GPU infrastructure without the complexity is what VergeOS delivers for engineering teams running simulations, data scientists prototyping models, and design teams that need workstation-class rendering from centralized infrastructure. These are visual compute and AI development workloads, and they share a common problem: the expertise required to deploy and manage GPU infrastructure sits outside the skill set of most IT teams. VergeOS was built to deliver GPU infrastructure without the complexity that stops these projects before they start.
Key Takeaways
- The VMware alternative market is growing rapidly: Most new entrants are existing products that bolted on KVM hypervisors to chase a market condition, not vendors building long-term platform strategies.
- Vendor commitment matters more than features: Infrastructure decisions last a decade. Vendors capitalizing on a temporary opportunity will not invest in their platforms the same way dedicated vendors will.
- Support capabilities vary dramatically: Unified codebases enable faster issue resolution. Vendors new to KVM depend on open-source community guidance when hypervisor-level problems arise.
- Hardware independence extends infrastructure life: True alternatives run on commodity servers from any manufacturer, mix generations in the same cluster, and keep hardware in production until it fails rather than until a compatibility list expires.
- Efficiency determines real-world performance: Stacked architectures consume resources before workloads get any. Platforms built as single operating systems eliminate overhead and return capacity to production.
- RAM optimization is often overlooked: Per-guest storage caching fragments memory across VMs. Infrastructure-level caching through deduplicated storage pools eliminates this waste.
- Scope separates hypervisor swaps from platform modernization: A hypervisor swap addresses licensing. An integrated platform replaces storage arrays, backup software, replication tools, and networking products that cost 5X more than the hypervisor.
- VergeOS predates the VMware disruption: Founded in 2012 to serve cloud service providers, the architecture existed long before Broadcom created the market opportunity. DCIG named VergeOS a TOP 5 VMware Alternative for both SME and SLED markets.
The operational barriers that make GPU infrastructure difficult are specific: driver compatibility across hypervisor versions, Multi-Instance GPU configuration via command line, and troubleshooting that demands knowledge beyond the typical sysadmin skill set. Organizations either hire dedicated GPU specialists, engage expensive consultants, or avoid GPU workloads altogether. VergeOS changes that equation. Our partnership with NVIDIA brings vGPU capabilities into the same unified management interface that IT teams already use for compute, storage, and networking. No separate tools. No specialized training. No operational friction.
Key Terms
- Visual Compute Infrastructure
- GPU-accelerated computing deployed to support engineering simulation, scientific visualization, design rendering, and AI development workloads — typically on-premises to keep proprietary data inside the organization’s security boundary.
- NVIDIA vGPU
- A software layer that enables multiple virtual machines to share a single physical GPU, with each VM receiving dedicated memory and its own full NVIDIA driver stack. Requires a software license from an NVIDIA-authorized partner.
- MIG (Multi-Instance GPU)
- Hardware-level GPU partitioning available on NVIDIA Ampere and Blackwell architecture GPUs. Divides a single GPU into isolated instances with dedicated compute engines, memory, and bandwidth — enforced in silicon, not software.
- VergeOS
- The private cloud operating system from VergeIO that unifies compute, storage, networking, and GPU infrastructure management in a single platform. IT teams manage all resources — including GPUs — through one interface.
- NVIDIA Supported vGPU Platform
- A designation indicating that NVIDIA introduced the platform as a validated configuration for enterprise GPU virtualization. Supported platforms appear on NVIDIA’s compatibility matrix and receive joint support from both the platform vendor and NVIDIA engineering.
- GPU Passthrough
- A configuration that assigns an entire physical GPU exclusively to a single virtual machine. Delivers maximum performance for full-GPU simulation and scientific compute workloads — one VM per GPU, no sharing.
Many of these workloads involve proprietary data that cannot move to external services. Sensitive designs, regulated records, and competitive research stay on-premises while users get the GPU acceleration their applications require.
MIG: One GPU, Multiple Workloads in Your GPU Infrastructure
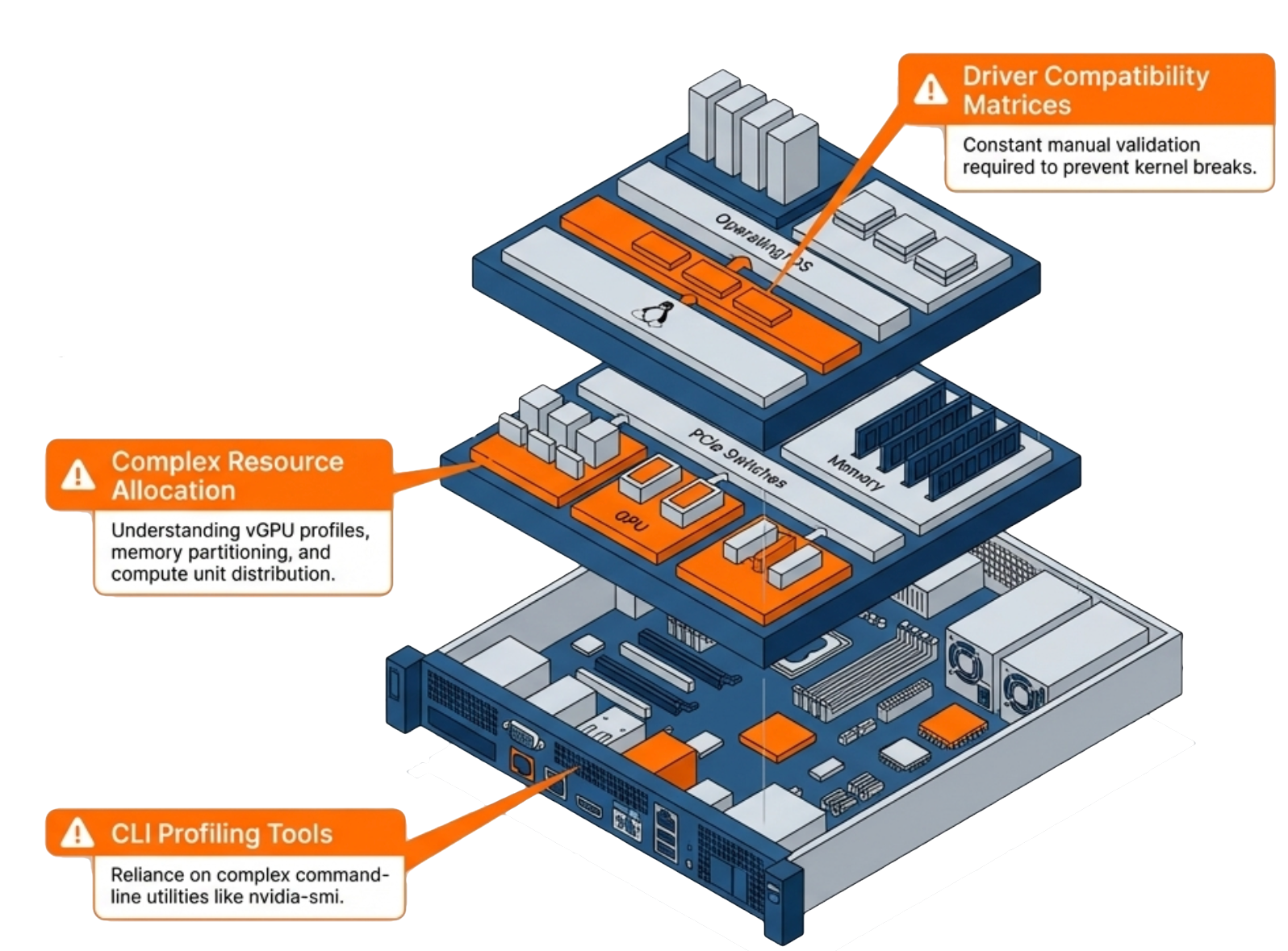
Not every workload in your GPU infrastructure needs a full GPU. An aerospace engineer performing interactive mesh preparation or real-time flow visualization does not require the same resources as a team running high-fidelity CFD simulations for multi-stage aero-acoustic modeling. Traditional GPU allocation forces a choice: dedicate an entire GPU to a single workload or deal with the complexity of manual resource sharing.
NVIDIA Multi-Instance GPU (MIG) solves this problem by partitioning a single physical GPU into multiple isolated instances. Each instance gets dedicated memory and compute resources. Workloads running on separate MIG instances do not interfere with each other, and each instance behaves as an independent GPU from the application’s perspective.
The catch: MIG configuration traditionally requires command-line expertise and careful planning. IT teams need to understand partition sizes, memory allocation, and how to reconfigure instances as workload requirements change. VergeOS automates MIG configuration through the same interface used for all other infrastructure management. Select the partition profile that matches your workload requirements, and VergeOS handles the rest. When requirements change, reconfigure without diving into command-line tools or GPU management utilities. The result is GPU infrastructure without the complexity of traditional GPU operations.
What It Means That NVIDIA Introduced VergeOS as a Supported vGPU Platform
NVIDIA introduced VergeOS as a supported vGPU platform — a status that reflects deep engineering and testing to handle the complexities of vGPU-backed visual compute and VDI workloads. For organizations running GPU infrastructure on VergeOS, that matters for one reason: support escalation paths. When something goes wrong, enterprises need to know both vendors will stand behind the deployment.
Joint support means IT teams can deploy vGPU workloads with confidence. If driver issues arise, both VergeOS and NVIDIA engineering teams collaborate on resolution — no finger-pointing, no gaps in coverage. This validation is what makes GPU infrastructure without the complexity a realistic outcome for standard IT teams, not just organizations with dedicated GPU staff.. For full details on what this covers, see the official announcement.
Practical Applications for Visual Compute and AI Development
Visual compute and AI development use cases extend across more workloads than most IT teams anticipate. Database acceleration is one example: GPUs dramatically reduce analytics query times on large datasets, giving business intelligence teams faster insights without specialized GPU infrastructure. These are scenarios standard IT teams can deploy today without GPU specialists:
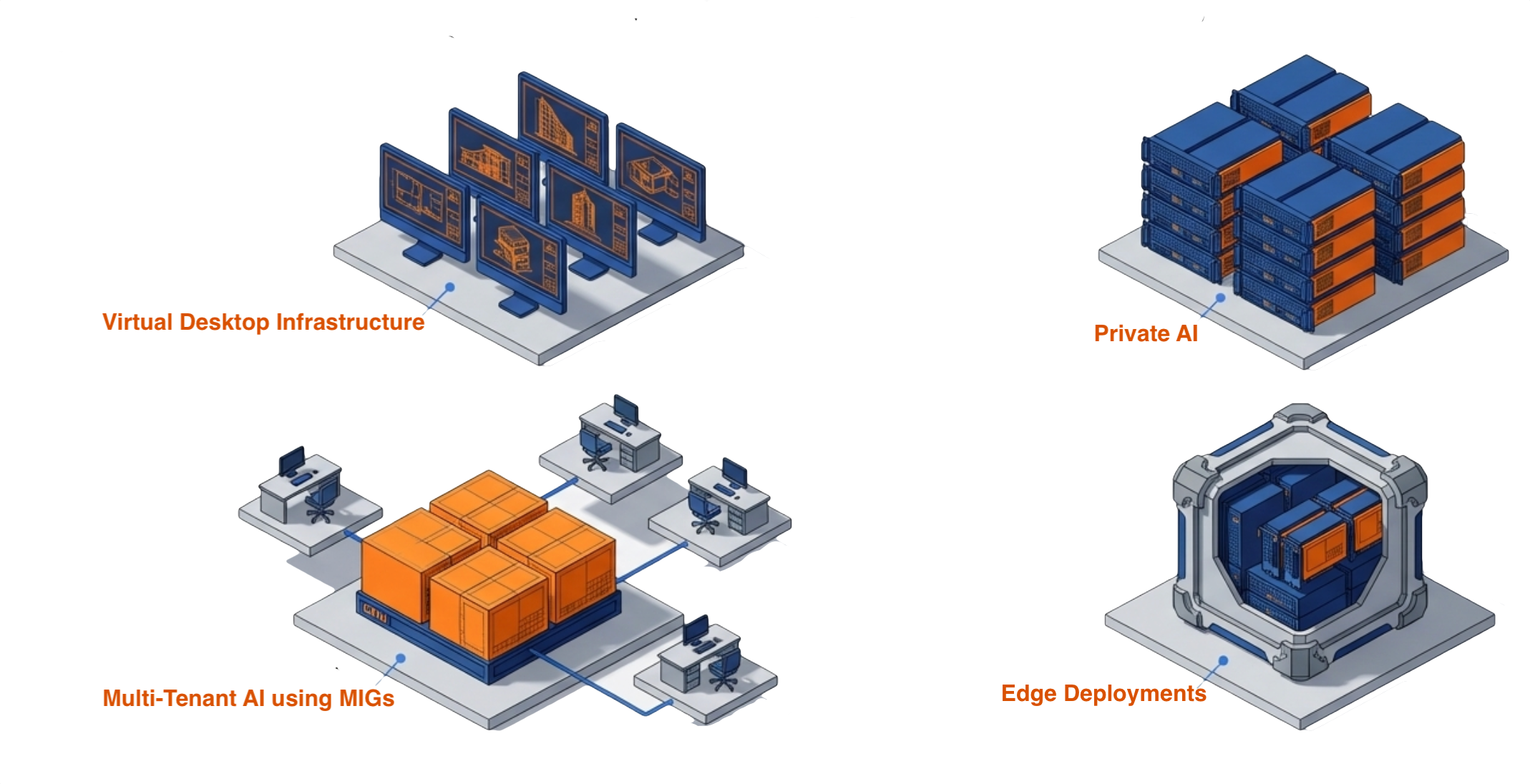
Engineering simulation and visualization gives engineers and scientists access to workstation-class GPU acceleration from centralized infrastructure. CFD simulation, mesh preparation, real-time flow visualization, and scientific rendering run in GPU-enabled VMs managed from the same interface as the rest of the stack.
VDI with GPU acceleration gives knowledge workers access to applications that previously required dedicated workstations. Engineering, design, and scientific visualization workloads run from centralized infrastructure while users connect from standard endpoints.
Multi-tenant visual compute splits a single high-end GPU across multiple data science or engineering teams. Each team gets an isolated MIG instance with guaranteed resources — no contention, no noisy-neighbor problems, and no need to purchase separate GPUs for each group.
AI development environments provide GPU resources on demand without physical hardware allocation. Spin up GPU-enabled VMs when needed and reclaim resources when projects complete.
Database and analytics acceleration uses GPUs for analytics workloads, dramatically reducing query times on large datasets. Business intelligence teams get faster insights without specialized database infrastructure.
Getting Started with GPU Infrastructure Without Complexity
Organizations with existing VergeOS deployments can add GPU infrastructure capabilities to their current environment without a rebuild. Install supported NVIDIA GPUs in your servers, and VergeOS handles driver management, MIG configuration, resource allocation, and monitoring — all from the same interface your team already operates. No separate management plane. No new interfaces to learn.
For organizations evaluating private cloud platforms, the NVIDIA partnership demonstrates where VergeOS is headed: an infrastructure layer that makes advanced capabilities accessible to standard IT operations, starting with GPU management and ready for whatever workloads come next. The goal remains consistent — eliminate the operational complexity that prevents organizations from using the infrastructure they already own. Visual compute and AI development should not require GPU specialists on staff.
Take a Test Drive Today — No hardware required.
See it live: join the GPU Virtualization Without the Complexity webinar on April 2nd at 1:00 PM ET for a live demonstration of MIG configuration, vGPU profiles, and one-time driver upload in a unified private cloud environment. Explore the full platform details on the Abstracted GPU Infrastructure page, or read the official announcement.
Frequently Asked Questions
What types of workloads benefit most from VergeOS GPU infrastructure?
Engineering simulation, scientific visualization, design rendering, VDI, and AI development are the primary use cases. Engineers running CFD simulation and mesh preparation, designers needing workstation-class GPU from centralized infrastructure, and data science teams running inference workloads on-premises all benefit without requiring dedicated hardware or GPU specialists.
Do we need to hire GPU specialists to run VergeOS with NVIDIA vGPU?
No. VergeOS manages driver deployment, MIG configuration, resource allocation, and GPU monitoring through the same interface IT teams already use for compute, storage, and networking. The platform abstracts GPU infrastructure complexity so sysadmins who have never managed a GPU can deploy and operate vGPU workloads from day one.
What is MIG and why does it matter for multi-tenant deployments?
Multi-Instance GPU partitions a single physical GPU into isolated instances at the hardware level. Each instance gets dedicated compute engines, memory, and bandwidth. Because the isolation is enforced in silicon, workloads in one MIG instance cannot affect neighboring instances — no noisy neighbor effects, no contention. For multi-tenant environments — multiple engineering teams, data science groups, or development projects — MIG provides the same guarantees as separate physical GPUs at a fraction of the cost.
What NVIDIA GPU hardware is supported with VergeOS today?
Currently validated data center GPUs include the A100, A30, A40, and L40 series in VergeOS 26.1.3. MIG vGPU functionality has been validated on the NVIDIA Blackwell RTX Pro 6000 Server Edition. NVIDIA vGPU software licenses are required for vGPU operation and are available through NVIDIA-authorized partners.
Where can I see VergeOS GPU infrastructure in action?
Register for the live webinar on April 2nd at 1:00 PM ET at GPU Virtualization Without the Complexity. The session covers pass-through, vGPU, and MIG configuration in a unified environment with a live demo. An on-demand replay will be available after the event.
Can existing VergeOS deployments add GPU capabilities without a full rebuild?
Yes. GPU infrastructure support is additive. Install supported NVIDIA GPUs into existing cluster nodes and VergeOS automatically detects and inventories the hardware. Upload the NVIDIA driver once and the platform handles bundling and deployment to guest VMs on assignment. No infrastructure rebuild, no new management tools.

