The ability to reduce RAM consumption may be the most important factor in choosing a VMware alternative in 2026. What started as a licensing decision after Broadcom’s acquisition has become an infrastructure economics decision. Organizations began evaluating replacements to escape licensing uncertainty. Then the Flash and Memory Supercycle hit.
Key Takeaways
- The Memory and Flash Supercycle is driving DRAM prices up 171% YoY through 2027, NAND flash up 55–60% in a single quarter, and server deliveries delayed by months. VMware licensing changes from Broadcom compound the pressure.
- Memory ballooning, transparent page sharing, and hypervisor swapping are reactive workarounds that manage scarcity after it occurs. None of them reduce total physical RAM requirements.
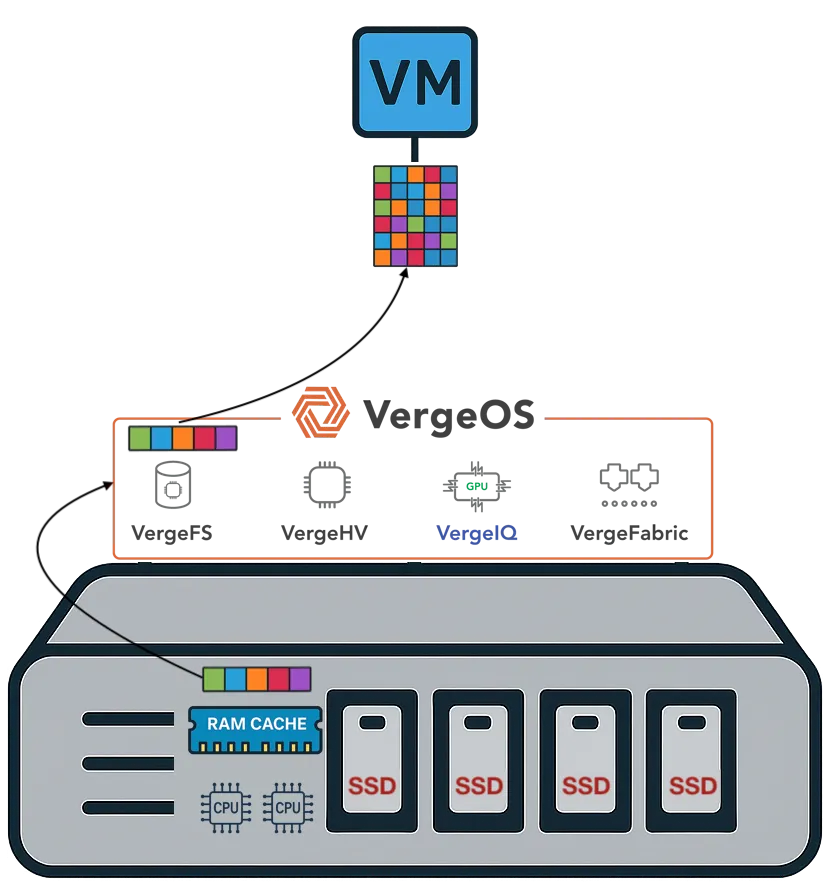
- VergeOS integrates virtualization, storage, networking, and data protection into a single code base that runs at 2–3% memory overhead, compared to the double-digit percentages consumed by multi-product stacks.
- Topgolf reduced server count by 50% per venue across 100+ locations. Alinsco Insurance migrated a mission-critical VxRail environment during business hours with zero downtime and gained memory headroom on the same hardware.
- VergeOS runs safely on commodity NVMe drives, uses global inline deduplication to reduce flash capacity requirements, and delivers snapshot-driven local replication through ioGuardian that protects against multiple simultaneous drive failures without hardware RAID.
- The platform’s global deduplicated cache operates across all VMs across all nodes, caching only unique data blocks from the already-deduplicated storage pool. This drives higher cache hit rates and fewer flash reads without wasting RAM on redundant cached data.
DRAM prices are expected to increase 171% year-over-year through 2027. NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server orders that once shipped in weeks now face multi-month delivery delays. The platform you choose now determines how much RAM, flash, and hardware you need for the next three to five years.
Finding a VMware alternative is still the primary mission. But the supercycle raises the bar. It is no longer enough to swap one hypervisor for another just because it costs less to license. The replacement must also reduce RAM consumption per workload, require fewer servers, and reduce flash storage costs. Any platform that relies on memory ballooning, transparent page sharing, or hypervisor swapping to manage RAM is using the same software tricks the industry has relied on for years. Those techniques react to memory pressure after it occurs. None of them reduce the total physical RAM your infrastructure actually requires.
Key Terms
- Memory and Flash Supercycle — A sustained period of rising DRAM and NAND flash prices driven by AI infrastructure demand, DDR4 end-of-life, and constrained fabrication capacity. Industry analysts project tight supply through at least 2027.
- Memory Ballooning — A hypervisor technique that uses a guest driver to reclaim unused RAM from idle VMs. Reactive by design, it fails under tight VM sizing and causes cascading performance degradation when multiple VMs spike simultaneously.
- Transparent Page Sharing (TPS) — A memory deduplication technique that merges identical OS pages across VMs. Limited to identical pages, disabled by default in VMware since 2014 due to security concerns, and ineffective for application data.
- Global Inline Deduplication — VergeOS technology that identifies and eliminates duplicate data blocks at the storage layer before they are written to flash. Reduces total flash capacity requirements, lowers write amplification to extend drive life, and feeds only unique blocks into the RAM cache.
- Global Deduplicated Cache — A VergeOS RAM cache that operates across all VMs across all nodes and draws from the already-deduplicated storage pool. Holds only unique data blocks, increasing effective cache capacity and hit rates without the CPU overhead of a separate cache-level deduplication algorithm.
- ioGuardian — VergeOS data availability technology that uses snapshot-driven local replication to protect against multiple simultaneous drive failures. Eliminates the need for hardware RAID controllers and delivers consistent performance during failures and rebuilds.
- Commodity NVMe — Standard NVMe solid-state drives that cost significantly less than enterprise or server-class SSDs. VergeOS makes commodity drives production-safe through software-managed wear leveling, global deduplication to reduce writes, and ioGuardian replication to handle failures gracefully.
We are hosting a live webinar on March 12 that goes deeper into each of these points. Register for Architecting for the Flash and Memory Supercycle to see how the platform decisions you make today determine your infrastructure costs for the next three to five years.
Start with an Efficient Code Base That Reduces RAM Consumption
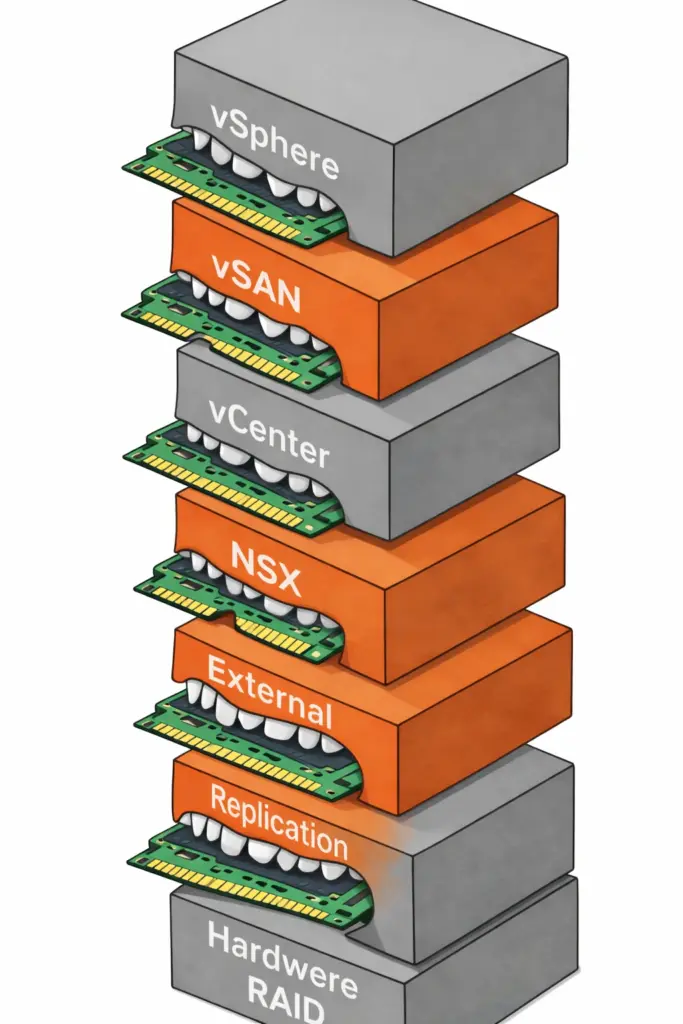
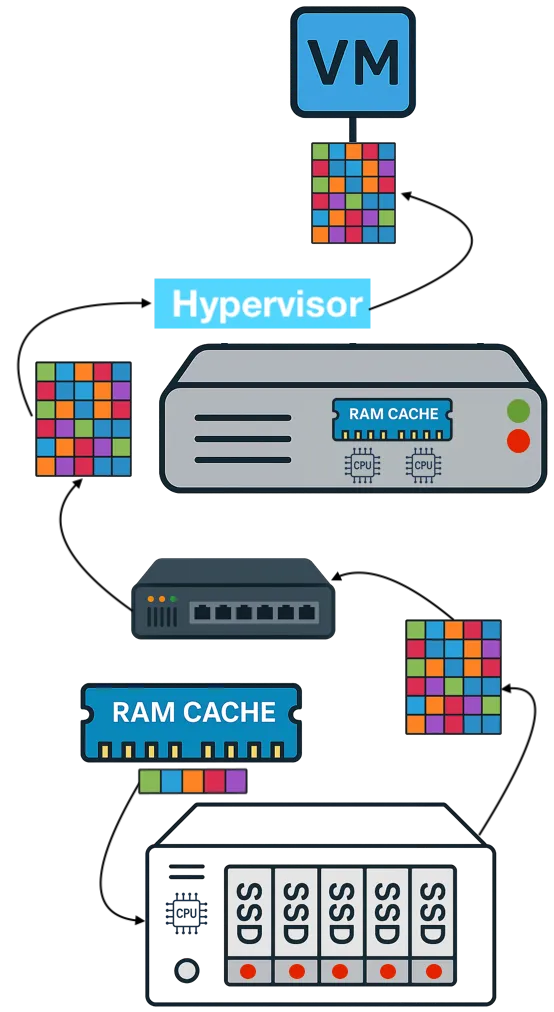
The first question to ask any VMware alternative is how much RAM the platform itself consumes before a single VM even starts. VMware environments running vSphere, vSAN, vCenter, and NSX stack four separate products on every host. Each product reserves memory for its own management processes. Add external replication software and hardware RAID controllers, and the cumulative overhead climbs even further.
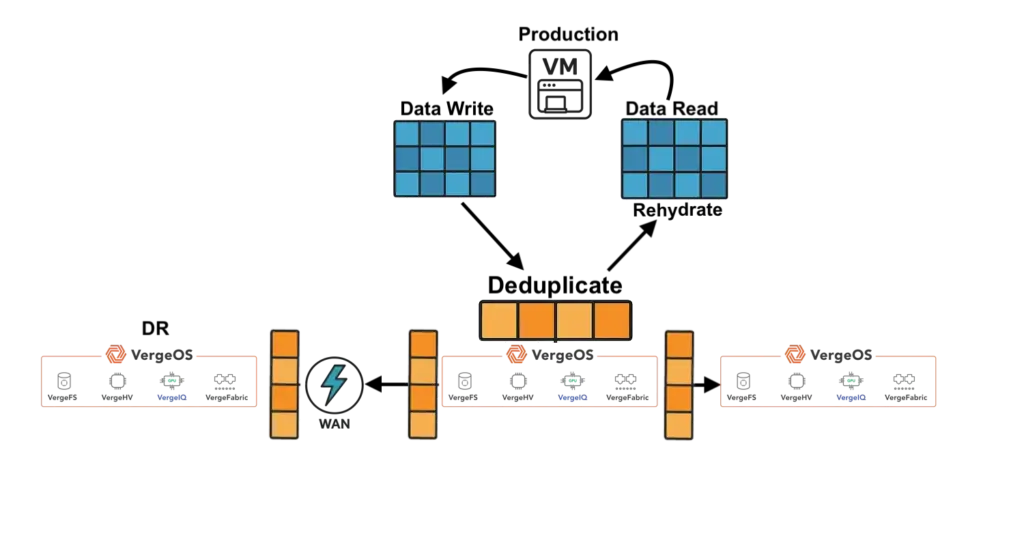
VergeOS takes a different architectural approach. It delivers a complete private cloud operating system that integrates virtualization, storage, networking, and data protection as services within a single code base. There is no separate storage product. There is no separate networking product. The platform is built with global deduplication, enabling synchronous replication without the typical capacity impact and delivering better, more consistent performance in production and during failures.
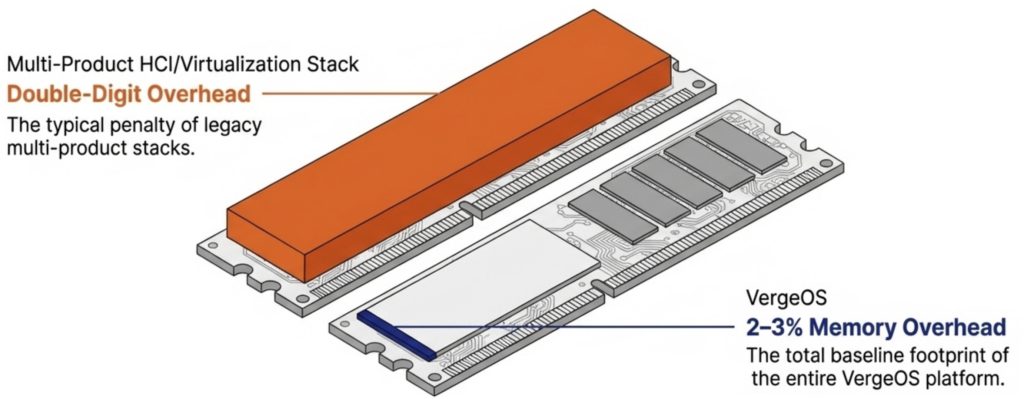
It eliminates the need for hardware RAID controllers, which are also increasing in price because they consume RAM. VergeOS includes built-in data replication for disaster recovery, and its global inline deduplication reduces capacity costs at the disaster recovery site as well. The entire platform runs at 2–3% memory overhead. Compare that to the double-digit percentages consumed by multi-product virtualization stacks and HCI platforms that reserve tens of gigabytes per node before workloads even start.
A lower baseline means more RAM available for production workloads on the same hardware. During a supercycle, that difference translates directly into fewer servers needing to be purchased at inflated prices.
Use Existing Hardware and Reduce How Much You Need
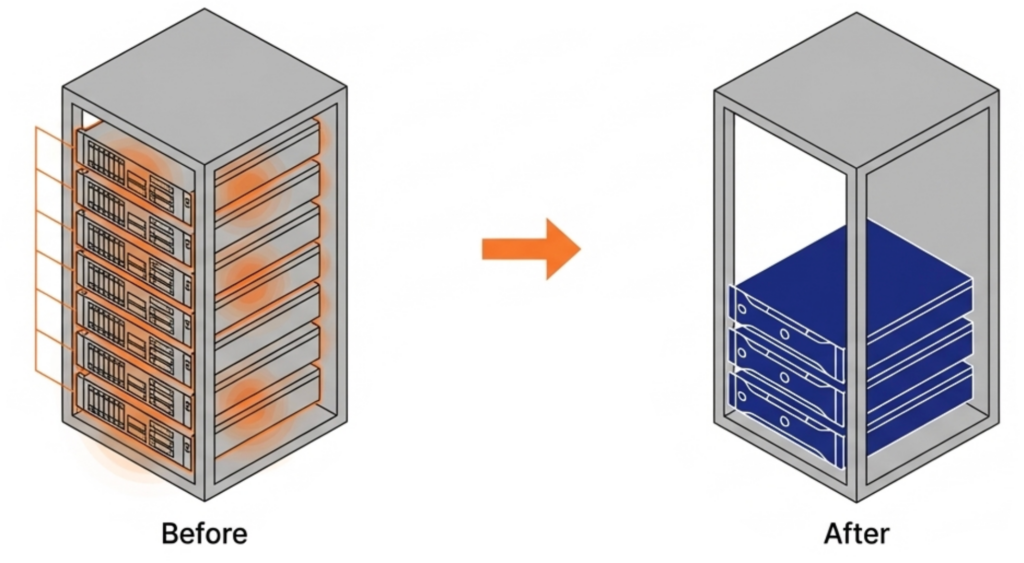
VergeOS installs on any x86 server from any manufacturer. Organizations migrating from VMware continue to run on the same physical servers they already own. There is no hardware forklift upgrade. No waiting six months for new server deliveries that keep getting pushed back as memory and flash shortages worsen. The servers, RAM, and SSDs already purchased and deployed remain in production.
Getting there does not require the purchase of a parallel environment or even a maintenance window. VergeOS supports node-by-node migration from VMware. Evacuate workloads from one host, install VergeOS on that host, migrate VMs onto the new platform, and repeat across the remaining hosts. Production continues running throughout the process. Alinsco Insurance completed this on a five-node VxRail cluster running a mission-critical insurance application that cannot tolerate downtime. The team migrated node by node during business hours with zero downtime. Critical web servers were moved at night out of an abundance of caution, but even those migrations produced no service interruption. During a supercycle, this approach eliminates the capital expense of purchasing a second set of servers to stand up alongside the existing environment.

Because VergeOS consumes less RAM per host, organizations can increase VM density and consolidate to fewer servers. Topgolf, operating more than 100 venues globally, reduced each site from six-node VxRail clusters to three-node VergeOS clusters. That is a 50% server reduction per venue. Alinsco Insurance continued to run on the same VxRail hardware and internal SSDs after migration, and servers that felt constrained under VMware gained additional headroom under VergeOS.
The freed servers create immediate value. One becomes a dedicated ioGuardian server, delivering N+2 or greater (N+X) data protection without purchasing new hardware or hardware RAID. The remaining servers become part donors. Pull the DRAM and NVMe drives and redistribute them across the active production nodes. VergeOS supports mixed node types and mixed node roles in the same cluster, so the redistribution does not require matching hardware specifications.
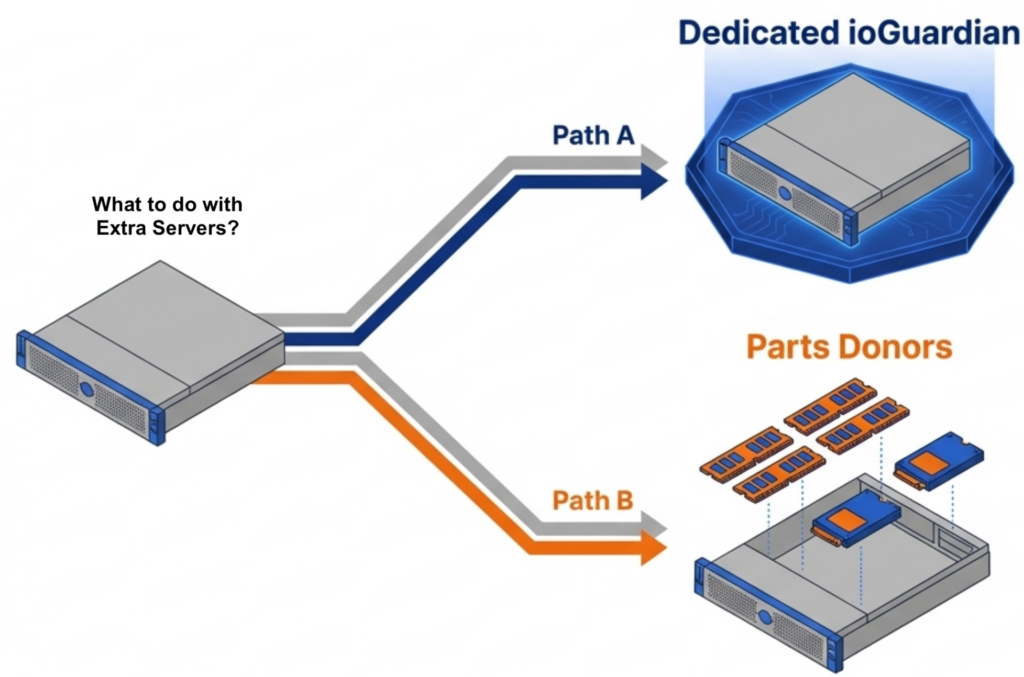
Reduce Flash Costs with Commodity SSDs
The supercycle affects flash storage as well as memory. Enterprise and server-class SSDs carry steep price premiums that continue to climb alongside NAND contract prices. Commodity NVMe drives are rising in price, too. But the price gap between enterprise and commodity is widening, not narrowing, and commodity drives do seem to be more readily available. Organizations that can safely run on commodity flash pay less per terabyte today relative to enterprise alternatives than they did a year ago.
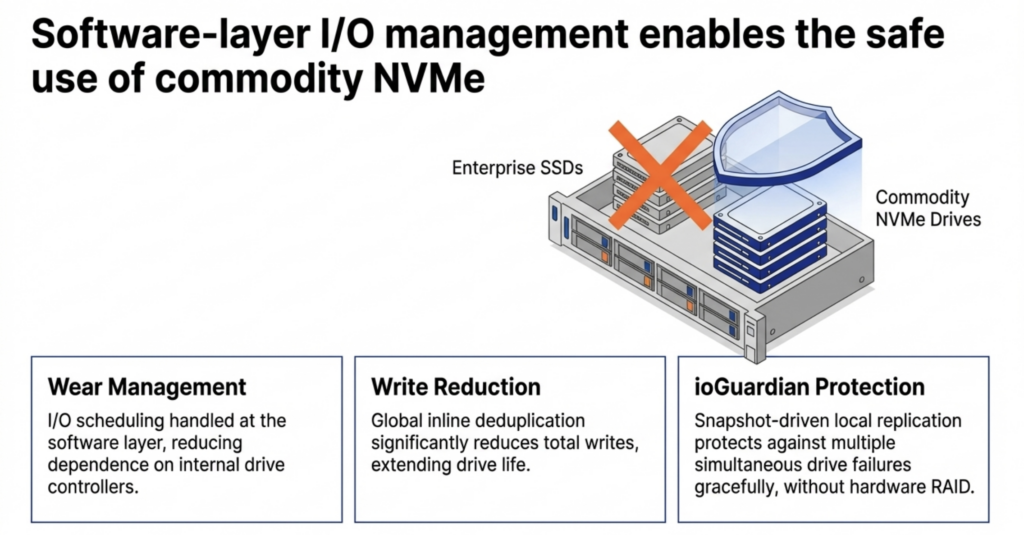
VergeOS runs safely on commodity SSDs. The platform’s storage engine manages I/O scheduling and wear management at the software layer, reducing dependence on the drive’s internal controller. Global inline deduplication reduces total writes to each drive, directly extending drive life. ioGuardian’s snapshot-driven local replication protects against multiple simultaneous drive failures without data loss or downtime, so that a commodity drive that wears out faster than an enterprise drive is replaced gracefully. No hardware RAID controller is required. The combination makes commodity flash a production-safe choice at a fraction of the cost of enterprise SSDs.
A Cache That Benefits from Deduplication
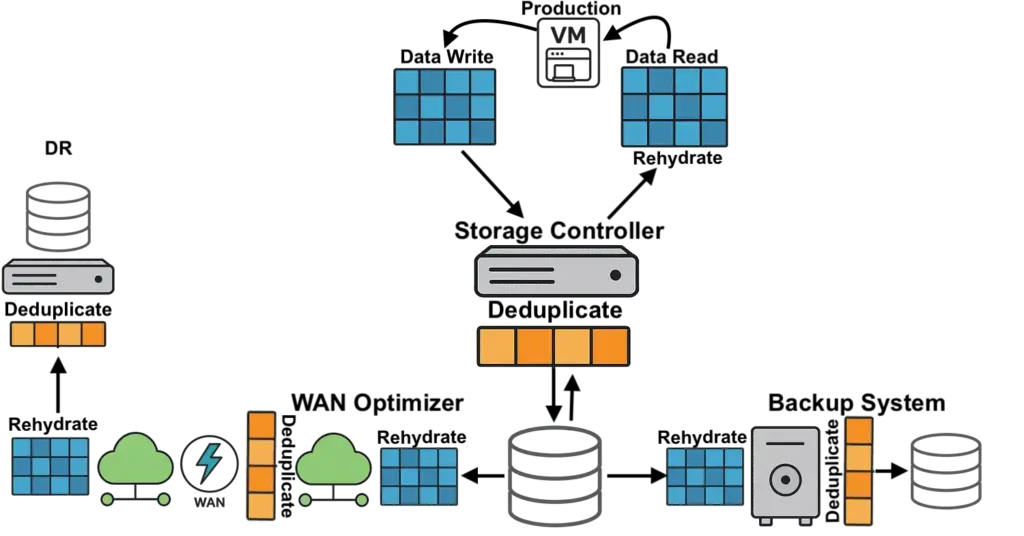
Most virtualization platforms cache storage data independently on each node. If ten nodes access the same data block, ten separate copies sit in ten separate caches. That wastes RAM on redundant data across the cluster.
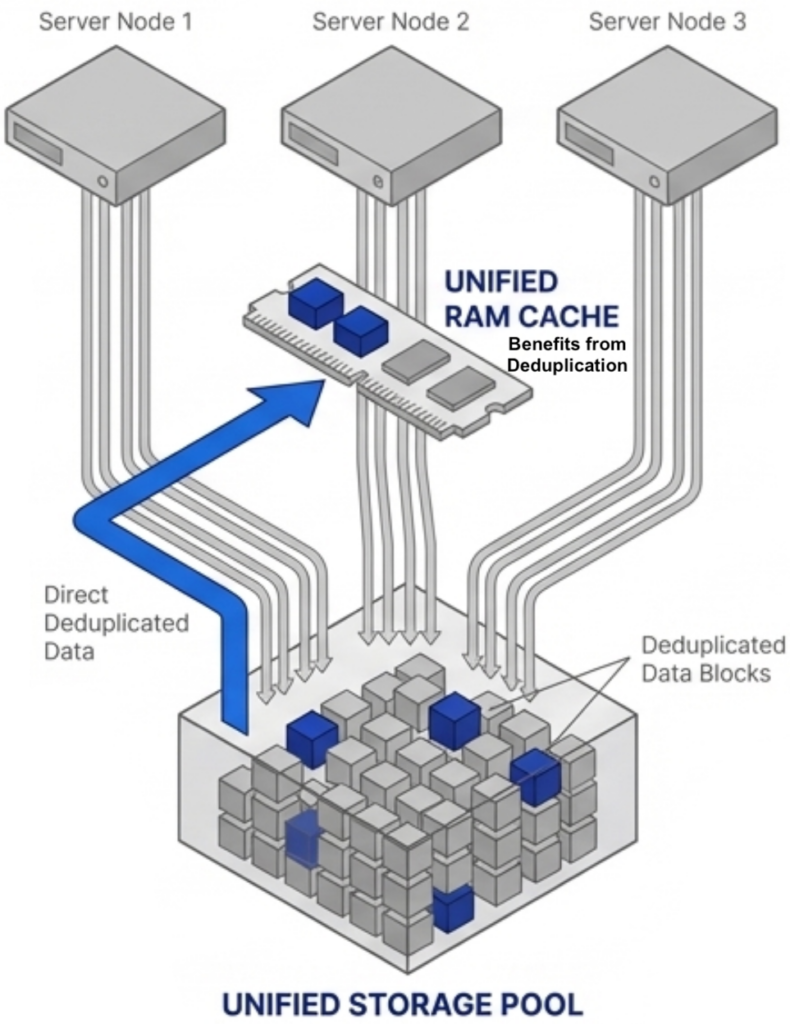
VergeOS approaches caching differently. The platform performs global inline deduplication at the storage layer, so the storage pool contains only unique blocks. The RAM cache operates across all VMs across all nodes and draws from that already-deduplicated pool. The cache holds only unique data without running a separate deduplication algorithm inside the cache itself. More unique blocks fit in the same physical RAM, driving higher cache hit rates and fewer reads from flash.
An important factor in making this work across nodes is VergeOS’s optimized internode communication protocol, purpose-built for this use case and free from the overhead of chatty iSCSI or NFS protocols. We will explore the technical details of this architecture in an upcoming post. The takeaway for now: VergeOS does not waste RAM caching duplicate data.
The VMware Alternative Decision Just Got Bigger
The search for a VMware alternative is no longer just about licensing. The supercycle means the platform you choose determines your RAM consumption, your flash costs, your server count, and how long your existing hardware stays in production. Choose a platform that relies on the same memory tricks the industry has used for decades, and you inherit the same overhead during the most expensive hardware market in years. Choose a platform built to reduce RAM consumption from a single efficient code base with built-in data availability, and you start with less overhead, run on the servers you already own, and reduce how many you need going forward.
Frequently Asked Questions
- What is the Flash and Memory Supercycle? — A sustained period of rising DRAM and NAND flash prices driven by AI infrastructure demand, DDR4 end-of-life, and constrained fabrication capacity. DRAM prices are expected to increase 171% year-over-year through 2027, and NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server delivery times have extended to multi-month delays.
- Why don’t memory ballooning and transparent page sharing solve the problem? — These are reactive techniques that manage memory pressure after it occurs. Memory ballooning reclaims unused RAM from idle VMs but fails under tight sizing. Transparent page sharing merges identical OS pages but has been disabled by default in VMware since 2014 due to security concerns. Neither technique reduces the total physical RAM your infrastructure requires.
- How much RAM overhead does VergeOS consume? — The entire VergeOS platform — including virtualization, storage, networking, and data protection — runs at 2–3% memory overhead. Compare that to multi-product VMware stacks that consume double-digit percentages, or HCI platforms like Nutanix that reserve 24–32 GB per node for controller VMs before workloads start.
- Can I migrate from VMware without buying new servers? — Yes. VergeOS installs on any x86 server from any manufacturer and supports node-by-node migration from VMware. Evacuate workloads from one host, install VergeOS, migrate VMs onto the new platform, and repeat. The servers, RAM, and SSDs you already own stay in production. Alinsco Insurance completed this on a five-node VxRail cluster during business hours with zero downtime.
- How does VergeOS reduce the number of servers needed? — Lower platform overhead means more RAM available for production workloads on each host, which increases VM density. Topgolf reduced each venue from six-node VxRail clusters to three-node VergeOS clusters — a 50% server reduction across more than 100 locations. Freed servers become parts donors or dedicated ioGuardian data protection nodes.
- Is it safe to run commodity NVMe drives in production? — With VergeOS, yes. The storage engine manages I/O scheduling and wear management at the software layer. Global inline deduplication reduces total writes to each drive, extending drive life. ioGuardian’s snapshot-driven local replication protects against multiple simultaneous drive failures without hardware RAID, so a commodity drive that wears faster is replaced gracefully with no data loss or downtime.
- How does VergeOS cache data differently from VMware or Nutanix? — Most platforms cache storage data independently on each node, meaning duplicate blocks are cached separately on every host. VergeOS performs global inline deduplication at the storage layer first, then the RAM cache draws from the already-deduplicated pool. The cache holds only unique blocks across all VMs across all nodes, using an optimized internode protocol instead of iSCSI or NFS. More unique data fits in the same physical RAM, driving higher cache hit rates.
- What happens to servers freed up after consolidation? — One freed server becomes a dedicated ioGuardian node, delivering N+2 or greater data protection without a new hardware purchase and without hardware RAID. The remaining servers become parts donors — pull the DRAM and NVMe drives and redistribute them across active production nodes. VergeOS supports mixed node types and mixed node roles, so no matching hardware specifications are required.
A sustained period of rising DRAM and NAND flash prices driven by AI infrastructure demand, DDR4 end-of-life, and constrained fabrication capacity. DRAM prices are expected to increase 171% year-over-year through 2027, and NAND flash contract prices jumped 55–60% in Q1 2026 alone. Server delivery times have extended to multi-month delays.
These are reactive techniques that manage memory pressure after it occurs. Memory ballooning reclaims unused RAM from idle VMs but fails under tight sizing. Transparent page sharing merges identical OS pages but has been disabled by default in VMware since 2014 due to security concerns. Neither technique reduces the total physical RAM your infrastructure requires.
The entire VergeOS platform — including virtualization, storage, networking, and data protection — runs at 2–3% memory overhead. Compare that to multi-product VMware stacks that consume double-digit percentages, or HCI platforms like Nutanix that reserve 24–32 GB per node for controller VMs before workloads start.
Yes. VergeOS installs on any x86 server from any manufacturer and supports node-by-node migration from VMware. Evacuate workloads from one host, install VergeOS, migrate VMs onto the new platform, and repeat. The servers, RAM, and SSDs you already own stay in production. Alinsco Insurance completed this on a five-node VxRail cluster during business hours with zero downtime.
Lower platform overhead means more RAM is available for production workloads on each host, increasing VM density. Topgolf reduced each venue from six-node VxRail clusters to three-node VergeOS clusters — a 50% reduction in servers across more than 100 locations. Freed servers become parts donors or dedicated ioGuardian data protection nodes.
With VergeOS, yes. The storage engine manages I/O scheduling and wear management at the software layer. Global inline deduplication reduces total writes to each drive, extending drive life. ioGuardian’s snapshot-driven local replication protects against multiple simultaneous drive failures without hardware RAID, so a commodity drive that wears faster is replaced gracefully with no data loss or downtime.
Most platforms cache storage data independently on each node, meaning duplicate blocks are cached separately on every host. VergeOS performs global inline deduplication at the storage layer first, then the RAM cache draws from the already-deduplicated pool. The cache holds only unique blocks across all VMs across all nodes, using an optimized internode protocol instead of iSCSI or NFS. More unique data fits in the same physical RAM, driving higher cache hit rates.
One freed server becomes a dedicated ioGuardian node, delivering N+2 or greater data protection without a new hardware purchase and without hardware RAID. The remaining servers become parts donors — pull the DRAM and NVMe drives and redistribute them across active production nodes. VergeOS supports mixed node types and mixed node roles, so no matching hardware specifications are required.