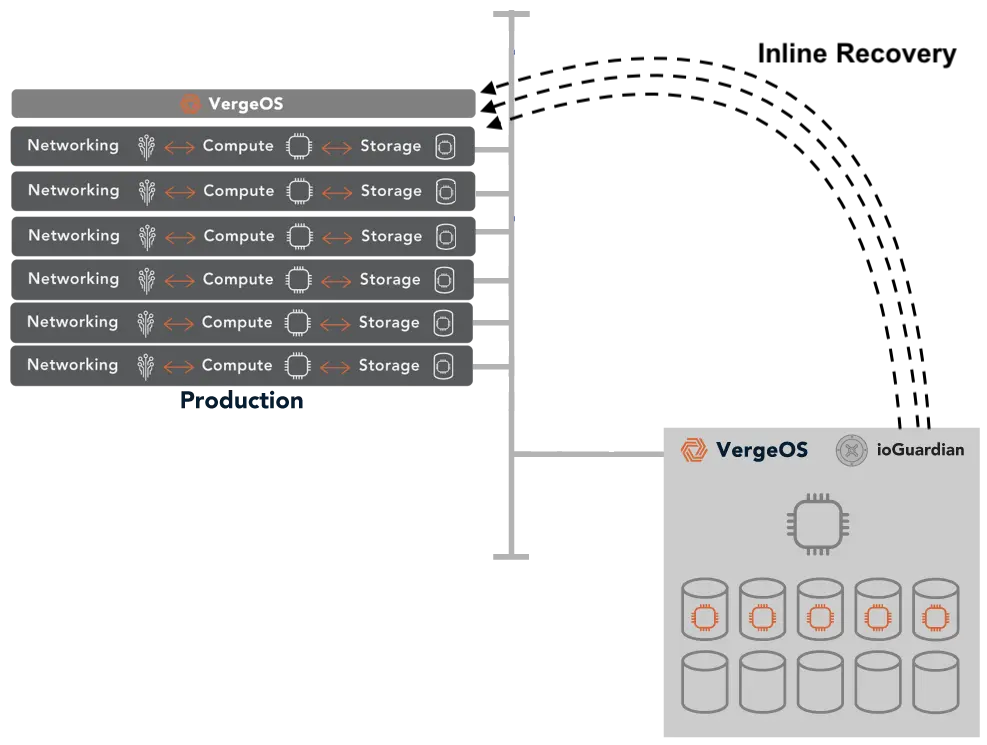
Midsize data center automation faces a critical paradox: small IT teams need it more than enterprises but struggle to sustain it. Teams managing a dozen or so servers face the same availability and response expectations as large enterprises, but with a fraction of the staff. A team of two or three spans virtualization, storage, networking, security, and data protection, making automation not just valuable but essential for survival.
Key Takeaways
Small IT teams need automation more than enterprises but struggle to sustain it due to infrastructure fragmentation. Teams of one or two manage all infrastructure disciplines with enterprise-level expectations but fraction of the staff. Automation ROI exceeds large organizations because each automated task multiplies individual capacity across multiple responsibilities, but separate systems for compute, storage, networking, and data protection each introduce their own APIs and lifecycle rules that force constant code maintenance.
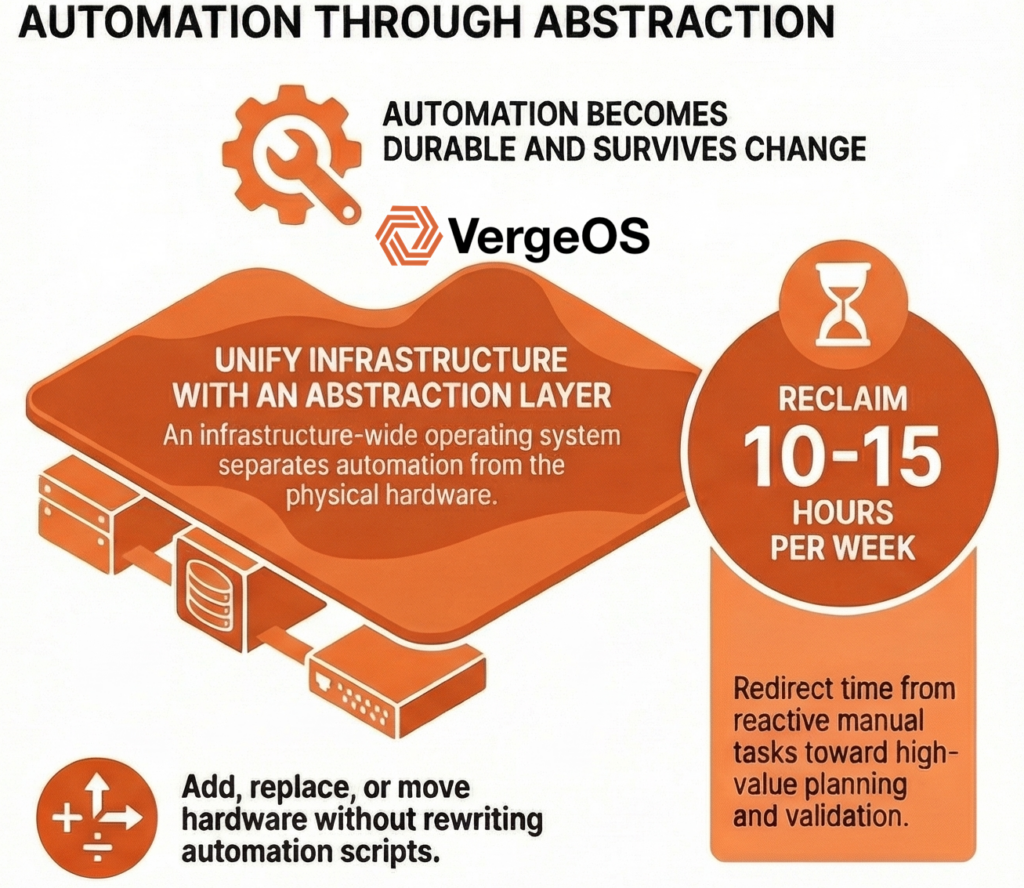
Unified infrastructure enables durable automation by collapsing infrastructure behavior into a single operating model. Automation interacts with consistent operational patterns rather than individual hardware platforms where servers, storage, and networking can be added, replaced, or moved without automation rewrites. Hardware lifecycle changes happen beneath the automation layer, making code survive decades instead of breaking every 3-5 year refresh cycle. Small teams reduce maintenance time from 15-20% to under 5% while gaining hardware flexibility across any commodity equipment.
VMware exit creates natural timing to establish automation foundation through unified infrastructure. Organizations already facing migration disruption can combine hypervisor replacement and infrastructure simplification in one transition rather than sequential projects requiring separate automation redesigns. Implementation succeeds through incremental approaches where automating the next infrastructure task by default builds patterns that compound over time, typically recovering 10-15 hours weekly for resource-constrained teams.
The automation ROI for midsize environments exceeds that of large enterprises because each spans more disciplines, where automation delivers greater operational value than in organizations with specialized teams. When one person manages everything, every automated task multiplies capacity in ways that specialized teams cannot appreciate.
Automation delivers critical operational benefits for resource-constrained teams:
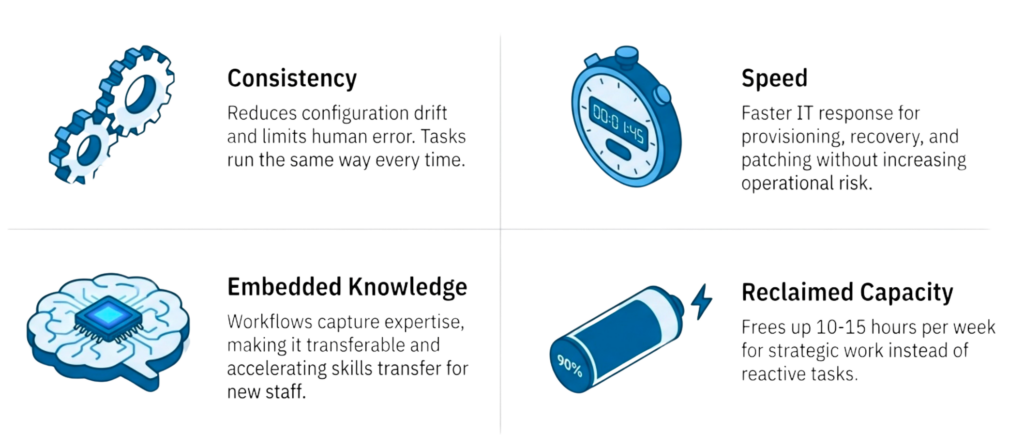
- Consistency reduces drift and limits human error across all infrastructure disciplines
- Faster IT response times without increased operational risk
- Knowledge embedded in workflows rather than residing in individuals
- Reclaimed capacity redirected from reactive work toward planning and validation
- Skills transfer accelerates as new staff follow established automation patterns
Consistency is the most immediate benefit, where tasks run the same way every time, reducing drift, shortening recovery, and limiting human error while improving IT responsiveness without increasing risk as provisioning, recovery, patching, and change execution happen faster through defined workflows instead of ad hoc steps.
Key Terms & Concepts
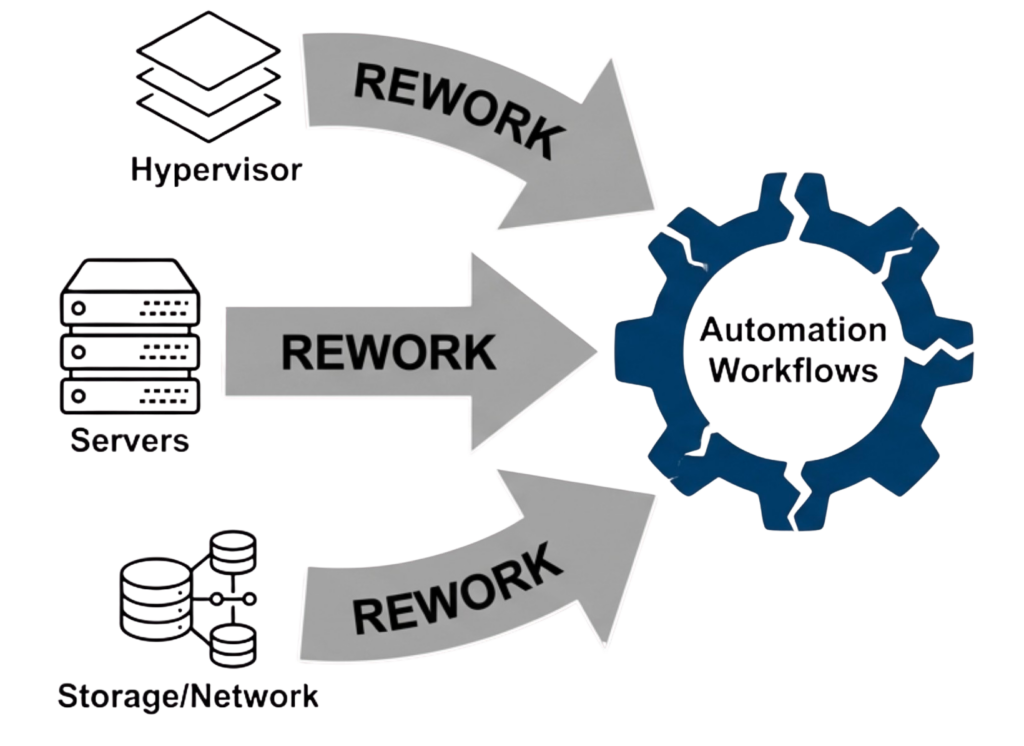
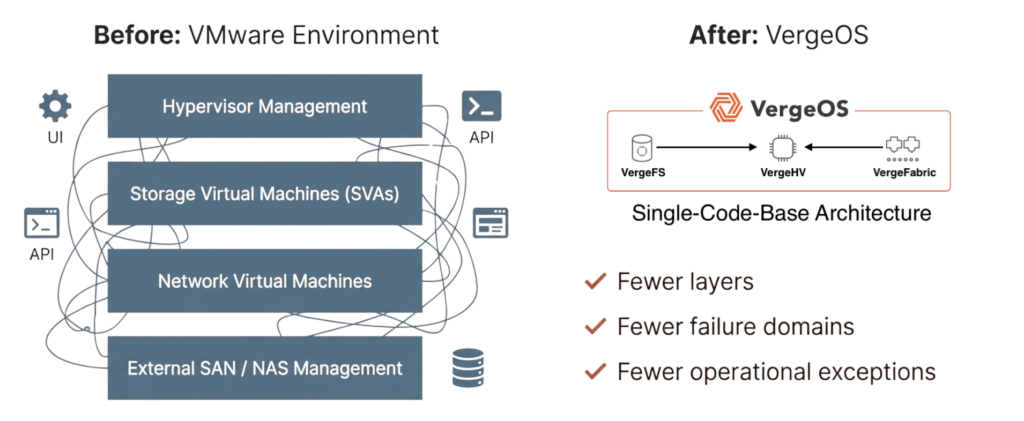
Infrastructure Fragmentation: The condition where separate systems for compute, storage, networking, and data protection each expose different APIs and lifecycle rules. Creates automation barriers because code complexity grows exponentially with each infrastructure layer, requiring constant rewrites when components change.
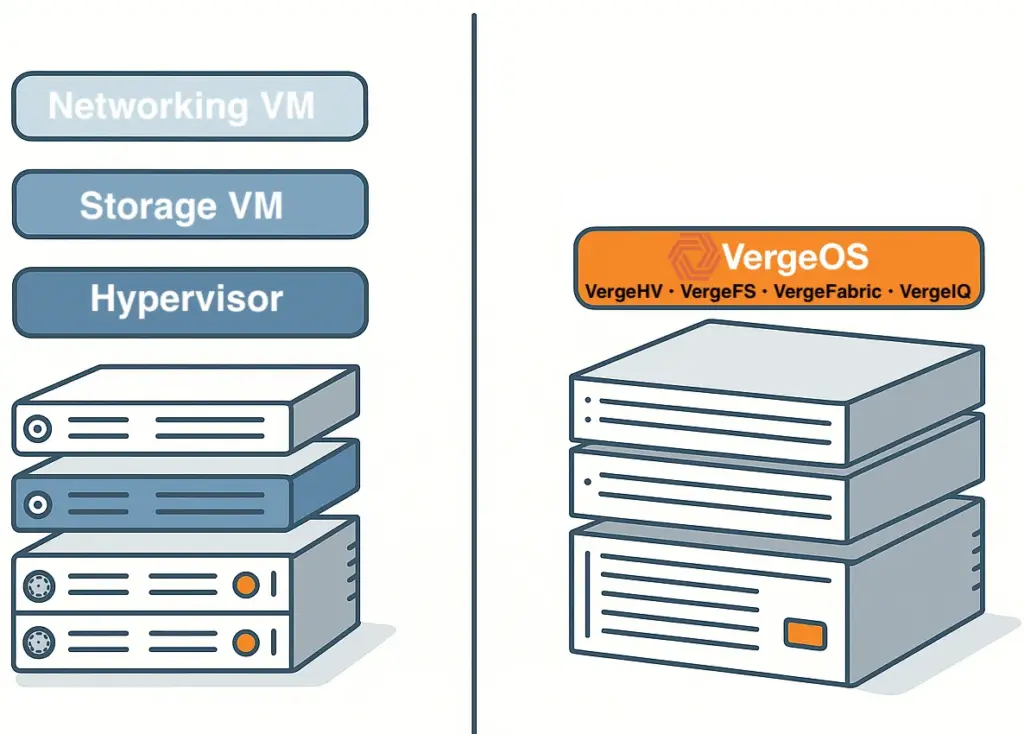
Unified Infrastructure Platform: An infrastructure-wide operating system integrating storage, compute, and networking into single operational model with one API. Enables automation to interact with consistent patterns rather than individual hardware platforms where components can be added, replaced, or moved without automation rewrites.
Infrastructure Operating System Abstraction: Architectural approach that moves infrastructure behavior into software layer rather than exposing hardware-specific details. Allows Terraform, Ansible, and Packer code to remain stable across hardware generations, eliminating the 3-5 year rewrite cycles that fragmented infrastructure forces.
Automation Durability: The ability of infrastructure-as-code to survive hardware refresh cycles and vendor changes without requiring rewrites. Achieved through platform abstraction that shields automation from hardware-specific details, enabling code to function identically across decades of infrastructure changes.
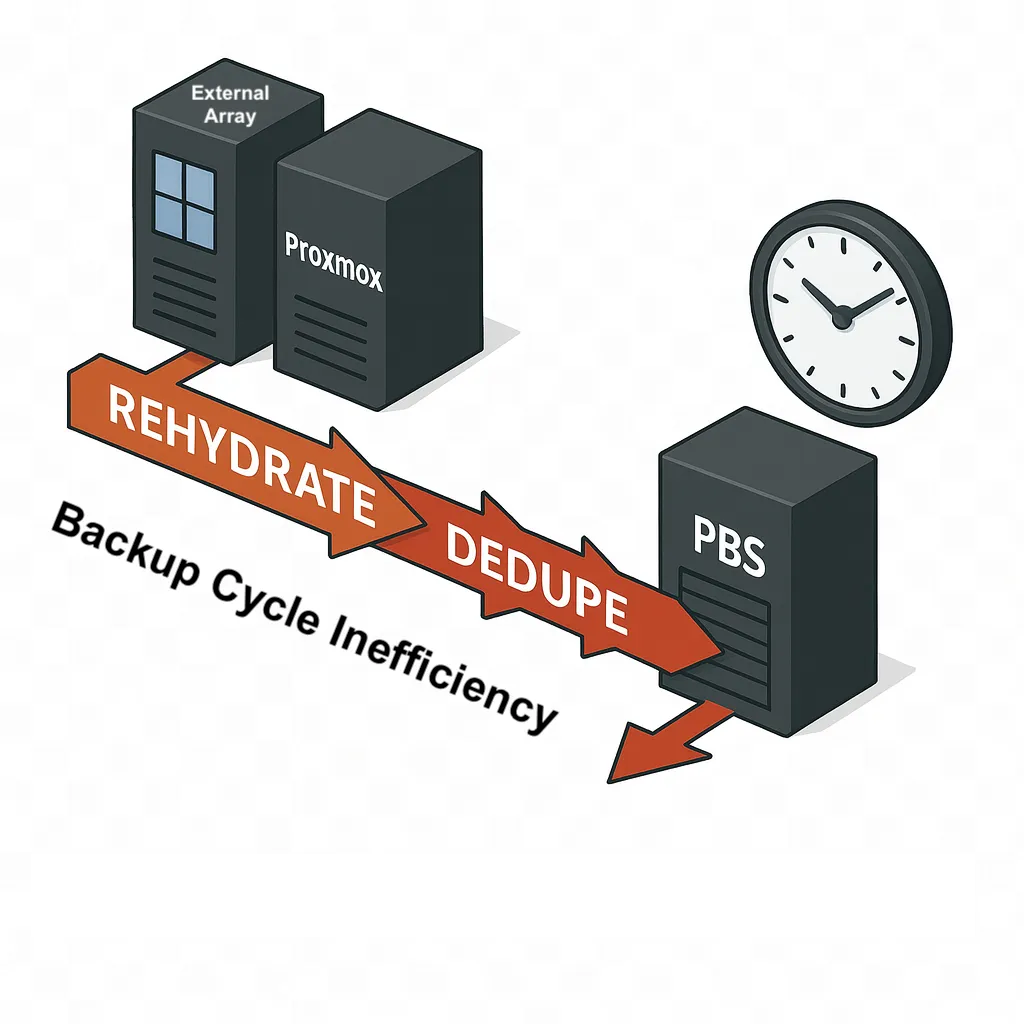
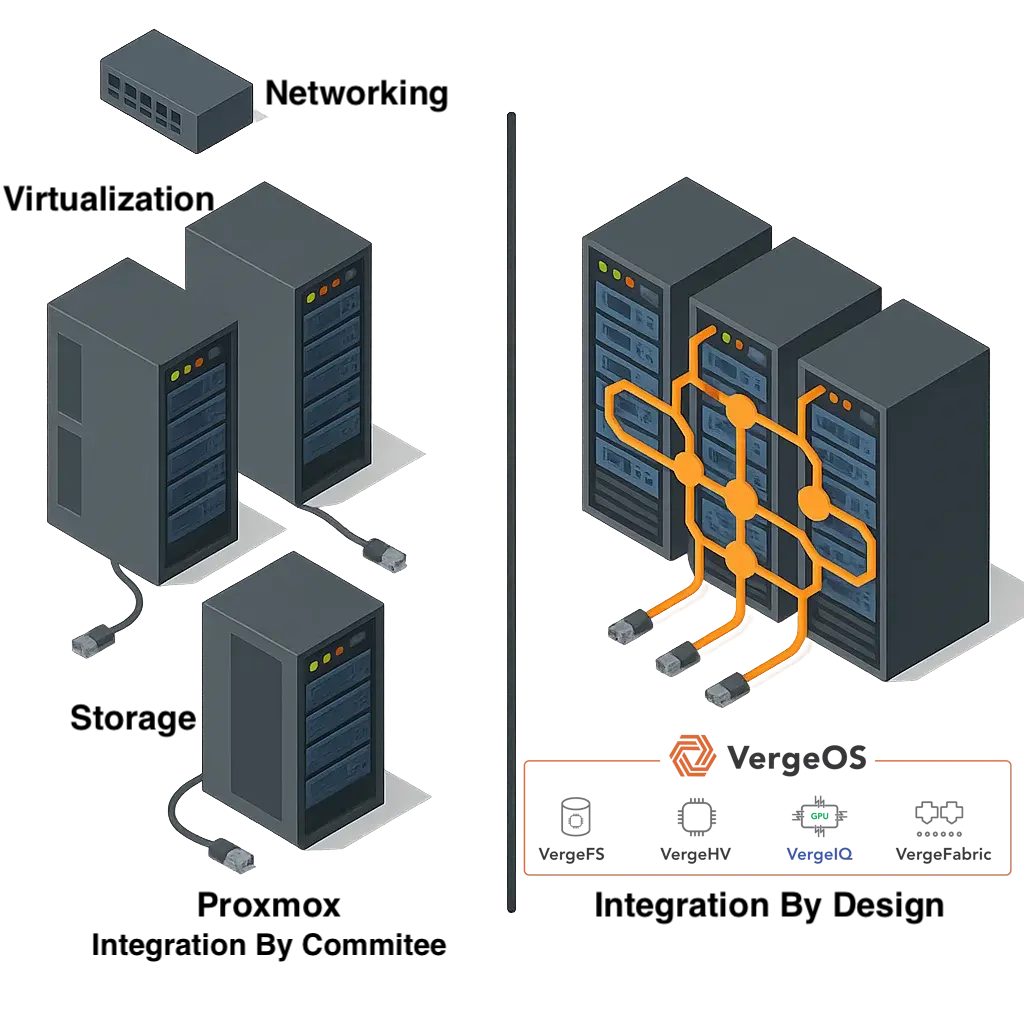
Why Infrastructure Fragmentation Blocks Automation for Small IT Teams
Automation is more accessible than many assume, as most automation tools are free or very low-cost. The real investment is time rather than licensing, and cost rarely blocks adoption. What blocks successful implementation is the inability to ensure that time spent building automation yields durable results due to infrastructure fragmentation.
The classic three tier architecture means that:
- Separate APIs for compute, storage, networking, and data protection layers
- Code complexity grows exponentially with each infrastructure layer
- Scripts require complete rewrites when infrastructure components change
- Integration maintenance becomes an operational burden rather than an automation benefit
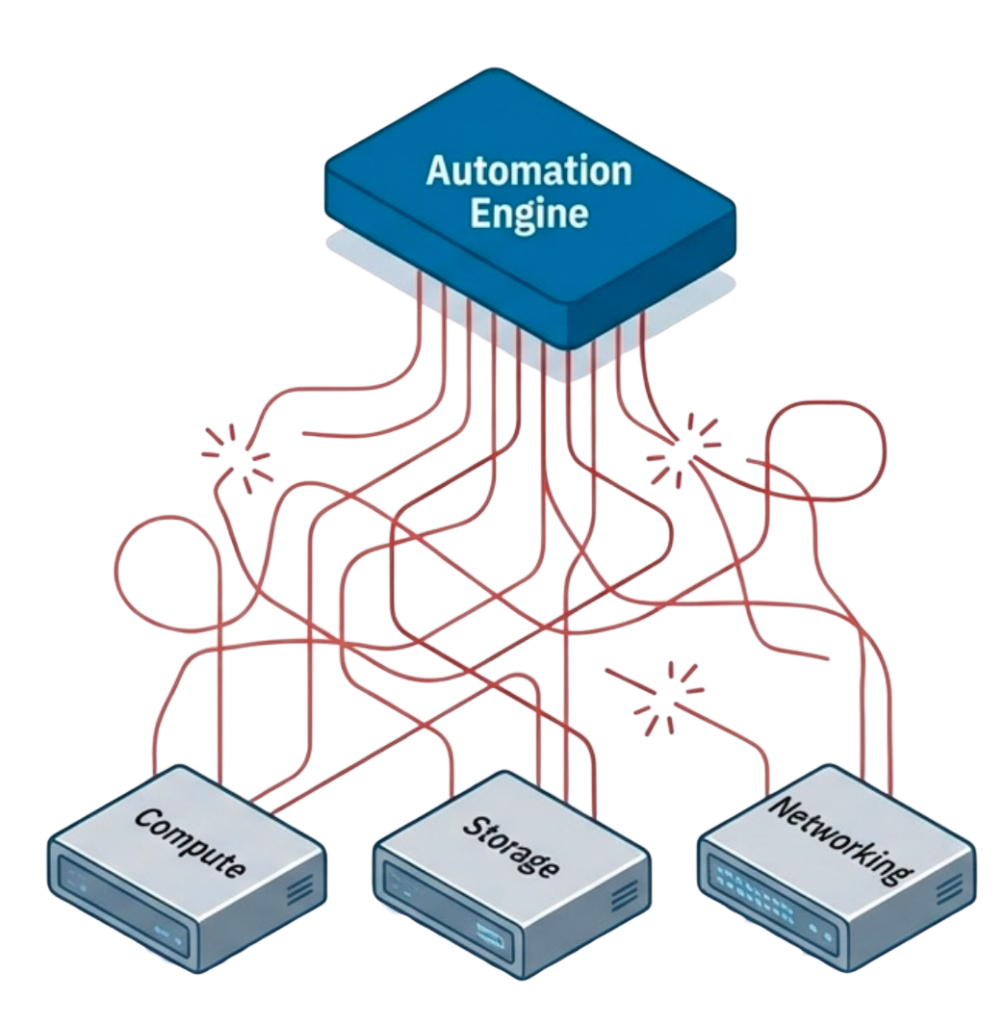
When automation requires assembling multiple tools, stitching together fragile integrations, and rewriting scripts every time infrastructure changes, teams abandon it. Not because automation is unnecessary, but because it becomes another operational burden, and unlike enterprises, small IT teams cannot justify dedicating personnel to developing and maintaining infrastructure automation code whenever something in the environment changes.
For automation to succeed and deliver value in resource-constrained environments, it must survive change. That requirement forces IT teams toward one of two practical paths, from which everything else about automation flows.
Two Paths to Sustainable Automation for Small Teams
Path One: Strict Hardware Standardization
This approach limits vendors and even specific system models, so automation only interacts with a narrow, predictable set of hardware behaviors. The appeal is immediate where reduced complexity comes from predictable hardware behavior, automation targets a narrow, well-understood hardware set, and fewer integration points require management and maintenance.
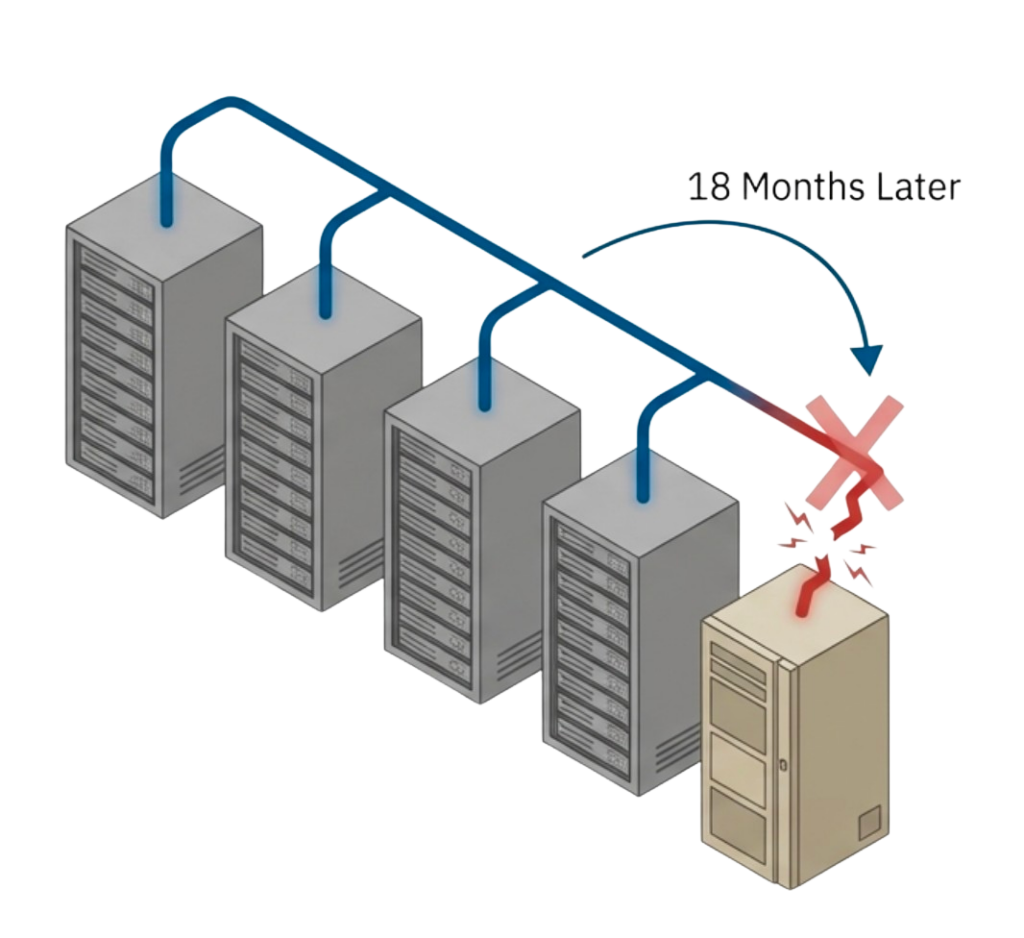
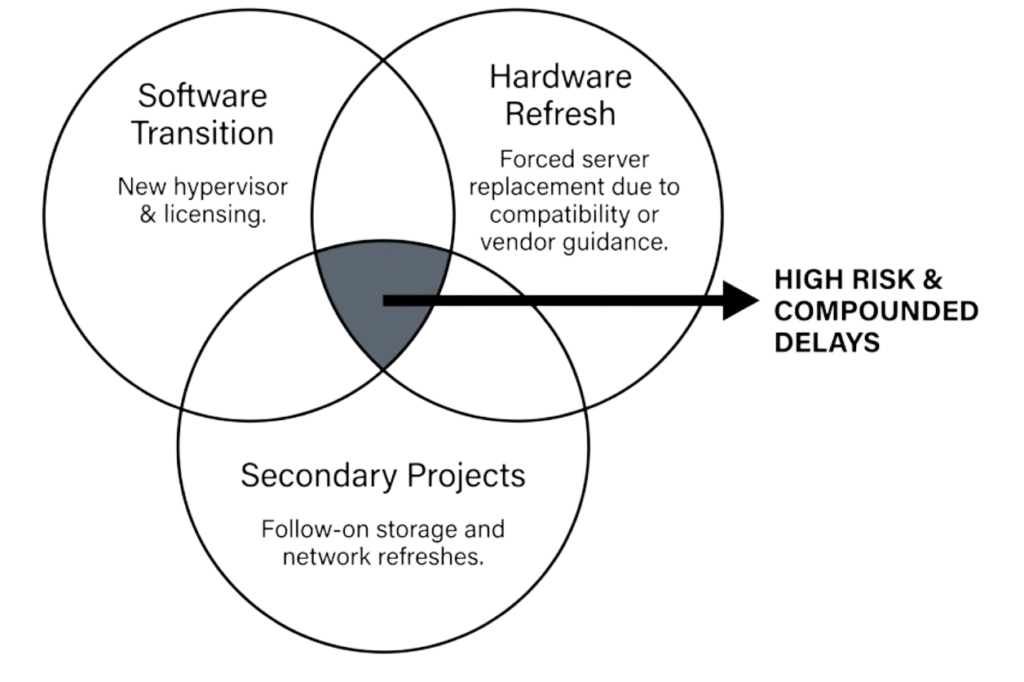
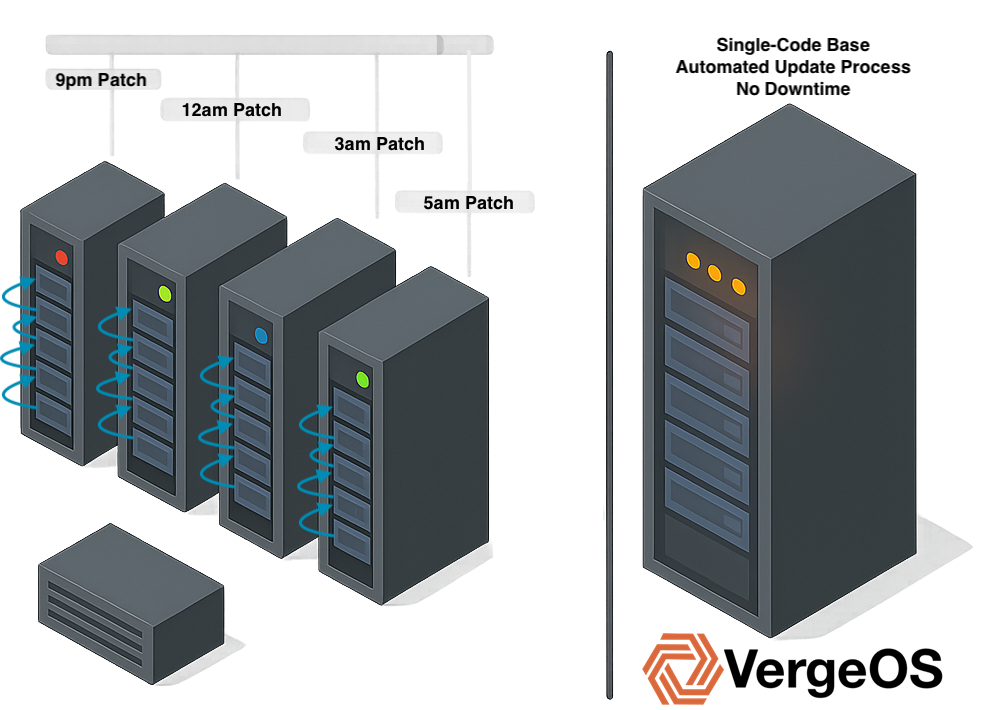
However, the disadvantages become apparent over time as vendors change product lines and discontinue models, while systems reach end-of-life and require replacement. Firmware behavior shifts between hardware generations, new capabilities from other vendors cannot be adopted, and rigid constraints block progress or force exceptions that break automation discipline.
Strict hardware standardization works initially, but as soon as a new infrastructure component is added or replaced, automation breaks. In practice, this approach is challenging to maintain because vendors evolve, systems retire, and business needs change faster than standardization policies can adapt.
Path Two: Infrastructure Abstraction
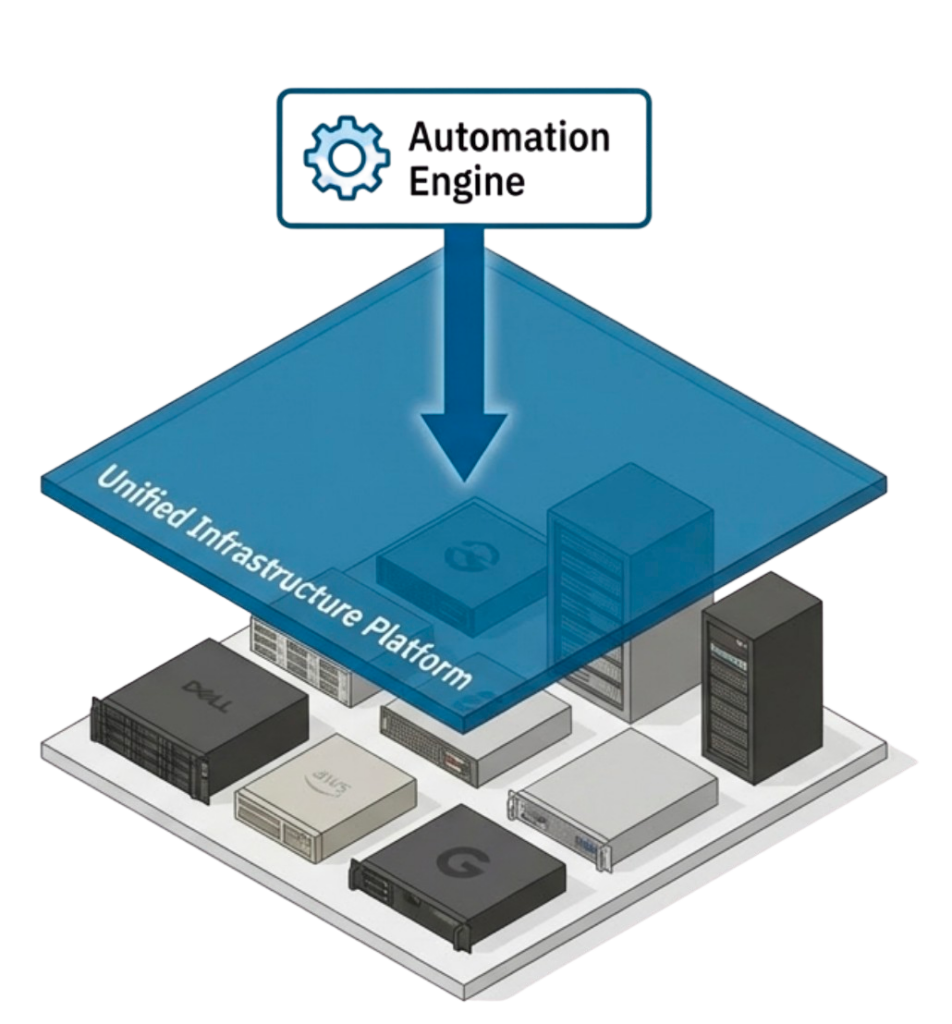
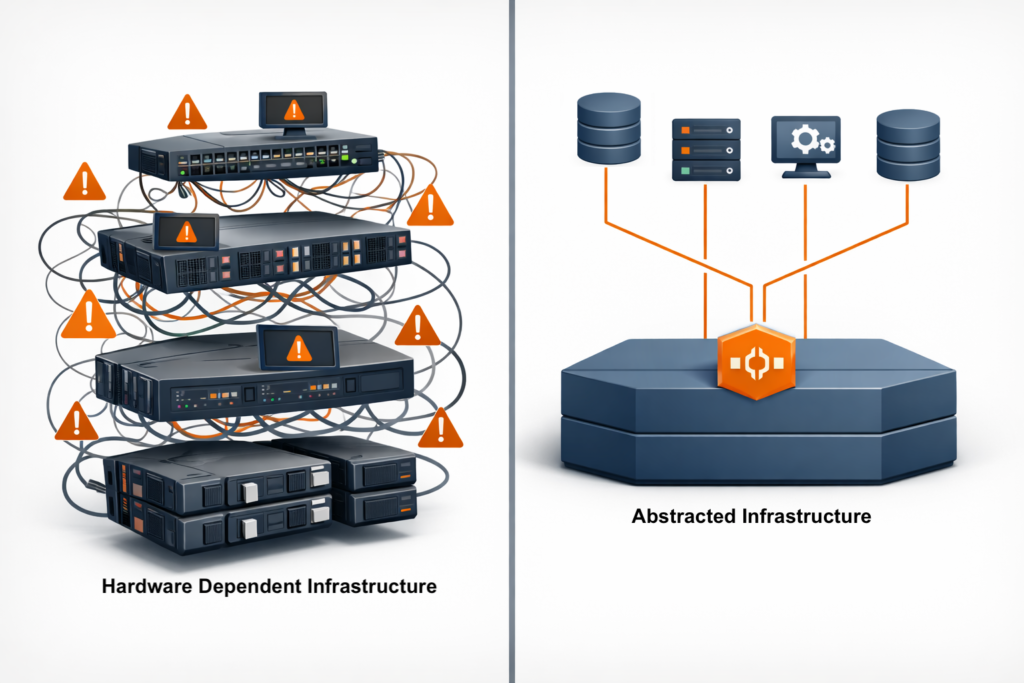
An infrastructure-wide operating system abstracts the control plane from hardware, moving infrastructure behavior into the software layer where automation interacts with a consistent operational model rather than individual hardware platforms. This approach allows servers, storage, and networking to be added, replaced, or moved without automation rewrites while hardware lifecycle changes happen beneath the automation and control layers. The consistent operational interface persists across infrastructure evolution, enabling teams to focus on business logic rather than hardware integration while automation remains stable for years across hardware generations.
The trade-off is straightforward: infrastructure abstraction requires adopting a new platform, which represents an architectural change, an initial migration from existing fragmented infrastructure, and a learning curve for the new operational model. For small IT teams, this path is the only one that holds up over time because fragmented infrastructure breaks automation regardless of initial standardization efforts. Hardware changes are inevitable, while platform abstraction makes those changes irrelevant to automation code.
How Infrastructure Abstraction Enables Automation
Automation becomes fragile when it depends on the details of individual components. Separate systems for compute, storage, networking, and data protection each bring their own interfaces, behaviors, and lifecycle rules, where every difference becomes something automation must account for. Over time, automation grows more complex than the operations it was meant to simplify.
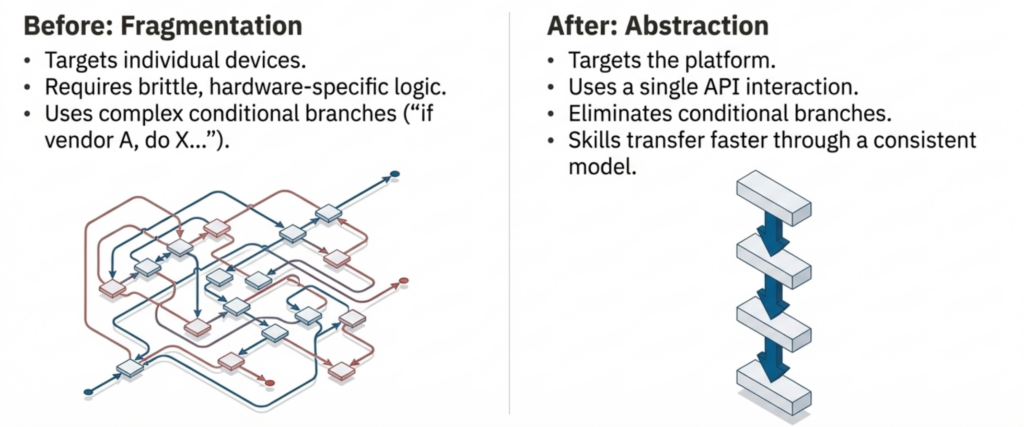
Unified infrastructure changes the dynamics by collapsing infrastructure behavior into a single operating system. Automation no longer targets individual devices or vendors; instead, it targets the platform, where provisioning, protection, recovery, and lifecycle operations follow the same patterns regardless of underlying hardware. This reduces code volume through a single API interaction, limited integration points that eliminate entire failure classes, and eliminates conditional branches, replacing brittle hardware-specific logic. Hardware changes become transparent to automation workflows while skills transfer faster through a consistent operational model.
The Automation Benefits for Small IT

For small IT teams, this consistency matters more than feature depth because it reduces the amount of code required, limits the number of integration points, and removes entire classes of failure. Automation becomes predictable instead of brittle.
This approach also aligns with how hardware actually changes in smaller environments where servers are added incrementally, storage is refreshed on different cycles, and networking evolves. With unified infrastructure, those changes happen beneath the automation layer, where existing workflows continue to run because the operational interface stays the same.
Organizations seeking to build end-to-end automation chains find that unified platforms eliminate the integration complexity that prevents resource-constrained teams from sustaining automation in the long term. In practice, unified infrastructure is the only way for midsize data centers to realize the full benefits of automation because the time required to build, test, and maintain automation across fragmented systems becomes impractical for limited staff. Automation either stalls or is abandoned because the maintenance burden exceeds the time savings. Unified infrastructure removes that barrier and makes automation sustainable rather than aspirational.
| Aspect | Fragmented Infrastructure | Unified Infrastructure |
|---|---|---|
| Maintenance Burden | Rewrites every 3-5 years per hardware refresh | Minimal. Code survives hardware changes |
| Small Team Time | 15-20% maintaining compatibility | <5% maintenance time |
| Hardware Flexibility | Locked into specific vendors/models | Any commodity hardware works |
| Multi-Site Automation | Separate code per location | Same code everywhere |
| Skills Transfer | 3-6 months learning curve | 2-4 weeks to productivity |
| 5-Year ROI | Maintenance exceeds savings | Positive ROI compounds within weeks |
Implementation Strategy for Small IT Team Automation

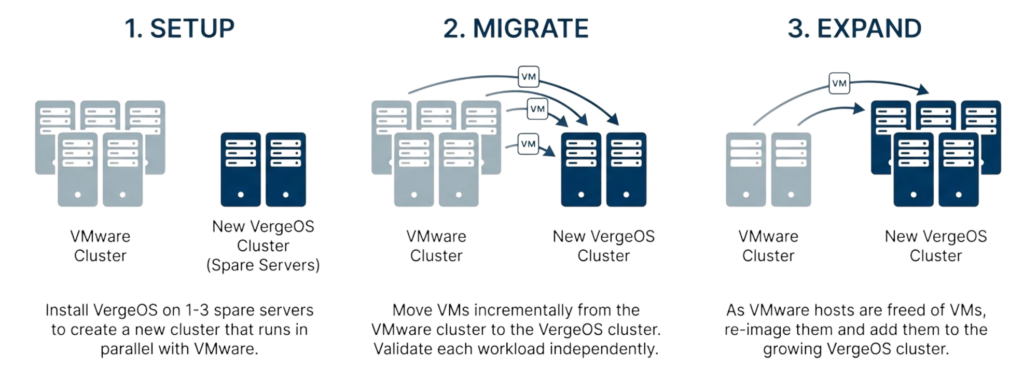
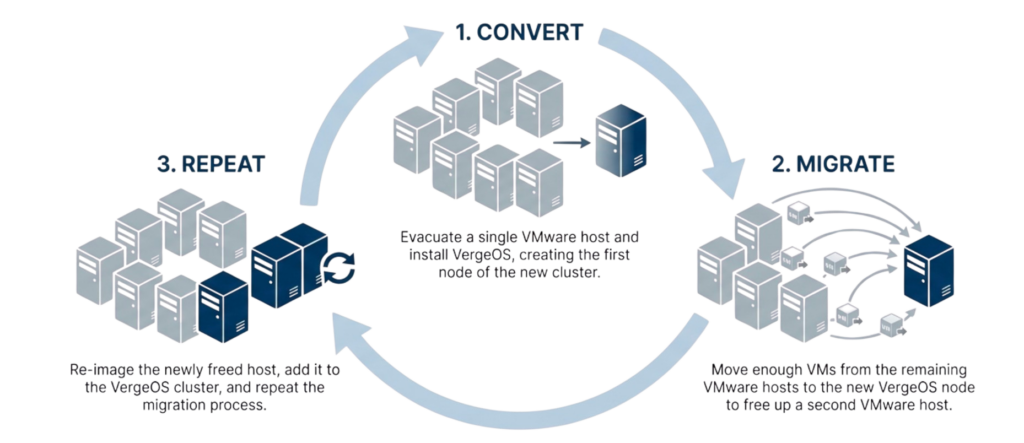
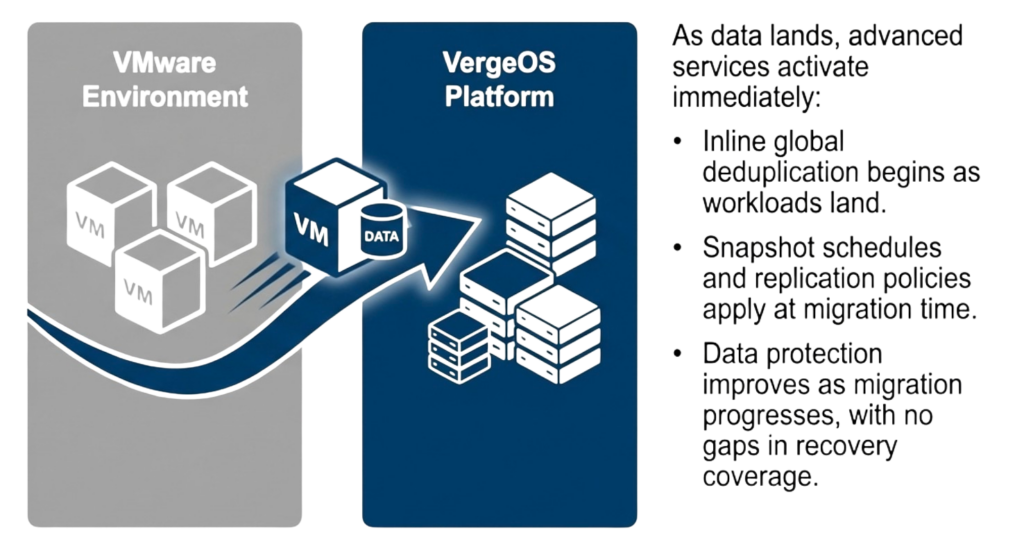
The VMware exit presents an excellent opportunity to reevaluate infrastructure architecture, as organizations already face disruption and change. That first step may focus on exiting VMware licensing costs, but choosing unified infrastructure lays the foundation for future hardware flexibility, durable automation routines, and significantly reduced operational costs. The migration window creates natural alignment between hypervisor replacement and infrastructure simplification, enabling both to occur in a single transition rather than as sequential projects.
Starting automation in people-constrained environments requires practical approaches that deliver value incrementally rather than demanding large upfront projects. The most effective strategy is to automate the next infrastructure task by default, regardless of whether you expect to perform it once or repeatedly, shifting automation from a future initiative to a present habit while building familiarity with tools through immediate operational context.
Do What’s Next
Starting with the next workflow rather than the highest-impact builds confidence. It creates reusable patterns that compound over time, where each automated task reduces future manual effort and accelerates subsequent automation. Capturing automation in version control transforms it into organizational knowledge rather than individual expertise, enabling new team members to follow established patterns and become productive faster without mastering every manual process.

Automation improves through regular practice rather than theoretical planning, where each automated task reinforces understanding and turns automation into an operational habit rather than a special project. Modern AI tools accelerate this process by generating initial Terraform modules, Ansible roles, and Packer templates quickly. At the same time, teams refine these drafts through review and testing, accelerating adoption without sacrificing quality.
For resource-constrained teams, incremental automation on a unified infrastructure delivers sustainable results, whereas large automation projects on fragmented infrastructure often fail.
Real-World Impact: Small Team Automation ROI
Organizations with limited IT staff report measurable automation benefits when infrastructure supports rather than resists automation efforts. Teams typically recover 10-15 hours weekly through automated provisioning, patching, and recovery workflows, which redirect that reclaimed time toward planning, validation, and capability improvement rather than repetitive manual tasks.
Configuration drift elimination through automated enforcement prevents systems from diverging over time, while troubleshooting accelerates because systems behave predictably across production, test, and recovery environments. New team members become productive in weeks rather than months by following established automation patterns that embed operational knowledge in code rather than leaving it solely in individuals, reducing key-person dependency.
Infrastructure provisioning drops from hours to minutes through automated workflows while emergency response follows tested procedures rather than improvisation, reducing errors during high-pressure situations. The automation ROI calculation for midsize environments differs from enterprises because each automated task multiplies individual capacity rather than incrementally improving specialized team efficiency. When one person manages everything, automation becomes a force multiplier rather than a marginal improvement.
Conclusion: Making Small IT Team Automation Sustainable
Automation is not something midsize data centers adopt after reaching scale, but is required early to operate with limited staff and high response expectations. It is also what enables them to achieve scale. Manual processes leave no margin for error, while automating a fragmented architecture quickly consumes more time than it saves.
Unified infrastructure platforms make automation practical for small IT teams by abstracting the infrastructure control plane from hardware into software. Automation becomes durable, skills transfer faster, and operations remain consistent despite hardware changes.
The choice is not whether to automate, but whether to automate on infrastructure that supports or resists automation efforts. Resource-constrained teams cannot afford the ongoing maintenance burden that fragmented infrastructure imposes on automation frameworks. For small IT teams, automation is not an enterprise privilege but an operational requirement. Unified infrastructure makes that requirement achievable rather than aspirational.
Ready to explore midsize data center automation? Schedule a consultation with our automation experts to discuss how unified infrastructure eliminates fragmentation barriers and makes sustainable automation achievable for resource-constrained teams.
Frequently Asked Questions
Why is automation more important for midsize data centers than large enterprises?
Small IT teams managing midsize data centers face the same availability and response expectations as large enterprises but with a fraction of the staff. A team of one or two spans virtualization, storage, networking, security, and data protection where every automated task multiplies individual capacity across multiple disciplines. Automation ROI exceeds enterprise implementations because each automated workflow reclaims hours that would otherwise consume the entire team’s capacity, often determining whether teams stay ahead of operations or remain stuck reacting to them.
What prevents small teams from sustaining automation long-term?
Infrastructure fragmentation is the primary barrier where separate systems for compute, storage, networking, and data protection each introduce their own APIs, behaviors, and lifecycle rules. Code complexity grows exponentially with each infrastructure layer while scripts require complete rewrites when components change. Unlike enterprises, midsize data centers cannot justify dedicating personnel to maintain infrastructure automation code every time something in the environment changes, causing automation efforts to be abandoned when maintenance burden exceeds time savings.
Does standardizing on one vendor eliminate automation maintenance problems?
No. Vendors operate product lines as independent platforms with incompatible APIs where refreshing from one storage array model to another within the same vendor requires nearly as extensive automation rewrites as switching vendors entirely. Hardware standardization reduces initial complexity but breaks when vendors change product lines, systems reach end-of-life, or business needs require different capabilities. In practice, strict hardware standardization is difficult to maintain because vendors evolve, systems retire, and infrastructure needs change faster than standardization policies can adapt.
How does unified infrastructure make automation sustainable for small teams?
Unified infrastructure abstracts the control plane from hardware by integrating storage, compute, and networking into a single operating system with one API. Automation interacts with consistent operational models rather than individual hardware platforms where servers, storage, and networking can be added, replaced, or moved without automation rewrites. Hardware lifecycle changes happen beneath the automation layer, reducing maintenance time from 15-20% to under 5% of team capacity while enabling any commodity hardware to work without code changes.
Why is VMware exit a good time to establish automation foundation?
Organizations already face disruption and change during VMware migration where the window creates natural alignment between hypervisor replacement and infrastructure simplification. Traditional approaches treat these as sequential projects requiring two separate automation redesigns over 3-5 years. Choosing unified infrastructure during VMware exit combines both transitions into one project, laying foundation for future hardware flexibility, durable automation routines, and significantly reduced operational costs while avoiding duplicate disruption.
How should small teams start automation without overwhelming limited resources?
The most effective strategy is automating the next infrastructure task by default regardless of whether you expect to perform it once or repeatedly. Starting with the easiest workflow rather than highest impact builds confidence while creating reusable patterns that compound over time. Capturing automation in version control transforms it into organizational knowledge rather than individual expertise, enabling new team members to become productive in weeks rather than months. Modern AI tools accelerate adoption by generating initial Terraform modules and Ansible roles that teams refine through review and testing.
What ROI can small teams expect from sustainable automation?
Organizations with limited IT staff typically recover 10-15 hours weekly through automated provisioning, patching, and recovery workflows where that reclaimed time redirects toward planning, validation, and capability improvement. Configuration drift elimination through automated enforcement prevents systems from diverging over time while troubleshooting accelerates because systems behave predictably. Infrastructure provisioning drops from hours to minutes through automated workflows while emergency response follows tested procedures rather than improvisation, reducing errors during high-pressure situations.
Can existing automation transfer to unified infrastructure or does it require starting over?
Migration requires rewriting automation because the architectural model changes from managing separate storage arrays, network switches, and hypervisors to referencing integrated infrastructure services. However, this is a one-time rewrite that eliminates future refresh-driven maintenance entirely. The code simplifies because it no longer needs vendor detection logic, firmware version checks, or generation-specific conditionals. The automation investment becomes durable across decades of hardware refresh rather than requiring updates every 3-5 years when infrastructure components change.
Small IT teams managing midsize data centers face the same availability and response expectations as large enterprises but with a fraction of the staff. A team of one or two spans virtualization, storage, networking, security, and data protection where every automated task multiplies individual capacity across multiple disciplines. Automation ROI exceeds enterprise implementations because each automated workflow reclaims hours that would otherwise consume the entire team’s capacity, often determining whether teams stay ahead of operations or remain stuck reacting to them.
Infrastructure fragmentation is the primary barrier where separate systems for compute, storage, networking, and data protection each introduce their own APIs, behaviors, and lifecycle rules. Code complexity grows exponentially with each infrastructure layer, while scripts require complete rewrites when components change. Unlike enterprises, midsize data centers cannot justify dedicating personnel to maintain infrastructure automation code whenever something in the environment changes, leading to automation efforts being abandoned when the maintenance burden exceeds the time savings.
No. Vendors operate product lines as independent platforms with incompatible APIs where refreshing from one storage array model to another within the same vendor requires nearly as extensive automation rewrites as switching vendors entirely. Hardware standardization reduces initial complexity but breaks when vendors change product lines, systems reach end-of-life, or business needs require different capabilities. In practice, strict hardware standardization is difficult to maintain because vendors evolve, systems retire, and infrastructure needs change faster than standardization policies can adapt.
Unified infrastructure abstracts the control plane from hardware by integrating storage, compute, and networking into a single operating system with one API. Automation interacts with consistent operational models rather than individual hardware platforms where servers, storage, and networking can be added, replaced, or moved without automation rewrites. Hardware lifecycle changes happen beneath the automation layer, reducing maintenance time from 15-20% to under 5% of team capacity while enabling any commodity hardware to work without code changes.
Organizations already face disruption and change during VMware migration where the window creates natural alignment between hypervisor replacement and infrastructure simplification. Traditional approaches treat these as sequential projects requiring two separate automation redesigns over 3-5 years. Choosing unified infrastructure during VMware exit combines both transitions into one project, laying foundation for future hardware flexibility, durable automation routines, and significantly reduced operational costs while avoiding duplicate disruption.
The most effective strategy is automating the next infrastructure task by default regardless of whether you expect to perform it once or repeatedly. Starting with the easiest workflow rather than highest impact builds confidence while creating reusable patterns that compound over time. Capturing automation in version control transforms it into organizational knowledge rather than individual expertise, enabling new team members to become productive in weeks rather than months. Modern AI tools accelerate adoption by generating initial Terraform modules and Ansible roles that teams refine through review and testing.
Organizations with limited IT staff typically recover 10-15 hours weekly through automated provisioning, patching, and recovery workflows where that reclaimed time redirects toward planning, validation, and capability improvement. Configuration drift elimination through automated enforcement prevents systems from diverging over time while troubleshooting accelerates because systems behave predictably. Infrastructure provisioning drops from hours to minutes through automated workflows while emergency response follows tested procedures rather than improvisation, reducing errors during high-pressure situations.
Migration requires rewriting automation because the architectural model changes from managing separate storage arrays, network switches, and hypervisors to referencing integrated infrastructure services. However, this is a one-time rewrite that eliminates future refresh-driven maintenance entirely. The code simplifies because it no longer needs vendor detection logic, firmware version checks, or generation-specific conditionals. The automation investment becomes durable across decades of hardware refresh rather than requiring updates every 3-5 years when infrastructure components change.