Ann Arbor, MI — September 16, 2025 — VergeIO, the leading VMware alternative, today announced a partnership with Cirrus Data Solutions (CDS), a leader in data mobility technology and services, to help enterprises eliminate infrastructure sprawl—the costly mix of multiple hypervisors, duplicate tools, and isolated stacks, that has crept into data centers. The collaboration combines Cirrus Data’s patented software-only data mobility technology with VergeOS, the industry’s only single-codebase infrastructure operating system for virtualization, storage, networking, and AI.
Sprawl has accelerated as organizations juggle VMware, Hyper-V, Nutanix, OpenStack, and public cloud IaaS. The result is higher licensing spend, fragmented operations, and slow recovery. VergeIO and Cirrus Data address both sides of the problem: a universal migration path that keeps production online and a unifying destination that consolidates platforms into one operating model.
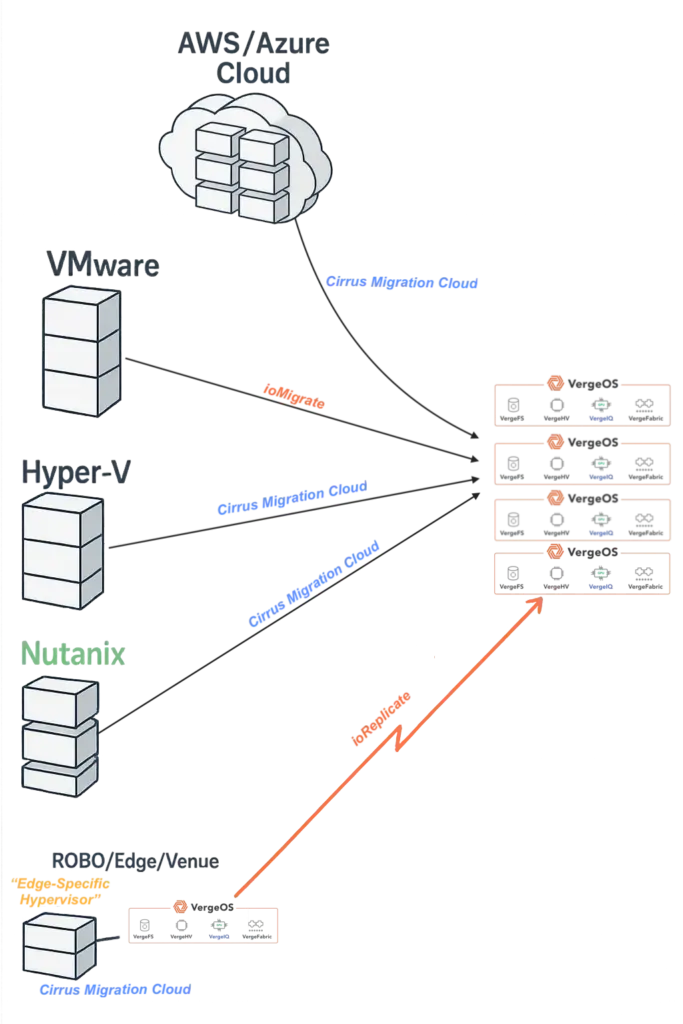
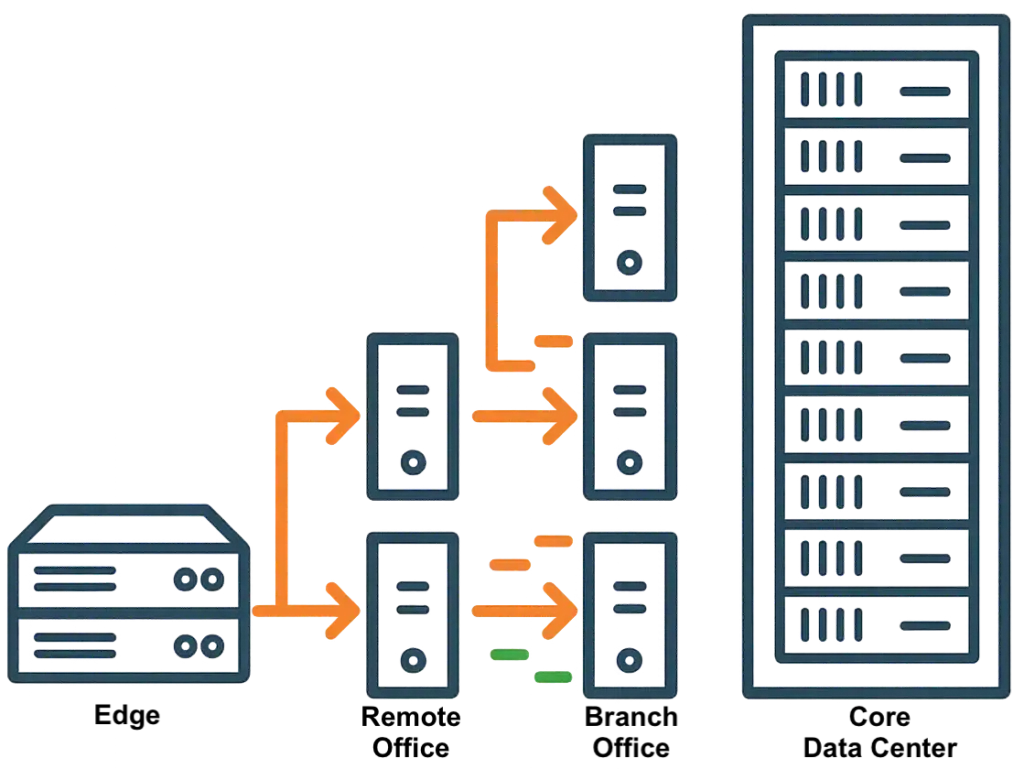
- Cirrus Data delivers zero downtime migrations for clustered applications. Its software-only solution can migrate from nearly any hypervisor, including VMware, Hyper-V, Nutanix AHV, Oracle Linux Virtualization Manager (OLVM), Proxmox, OpenStack, and others, in addition to the public cloud IaaS. Organizations can now automate the move of heterogeneous estates on schedule and without disruption.
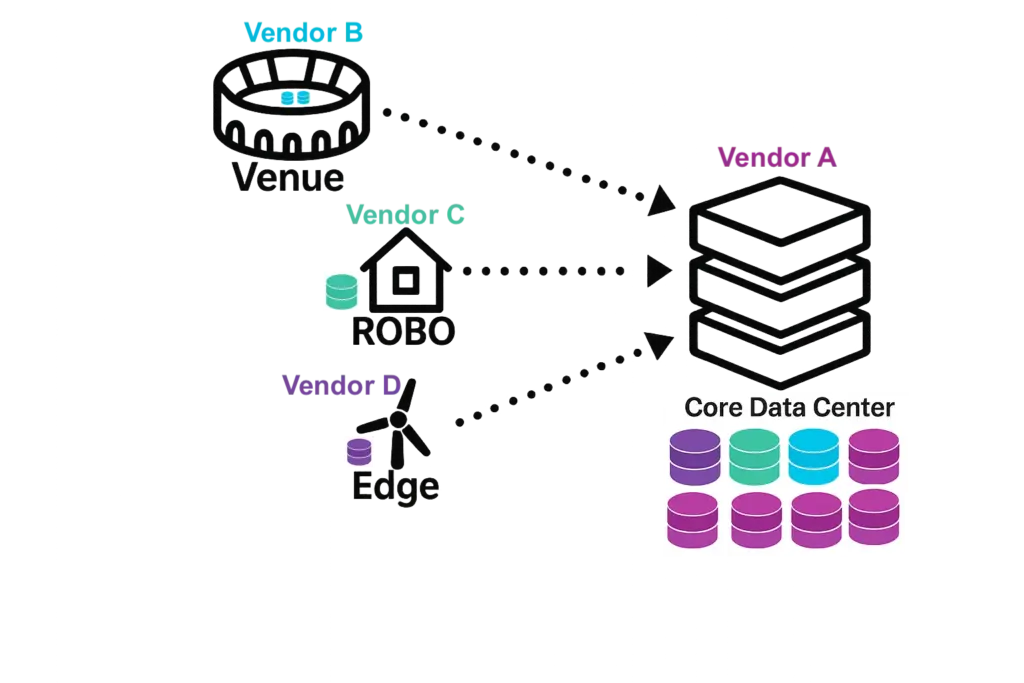
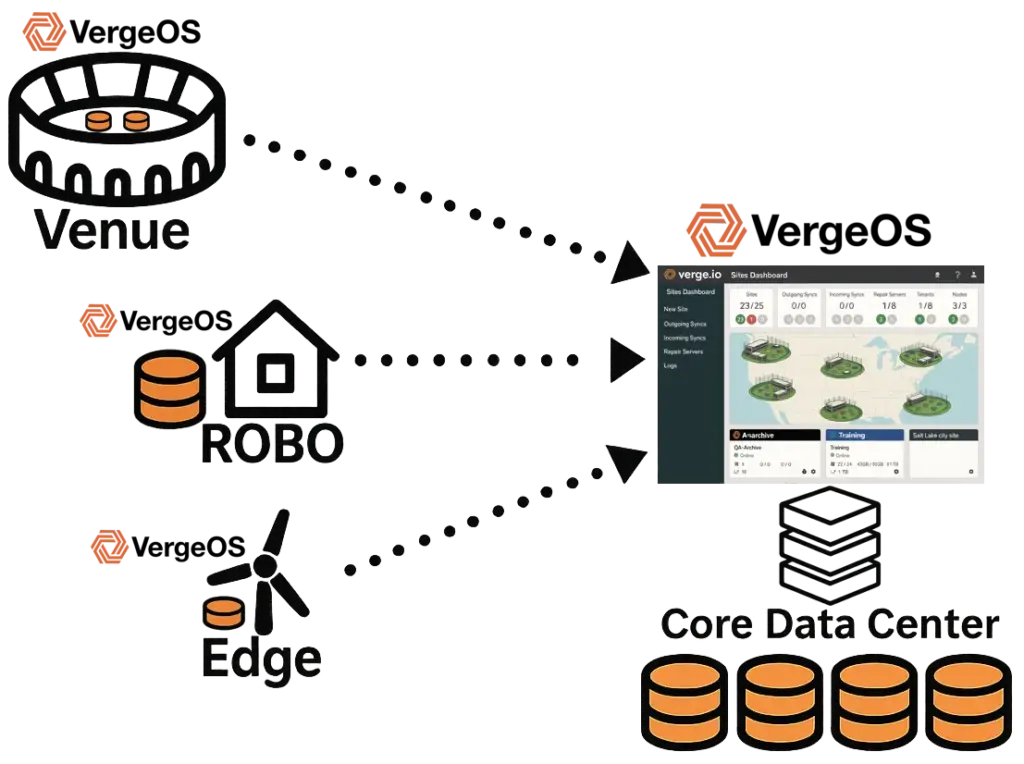
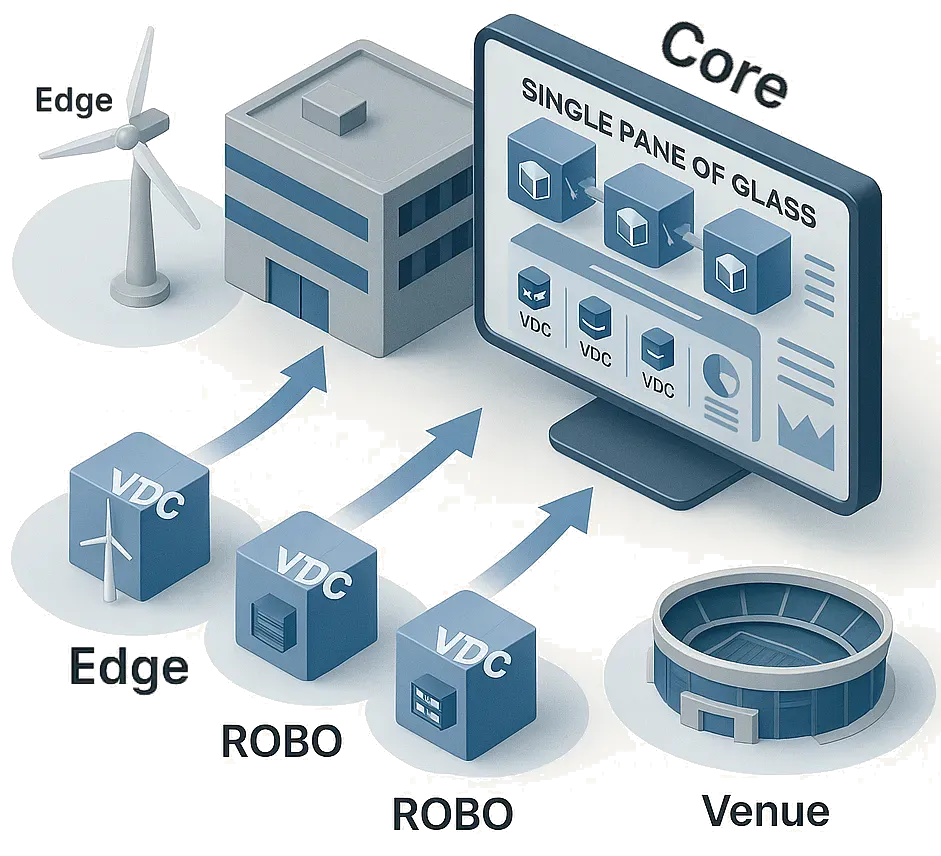
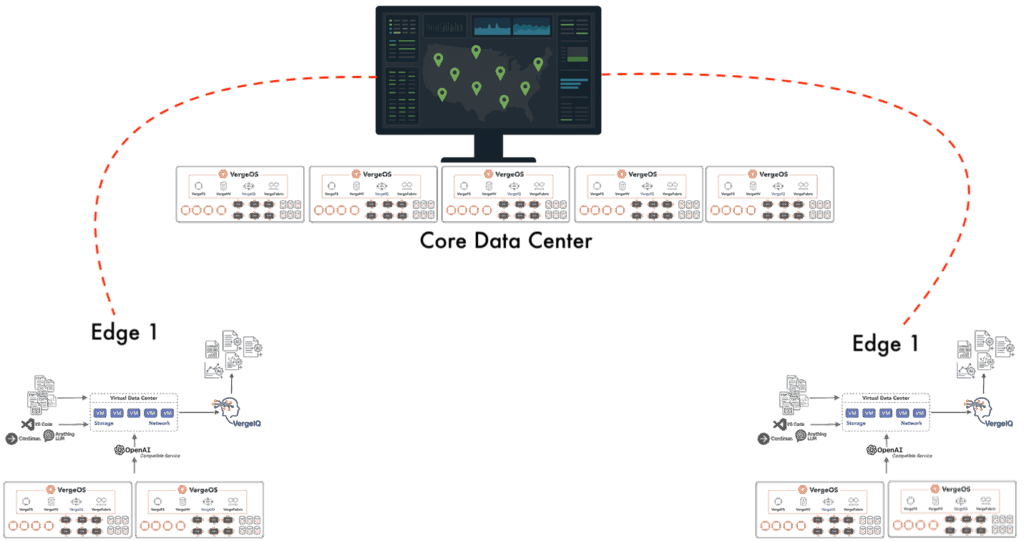
- VergeOS replaces stacked products with a single operating system covering virtualization, storage, networking, and AI. Per-server licensing, hardware portability, and deep abstraction extend hardware life and simplify operations across core, edge, ROBO (remote office/branch office), and Venues.
Review the VergeIO/Cirrus Data solution brief to learn more.
“Sprawl is the tax on indecision,” said Yan Ness, CEO of VergeIO. “Enterprises didn’t plan to run three hypervisors and a cloud sidecar, but that’s where the market led them. Our partnership with Cirrus Data gives IT a practical way out: move everything with minimal downtime and land on a single, cohesive platform.”
“Consolidation isn’t a one-off,” said Wayne Lam, CEO of Cirrus Data. “Our data mobility solutions give organizations an easy, automated way to securely migrate every acquisition or new business unit to VergeOS quickly, regardless of the starting platform. With Cirrus Data and VergeIO, organizations can prevent sprawl from returning and keep operations streamlined.”
According to analysis highlighted in VergeIO’s new white paper and solution brief, enterprises that consolidate into VergeOS with Cirrus Data can reduce three-year total cost of ownership by 50%+, achieve 12–18 month payback, and gain a platform ready for private AI without standing up separate clusters.

To learn more, register here for the VergeIO/Cirrus webinar on 9/25 at 1:00pm ET.
About VergeIO
VergeIO is the VMware alternative. Its ultraconverged infrastructure platform, VergeOS, integrates virtualization, storage, networking, and AI into a single operating system with unmatched simplicity and cost savings. Headquartered in Ann Arbor, Michigan, VergeIO helps enterprises, service providers, and public sector organizations consolidate infrastructure, extend hardware life, and prepare for the future of AI.
About Cirrus Data
Cirrus Data Solutions Inc. (CDS) is a leader in the block data mobility technology and services market for global enterprises. The company distributes its solutions through systems integrators, managed service providers, channel resellers, and partners. CDS is headquartered in Syosset, New York, with support centers in Dublin, Ireland, and Nanjing, China, with sales and support offices in Atlanta, Chicago, New York, Dallas, Denver, London, Melbourne, Munich, and Tampa. For more information, visit CDS online https://cirrusdata.com/cloud-migration-vergeio
Media Contact:
Judy Smith
JPR for [email protected]
818-522-9673
Media Contact:
Julie McKenna
Cirrus Data
[email protected]