When considering an alternative to VMware, it’s essential to elevate your infrastructure rather than simply seeking cost savings. Elevating your infrastructure means improving data protection, resiliency, and availability—critical elements that should define your next virtualization platform. In this post, we’ll explore the key features you should demand in a modern virtualization platform, and how VergeIO delivers on those expectations.
How to Elevate Your Infrastructure with Better Data Resilience
Snapshot Technology
In today’s IT environments, preparing for potential data loss, corruption, or accidental deletions is crucial. One of the most vital features in any virtualization platform is advanced snapshot technology. Traditional snapshots are often plagued by performance bottlenecks and limited retention, resulting in large gaps in protection. Many organizations are forced to take only one snapshot per day to feed their backup software, which is no longer enough.
To elevate your infrastructure, your VMware alternative should provide frequent, independent snapshots that don’t rely on redirect-on-write techniques. These snapshots should maintain system performance while allowing multiple snapshots throughout the day. This enhances Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO), ensuring fast recovery when needed.
Workload Isolation
Secure workload isolation is key to protecting mission-critical workloads. Multi-tenancy ensures individual workloads are isolated for better performance and enhanced security. With an elevated infrastructure, you can place mission-critical applications in their own tenants, isolating them from less critical workloads. If ransomware attacks a user workload, it won’t spread to other tenants.
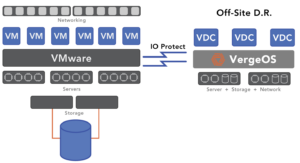
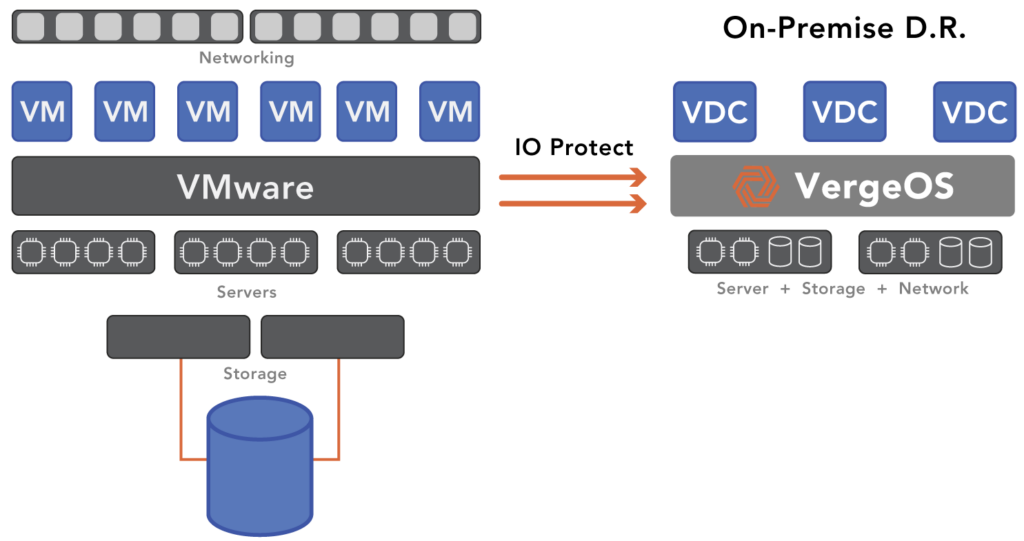
Multi-tenancy also streamlines disaster recovery (DR). By encapsulating consistent states of networking, storage, and virtual machines, the failover process becomes simpler and more reliable, improving your DR capabilities. Frequent testing becomes easier, encouraging proactive planning.
Key considerations include:
- Robust isolation mechanisms to protect workloads.
- Custom backup policies for each workload.
- Encapsulated DR processes for easy recovery.
Protection from Hardware Failures
Look for a VMware alternative that can elevate your infrastructure by withstanding multiple simultaneous hardware failures. While most platforms can handle a single failure, resilient virtualization solutions keep workloads running even during multiple failures.
Look for virtualization platforms that offer self-healing capabilities to automatically reroute workloads to available hardware, ensuring minimal downtime. Solutions that provide affordable redundancy can enable high availability without requiring excessive resources.
Disaster Recovery
A comprehensive disaster recovery (DR) plan is key to elevating your infrastructure. While backup solutions play a crucial role, they must be paired with automated disaster recovery capabilities. DR should be fully integrated into the platform, with failover and failback processes automated to ensure that workloads remain available during outages. Frequent DR testing without disrupting production is also essential for preparing your infrastructure for worst-case scenarios.
Importance of a Separate Backup Process for Long-Term Retention
While advanced snapshots and disaster recovery are critical, they cannot replace the need for a separate backup process to ensure compliance with the 3-2-1 backup rule. This rule mandates that organizations maintain three copies of their data: two on different storage media and one offsite.
An effective VMware alternative should integrate seamlessly with separate backup solutions that can provide long-term retention and offsite storage. This process ensures compliance, protects against ransomware, and meets legal or regulatory data retention requirements. Moreover, having a distinct backup solution enables organizations to recover data from further back in time, providing more flexibility and protection in the event of an unexpected disaster or human error.
Backup considerations include:
- Immutable backups that cannot be modified or deleted, providing extra protection against ransomware.
- Offsite storage for compliance with the 3-2-1 rule.
- Long-term retention capabilities that meet regulatory and legal requirements.
VergeIO: Elevate Your Infrastructure
Among the many VMware alternatives, VergeIO stands out by offering more than just an alternative—it elevates your infrastructure, particularly in the realm of data protection and resiliency.
Elevate Your Infrastructure with Advanced IOclone Technology
VergeOS’s IOclone technology takes data protection to the next level. Unlike traditional snapshots that slow down performance and use excessive storage, IOclone creates fully independent snapshots of virtual machines, instances, or virtual data centers. Snapshots are optimized with inline deduplication, maximizing storage efficiency while maintaining high performance.
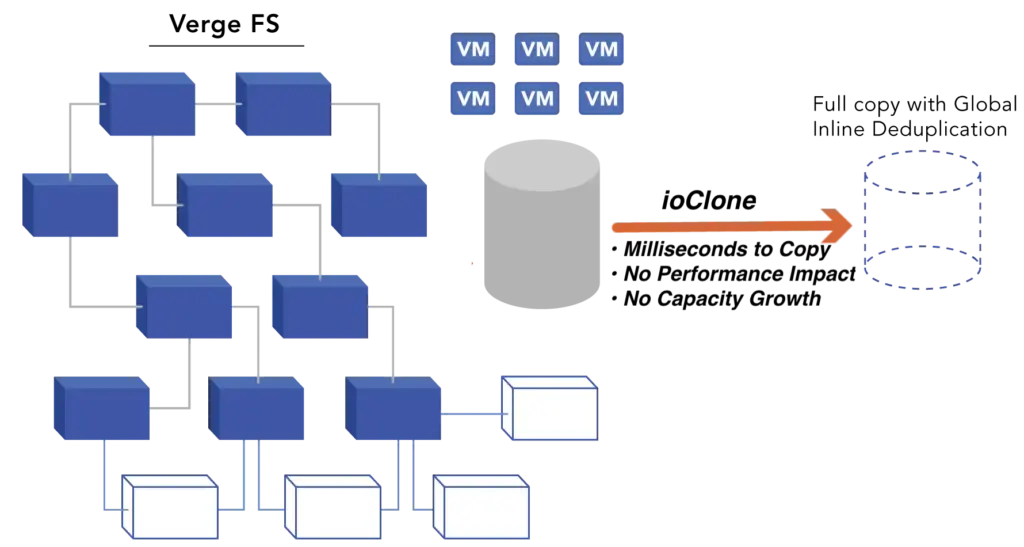
These independent snapshots mean that even if the original data is deleted, the snapshot remains intact. This capability allows IT teams to take frequent snapshots and reduce their RPO and RTO, enabling granular recovery of full virtual data centers, individual VMs, or even specific files. Experience using snapshots for granular recovery in our hands-on lab.
Elevate Your Infrastructure with Virtual Data Centers
VergeOS provides secure multi-tenancy but takes it a step further by delivering virtual data centers for each tenant. These virtual data centers encapsulate networking, storage, and compute resources into consolidated objects, allowing complete environments to be recovered quickly during outages.
This encapsulation minimizes recovery delays, offering a more robust approach to disaster recovery by ensuring all configuration files are in sync and workloads are restored seamlessly. See how to use virtual data centers right now in our hands-on lab.
Elevate Your Infrastructure by Protecting it from Hardware Failures
VergeOS’ self-healing architecture detects failures in real-time, rerouting workloads automatically to minimize downtime. VergeOS provides affordable redundancy, ensuring high availability without the need for resource duplication.
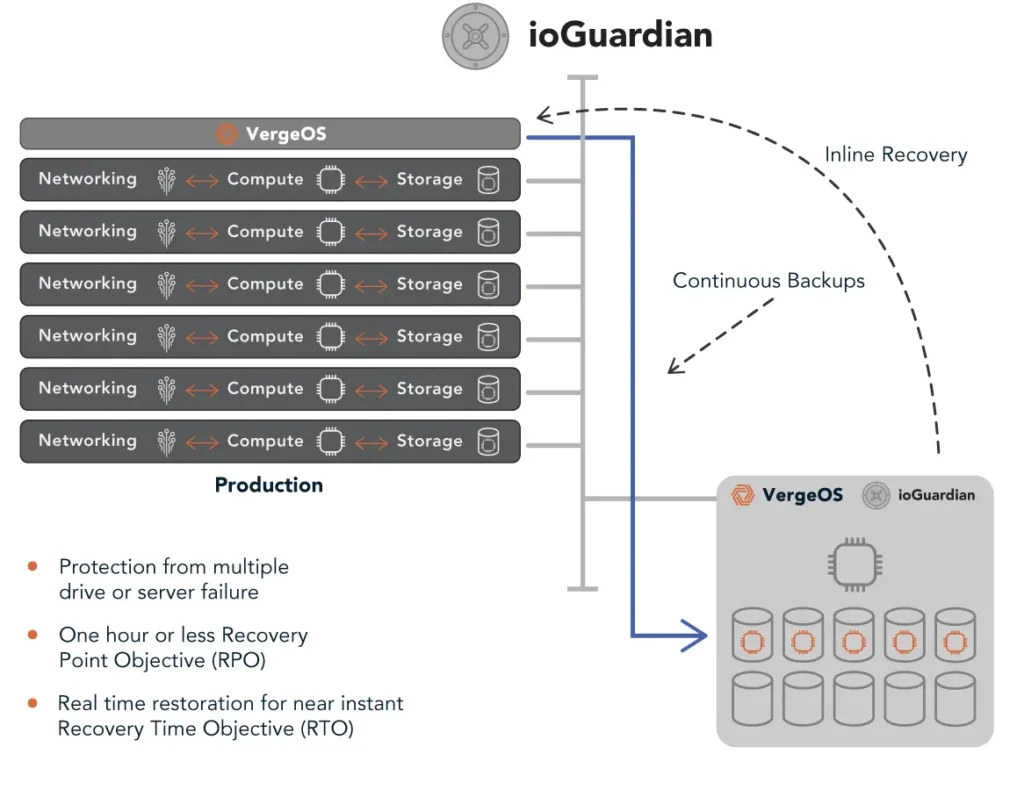
For greater protection, VergeOS includes ioGuardian, an integrated capability which offers inline recovery in case of catastrophic multiple simultaneous hardware failures. ioGuardian delivers missing data segments to virtual machines in real-time, enabling VMs to remain operational and saving you from resorting to your backup software.
Elevate Your Infrastructure by Exceeding the 3-2-1 Rule
While VergeOS provides robust snapshot technology and integrated disaster recovery, working with Storware ensures complete compliance with the 3-2-1 backup rule. Storware offers an advanced backup solution that integrates seamlessly with VergeOS’s snapshot capabilities, allowing organizations to meet long-term retention and offsite storage requirements.
Storware’s incremental forever backups ensure that only changed data is backed up after the initial full backup, minimizing storage use while still offering comprehensive protection. Storware also supports immutable backups, which are critical for protecting against ransomware and accidental deletions.
Conclusion: VergeIO is the Future of Virtualization
Don’t just settle for a VMware alternative that maintains the status quo. Elevate your infrastructure with VergeIO, a solution that improves snapshot technology, workload isolation, resiliency against failures, and integrated disaster recovery.
Next Steps
- Explore more about VergeIO’s approach to data protection through our on-demand webinar “Protecting VergeOS.”
- Experience VergeOS first-hand by signing up for our hands-on lab here.
- Download our solution brief for an in-depth look at how VergeIO and Storware provide complete data protection.