Universities are leaving VMware for two main reasons. First, the Broadcom acquisition changed the economics of virtualization. Second, premature hardware deprecation often forces server refreshes years earlier than scheduled. Educational discounts vanished. Per-core licensing turned predictable capital expenses into escalating operational costs. Support quality declined. For many institutions, the math no longer works.
The question is no longer whether to consider alternatives. The question is how to execute a successful exit without disrupting operations, exhausting small IT teams, or requiring massive capital investment.
Why Universities Are Leaving VMware

The reasons universities are leaving VMware remain consistent across institutions. Annual licensing costs that once ranged from $20,000 to $25,000 now climb to $45,000 to $55,000 or higher. For institutions operating on lean budgets, this represents money that could fund scholarships, faculty positions, or student services. VMware and competing platforms often require certified hardware or push expensive infrastructure upgrades. Universities with viable servers that are 3 to 5 years old are told they need to spend $50,000 to $70,000 on replacements.
Educational institutions report longer response times, unanswered support tickets, and reduced access to technical resources, even with paid support contracts. Product consolidation, feature changes, and bundle restructuring create uncertainty about long-term viability and cost predictability. These factors combine to make the exit decision less about dissatisfaction and more about survival.
What Higher Education Cannot Compromise
Any VMware alternative must meet the unique needs of higher education without forcing tradeoffs that compromise operations. Learning management systems, student information systems, and research workloads cannot tolerate extended downtime, so small teams need platforms that are easy to manage without specialized expertise or additional staff. The solution must reduce the total cost of ownership rather than shift expenses around, and existing infrastructure should remain usable to avoid capital expenditures. Built-in backup, disaster recovery, and ransomware protection eliminate the need for separate tools and vendors. The platform should support student learning and provide hands-on IT experience that prepares them for careers.
The challenge is finding a solution that checks all these boxes without compromise.
Why Universities are leaving VMware for VergeOS
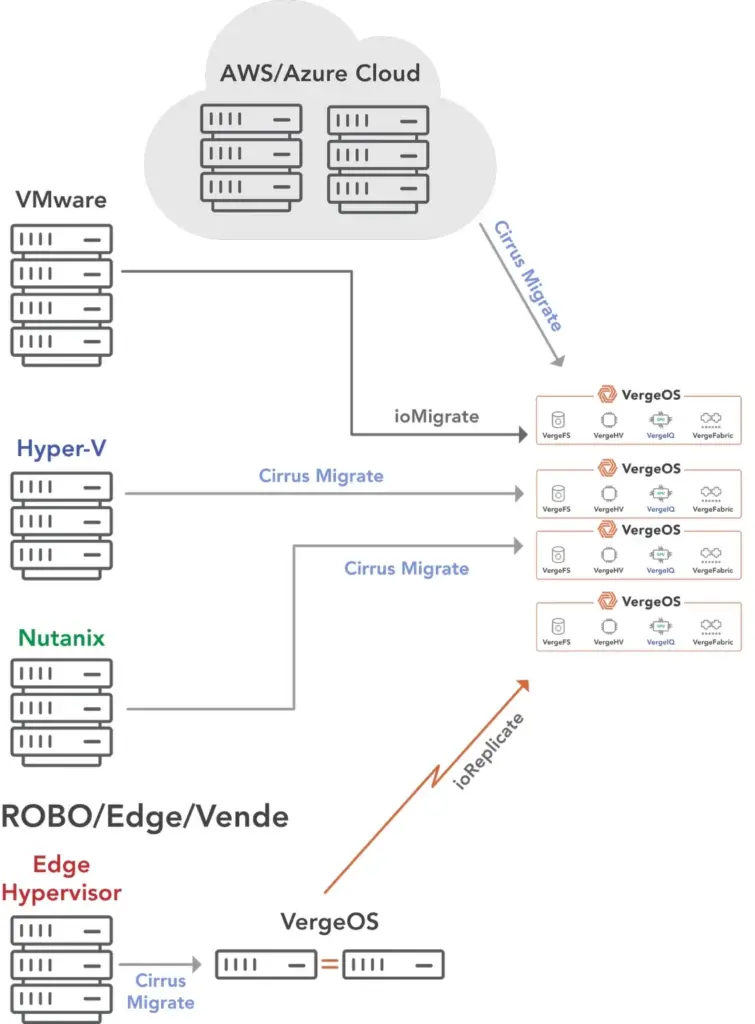
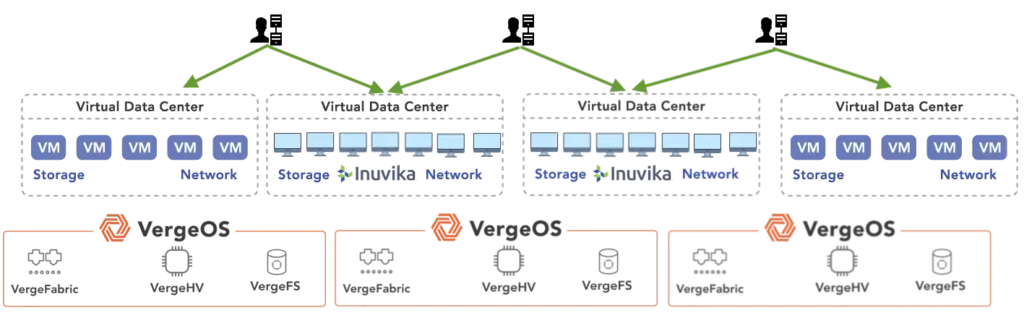
Universities are migrating from VMware to VergeOS because it was designed around the constraints most institutions face: limited budgets and small teams. The platform unifies virtualization, storage, networking, data protection, and AI into a single software codebase. This means one interface for all infrastructure management, not separate consoles for compute, storage arrays, network switches, and backup tools. A two or three-person IT team can manage the entire stack without specialized training in storage protocols or network fabric configuration.
The hardware-agnostic architecture separates VergeOS from alternatives that require certified hardware. VergeOS runs on commodity x86 servers from any vendor. Universities can repurpose HPE Gen9 through Gen11 servers, Dell PowerEdge systems, or white box hardware without concern for compatibility matrices or certified hardware lists. This eliminates the forced refresh cycle that turns a software decision into a six-figure capital expense. Institutions keep using servers with remaining useful life and redirect the budget to academic priorities.
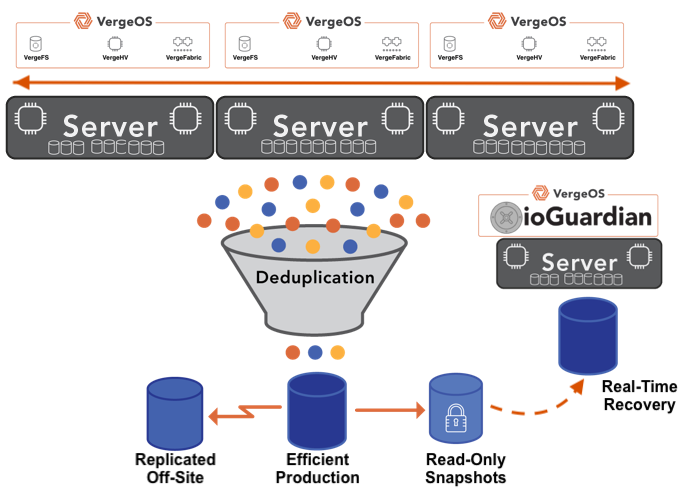
Universities are also leaving VMware due to the high cost and complexity of its availability and data resiliency features. Conversely, high availability, replication, and disaster recovery are built into the core platform of VergeOS, not add-on products with separate licensing. Institutions can replicate between campus data centers or create DR sites using repurposed older hardware. Universities have similar DR requirements to K-12 Education.
VergeOS’ ransomware protection includes immutable snapshots and rapid recovery without needing a separate backup infrastructure. The platform handles these functions natively, reducing complexity and eliminating integration points where problems typically occur.
For student involvement, VergeOS provides an accessible environment where IT and computer science students can gain hands-on experience with enterprise infrastructure. The interface is easily learnable without months of training, and the unified architecture lets students see how compute, storage, and networking interact rather than treating them as isolated domains.
The Pfeiffer University Exit Strategy
Pfeiffer University in North Carolina provides a blueprint for doing this well. When CIO Ryan Conte faced VMware’s new pricing and a push for expensive hardware refreshes, he took a methodical approach. Conte evaluated public cloud providers like Azure and AWS, reduced-scope VMware deployments, and alternative on-premises platforms. Each option presented fundamental dealbreakers that made it unsuitable for Pfeiffer’s needs. Cloud providers required hiring consultants or extensive training, duplicated costs for infrastructure already owned on campus, and raised data sovereignty concerns. Scaling down VMware meant eliminating redundancy and accepting unacceptable downtime risks for critical academic systems. Traditional competitors like Nutanix demanded new hardware investments.
Pfeiffer ran a three-month proof-of-concept with VergeOS on its existing Dell and HPE servers. Three senior CIS students joined as IT assistants, making the project part of their capstone experience. The team stress-tested the platform, tried to break configurations, and learned what worked. They discovered critical lessons early, such as encrypting data at rest from the start and standardizing on 10GbE networking, and adjusted before the production migration.
Using VergeIO’s built-in migration tools, Pfeiffer moved 30 to 40 virtual machines without hiring consultants. Roughly 10% of VMs needed adjustments, all of which were resolved quickly with VergeIO support. The results speak directly to the financial pressure universities face. Pfeiffer achieved an 85% cost reduction compared to VMware, avoiding $185,575 in annual expenses. The university purchased zero new hardware and repurposed existing servers. Integrated backup and disaster recovery eliminated a separate $20,000 to $30,000 backup project. Three graduates entered IT careers with real infrastructure experience on their resumes.
“VergeIO was the only company I looked at whose product didn’t need new hardware,” Conte explained. “Others told me to buy new, but I had good servers with life left. VergeOS let me use them.”
Read the detailed Pfeiffer University Case Study here.
Universities are leaving VMware to Reuse Servers

One of the most overlooked benefits of a successful VMware exit is the cost savings from hardware economics. Most universities own capable servers that have years of useful life remaining. HPE Gen9, Gen10, Gen11, and Dell PowerEdge systems deliver strong performance if the software layer is efficient. By choosing a hardware-agnostic platform, universities eliminate capital expenses that would otherwise consume annual budgets, and instead support sustainability initiatives by reducing e-waste. Refresh cycles extend to 6 or 7 years, rather than 3 or 4. Older servers find new purpose in disaster recovery or lab environments.
At Pfeiffer, Conte repurposed older Dell servers into a DR cluster, adding NVMe via PCIe cards and SSDs for just a few hundred dollars. This level of flexibility is impossible with vendor-locked ecosystems.
Universities are leaving VMware for AI Readiness

Universities are leaving VMware because of the complexity of providing AI services to staff and students. Research analytics, adaptive learning platforms, and student-facing AI tools all require flexible, compute-ready infrastructure. Legacy virtualization platforms were not designed for these workloads. Unified infrastructure platforms like VergeOS allow dynamic GPU allocation across mixed workloads. Universities can run AI experiments on campus without cloud lock-in. Student lab environments gain access to machine learning tools. By consolidating infrastructure today, universities build the foundation for tomorrow’s intelligent campus.
A Practical Exit Roadmap
Successful VMware exits at institutions like Pfeiffer shared several characteristics. The process started with a thorough hardware inventory, workload dependency mapping, and cost baseline documentation. These institutions identified which servers had remaining useful life and which were genuinely ready for retirement. Clear goals for cost-reduction targets, uptime requirements, feature-parity needs, and timeline constraints guided the evaluation. The proof-of-concept phase tested alternative platforms on real hardware with actual workloads, not vendor demos. IT staff and students participated in the evaluation process.
Migration planning at successful institutions prioritize workloads by risk and criticality. Non-critical systems move first, providing learning opportunities before tackling production workloads. The best implementations turned technical projects into educational opportunities where students gained valuable experience and institutions built long-term internal knowledge. Documentation mattered at every stage. Runbooks, configuration guides, and lessons learned became institutional knowledge that outlasted any individual staff member.
The Path Forward
Universities are leaving VMware for reasons beyond cost avoidance. It is about reclaiming institutional control over infrastructure decisions, budgets, and operational flexibility. The two forces driving universities away from VMware — rising costs and premature hardware deprecation — are not temporary pressures. They represent a permanent shift in how VMware operates under Broadcom ownership.
Universities that successfully navigate this transition position themselves for sustainable, flexible IT operations that align with their educational mission. They avoid the trap of escalating subscription costs that consume budget meant for academic programs. They extend hardware lifecycles and redirect savings to student services. They build infrastructure ready for AI workloads and modern research demands.
VergeOS provides the platform to make this transition practical. Supporting existing hardware, unifying core infrastructure functions, and simplifying management give higher education IT teams the tools they need to modernize without breaking their budgets. The window for action narrows as license renewals approach. Institutions that act now avoid another cycle of rising costs and declining flexibility.