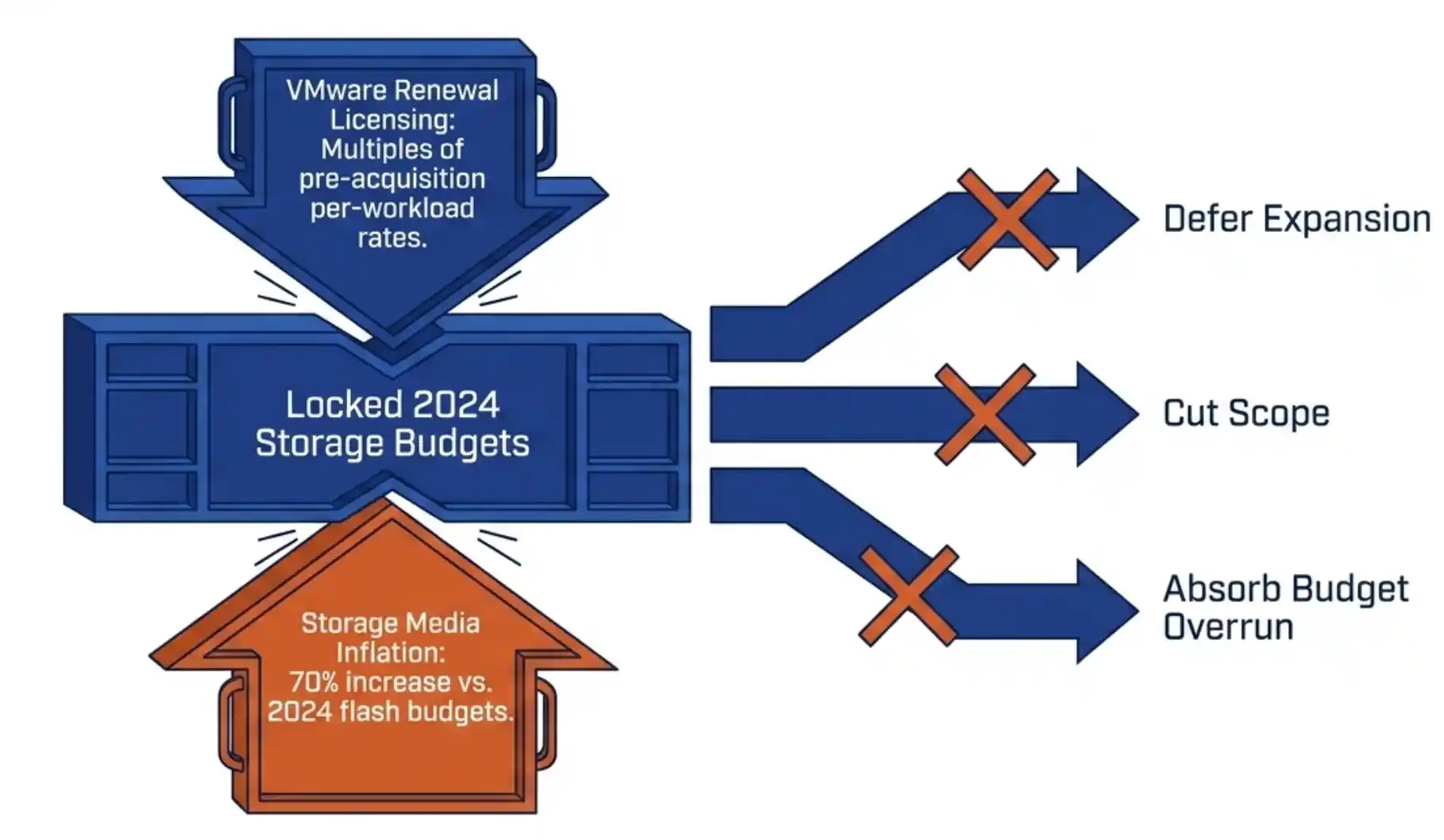 Your 2026 SAN refresh is in trouble. Flash inflation has pushed enterprise SSD prices up 70 percent. Refresh budgets locked in 2024 are now under-funded against current list pricing. The standard responses are to defer expansion, cut scope, or absorb the cost as a budget overrun. None of those options preserve the operational plan you set last year.
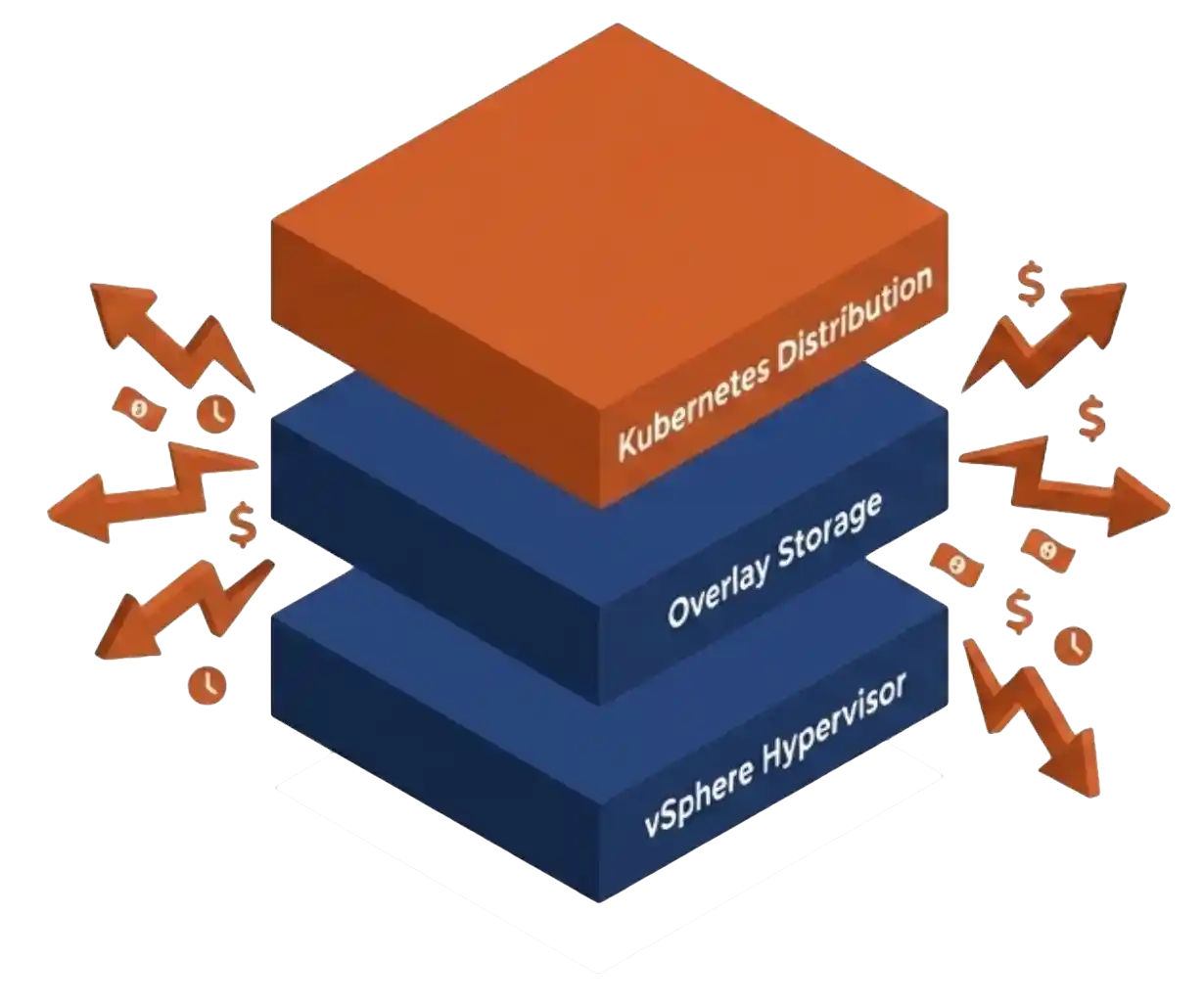
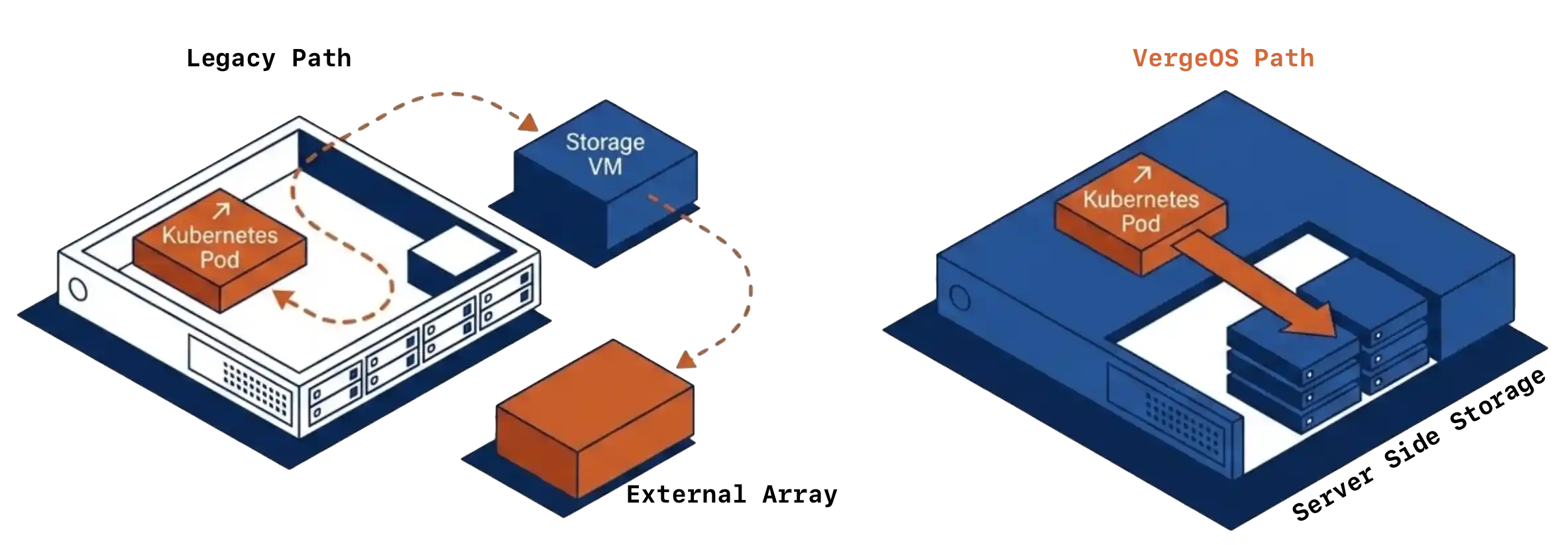
Your 2026 SAN refresh is in trouble. Flash inflation has pushed enterprise SSD prices up 70 percent. Refresh budgets locked in 2024 are now under-funded against current list pricing. The standard responses are to defer expansion, cut scope, or absorb the cost as a budget overrun. None of those options preserve the operational plan you set last year. Most infrastructure teams treat their SAN refresh and their hypervisor strategy as separate problems. The SAN refresh is a procurement decision, owned by storage architects. The VMware exit is a platform decision, owned by virtualization leads and the CIO. The two budgets land in different fiscal lines, the two evaluation cycles run on different clocks, and the two vendor conversations rarely overlap.
Most infrastructure teams treat their SAN refresh and their hypervisor strategy as separate problems. The SAN refresh is a procurement decision, owned by storage architects. The VMware exit is a platform decision, owned by virtualization leads and the CIO. The two budgets land in different fiscal lines, the two evaluation cycles run on different clocks, and the two vendor conversations rarely overlap.