Storage refreshes break automation because storage vendors operate product families as independent platforms with incompatible APIs. When organizations also plan VMware exits, the problem compounds into dual automation redesign projects. This post explains why storage refreshes undermine infrastructure-as-code and how unified infrastructure platforms like VergeOS eliminate the need for automation rewrites entirely.
Key Takeaways
Storage refresh cycles break automation because new arrays introduce incompatible APIs and changed endpoints. Terraform providers lag behind firmware releases, causing modules to fail against new hardware. Authentication mechanisms shift between generations, requiring updates across hundreds of playbooks. What appears to be a routine hardware upgrade becomes an organization-wide automation redesign project.
Same-vendor standardization does not protect automation during refresh cycles. Dell maintains separate APIs for PowerStore, PowerMax, PowerFlex, Unity, and PowerScale. HPE splits between WSAPI for Primera and different REST APIs for Nimble. Pure separates FlashArray and FlashBlade schemas. Refreshing from one product to another within the same vendor requires nearly as extensive rewrites as switching vendors entirely.
Multi-generation support forces teams to maintain separate code paths simultaneously. Production runs firmware 6.2 while new arrays arrive with 7.1. Organizations cannot refresh all sites at once due to budget constraints, creating 12-18 month transitions where automation must support three or four generations concurrently. Terraform modules include version checks, Ansible playbooks test for capabilities, and technical debt compounds with each refresh cycle.
VergeOS eliminates storage refresh as an automation event through infrastructure abstraction. Storage runs as a distributed service across cluster nodes with one consistent API. Terraform modules reference storage services rather than hardware, remaining stable when new servers join clusters. Ansible roles work without firmware version checks or vendor detection logic. Organizations refresh hardware gradually without cutover events where automation breaks.
VMware exits and storage refreshes create natural timing alignment for infrastructure simplification. Traditional approaches treat these as sequential projects requiring two separate automation rewrites. VergeOS delivers both VMware alternative and storage consolidation in one platform transition, building a single automation framework instead of coordinating separate efforts for compute and storage layers.
Unified infrastructure makes automation investments durable across decades of hardware refresh. Traditional arrays require continuous automation updates every three to five years as teams rebuild for each refresh cycle. VergeOS code remains stable across hardware transitions as new servers join without triggering updates, drive types change without affecting modules, and capacity grows without modifying playbooks. Technical debt decreases rather than accumulating platform-specific exceptions.
Why Storage Refresh Projects Break Working Automation
Most organizations refresh storage hardware every 3 to 5 years, expecting a straightforward process for data migration, capacity updates, and array retirement. Instead, the refresh becomes an automation redesign project when new arrays arrive with different firmware and changed API endpoints.
The refresh cycle creates multiple automation failures:
- Terraform providers lag behind firmware releases, causing modules to fail against new hardware
- API endpoints change between storage generations, breaking working provisioning code
- Authentication mechanisms shift from token-based to OAuth or CSRF flows
- Resource definitions differ between old and new array models
- Monitoring exporters becomes incompatible with new firmware versions
Teams face an expensive choice: either maintain two parallel automation paths during the transition or halt automation entirely while rebuilding it for the new platform. The first option doubles the maintenance burden, while the second extends manual procedures precisely when the organization needs automation most—during a major infrastructure transition.
The refresh cycle reveals a fundamental problem: automation built on storage arrays inherits their fragmentation. When the hardware changes, the automation must change with it.
Key Terms & Concepts
Storage Refresh Cycle: The three-to-five-year hardware replacement cycle where organizations migrate from aging storage arrays to new models. Refresh cycles typically break infrastructure automation because new arrays introduce incompatible APIs, changed endpoints, and different authentication patterns that require extensive code rewrites.
API Fragmentation: The condition where storage vendors operate product lines as independent platforms with incompatible application programming interfaces. Organizations discover that Terraform modules written for one product within a vendor family cannot provision storage on another product despite the same vendor relationship, requiring complete automation rewrites during refresh.
Multi-Generation Support: The operational requirement to maintain automation code that works across multiple storage firmware generations simultaneously. Organizations refreshing storage over 12-18 month periods must support three or four array generations at once, forcing teams to write conditional logic that detects versions and branches accordingly.
Firmware Version Drift: The gradual divergence of storage array firmware versions across production, DR, and branch office sites during phased refresh cycles. Production might run firmware 6.2 while new arrays arrive with 7.1, causing API endpoint changes that break Terraform modules and require separate code paths for each version.
Storage Service Abstraction: An infrastructure architecture where storage runs as a distributed service within the operating system rather than as external arrays with vendor-specific APIs. VergeOS provides storage service abstraction that keeps automation code stable across hardware refresh because modules reference services instead of physical storage hardware.
Packer: A HashiCorp tool for creating identical machine images from a single source configuration. Packer builds golden images containing the operating system and pre-installed software. Storage refresh breaks Packer workflows when new arrays require different guest drivers or storage-backend-specific configurations in image templates.
Terraform: A HashiCorp infrastructure-as-code tool that provisions and manages infrastructure using declarative configuration. Terraform modules define storage volumes, networks, and VMs through provider-specific resource definitions. Storage refresh breaks Terraform when new arrays expose different APIs requiring new providers, resource definitions, and authentication patterns.
Ansible: A configuration management tool that automates software installation and system configuration through playbooks and roles. Ansible configures storage paths, mounts volumes, and manages storage-dependent services. Storage refresh breaks Ansible when authentication mechanisms change between array generations or when new firmware exposes different management endpoints.
Prometheus: An open-source monitoring and alerting system that collects metrics from infrastructure components through exporters. Storage arrays require vendor-specific Prometheus exporters that expose metrics through incompatible schemas. Storage refresh forces monitoring rebuilds when new arrays need different exporters with changed metric structures.
Grafana: A visualization platform that creates dashboards and graphs from time-series data collected by monitoring systems like Prometheus. Grafana dashboards built for specific storage arrays use vendor-specific queries and metric labels. Storage refresh breaks dashboards when new arrays expose performance data through incompatible metric schemas requiring complete dashboard reconstruction.
The Same-Vendor Refresh Problem
Organizations standardize on a single storage vendor to simplify operations, assuming that staying within one vendor family protects automation investments during refresh cycles. The reality disappoints because storage vendors operate product lines as independent platforms with incompatible APIs, requiring nearly as extensive automation rewrites when refreshing between products as when switching vendors entirely.
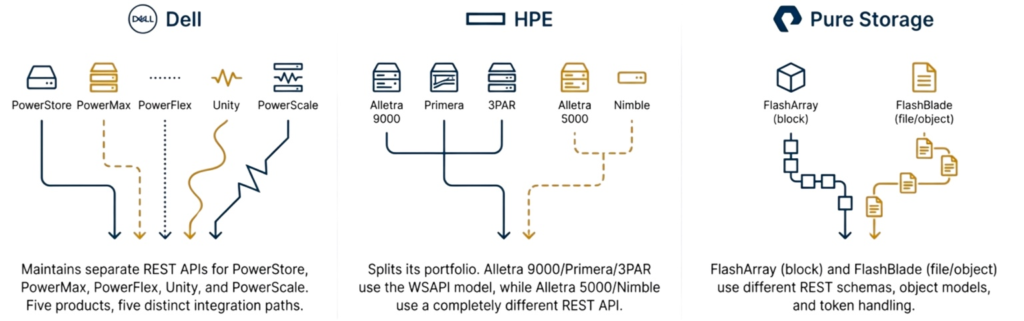
Dell maintains separate REST APIs for PowerStore, PowerMax, PowerFlex, Unity, and PowerScale, preventing Terraform modules from transferring between products. An organization migrating from Unity to PowerStore discovers that resource definitions, authentication patterns, and JSON structures differ enough to require complete rewrites, even though it remains within the Dell portfolio.
HPE splits its portfolio along architectural lines where Alletra 9000/MP, Primera, and 3PAR share the WSAPI model, while Alletra 5000/6000 and Nimble use a completely different REST API. A refresh from 3PAR to Nimble requires complete Ansible playbook rewrites because the same provisioning task demands different implementations within the HPE product family.
Pure Storage follows a similar pattern: FlashArray handles block storage via a single REST schema, while FlashBlade handles file and object storage via a separate schema. Organizations transitioning to unified block and file storage discover their block automation fails for file workloads despite both arrays carrying Pure branding.
Single-vendor standardization reduces procurement complexity but fails to protect automation during refresh cycles. Teams still rewrite platform-specific integration code when moving between product lines, and fragmented infrastructure breaks automation regardless of vendor loyalty. I explored the storage integration problem in depth for Blocks and Files, examining how API fragmentation undermines infrastructure-as-code across refresh cycles.
The Multi-Generation Refresh Trap
Storage refresh cycles create version drift between environments when production runs on three-year-old arrays while new hardware arrives with the latest firmware and new management interfaces. Terraform modules that work in production fail during testing because API endpoints changed between storage generations, not because of coding errors.
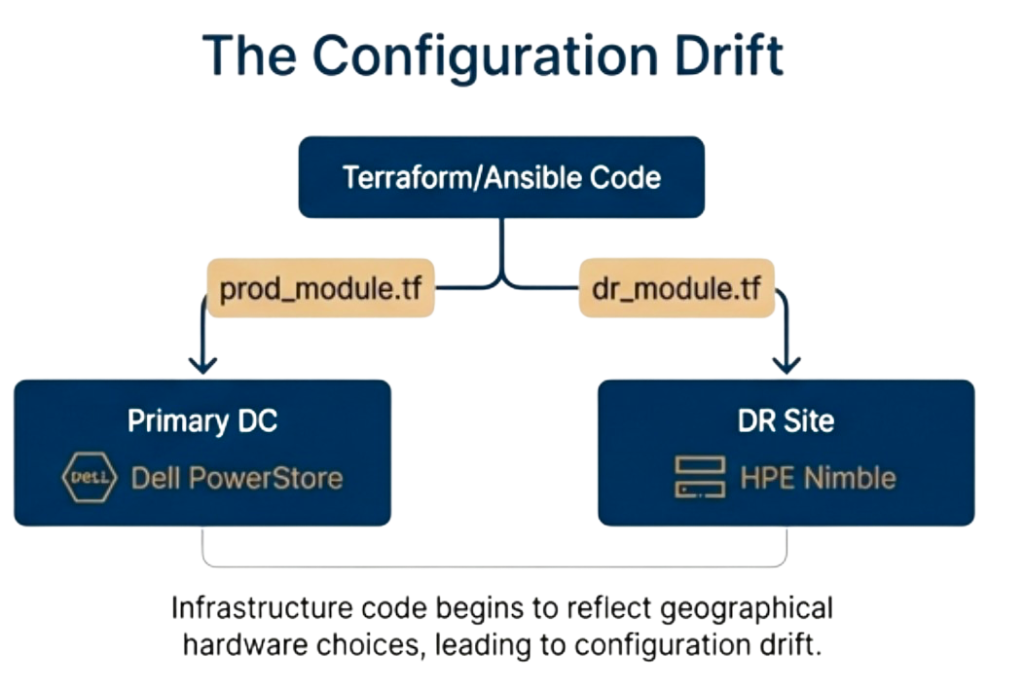
Organizations cannot refresh all sites simultaneously due to budget constraints and risk management requirements that mandate phased approaches. Production refreshes first, DR sites refresh six months later, and branch offices refresh over eighteen months, forcing the automation framework to support multiple storage generations simultaneously during this extended period.
Teams write conditional logic to detect array firmware versions and branch accordingly, while Terraform modules include version checks and Ansible playbooks test for API capabilities before executing tasks. The automation code that should abstract storage details instead catalogs firmware-specific quirks across three or four generations.
Authentication patterns shift across storage generations: older arrays use simple token-based authentication, while newer models require session management with CSRF tokens or OAuth flows. Ansible roles that worked reliably for years suddenly fail because the authentication mechanism changed, requiring updates to every playbook that touches storage—hundreds of files across multiple repositories.
The maintenance burden grows with each refresh cycle as teams maintain automation for Generation N while building automation for Generation N+1. When Generation N+2 arrives, it supports three distinct code paths simultaneously, and technical debt compounds because each generation introduces breaking changes that require separate handling.
The Cross-Vendor Refresh Penalty
Organizations switching storage vendors during refresh cycles see firsthand why storage refreshes break automation. They face complete automation reconstruction regardless of whether pricing, features, or acquisition changes drive the decision. A team migrating from Dell PowerStore to HPE Primera must rewrite every Terraform module because resource definitions differ completely, authentication models follow different patterns, and error handling uses different status codes and message formats.
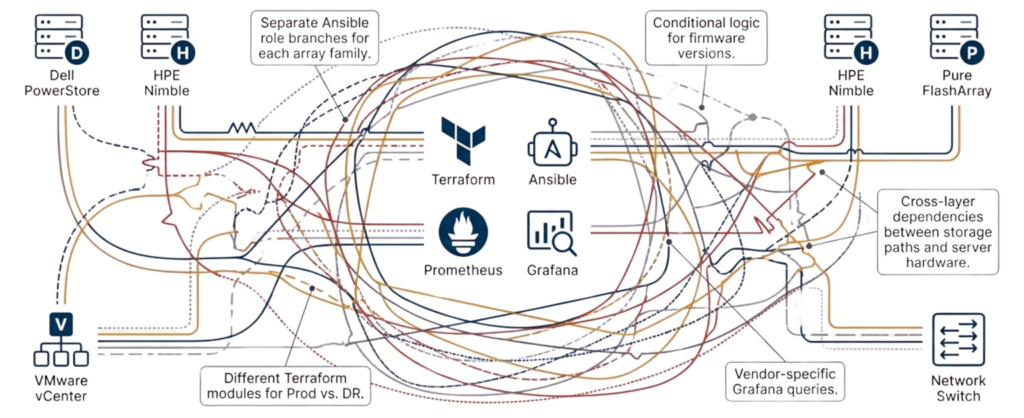
The complexity extends beyond Terraform into vendor-specific Ansible collections, where Dell arrays use different playbook structures than HPE arrays. Monitoring integration requires multiple Prometheus exporters with incompatible metric schemas, preventing Grafana dashboards built for Dell arrays from displaying HPE metrics without a complete rebuild.
Some vendors support Terraform but not Ansible, while others support Ansible but not Terraform, forcing teams to refresh from vendor A to vendor B to learn entirely new automation tools. This rebuilds not just automation code but also operational skill sets and workflows simultaneously.
The penalty applies equally to hypervisor and network layers, where VMware environments depend on vCenter APIs, while organizations migrating to different hypervisors rebuild automation around new management interfaces. Network automation tied to specific switch families requires rewriting when fabric hardware refreshes, triggering independent automation redesign efforts across storage, compute, and network layers.
Storage refresh cycles that appear to be routine hardware upgrades become organization-wide automation projects, with technical debt accumulating as teams maintain parallel automation paths during transitions spanning 12 to 18 months across all sites.
How VergeOS Eliminates Storage Refresh Complexity
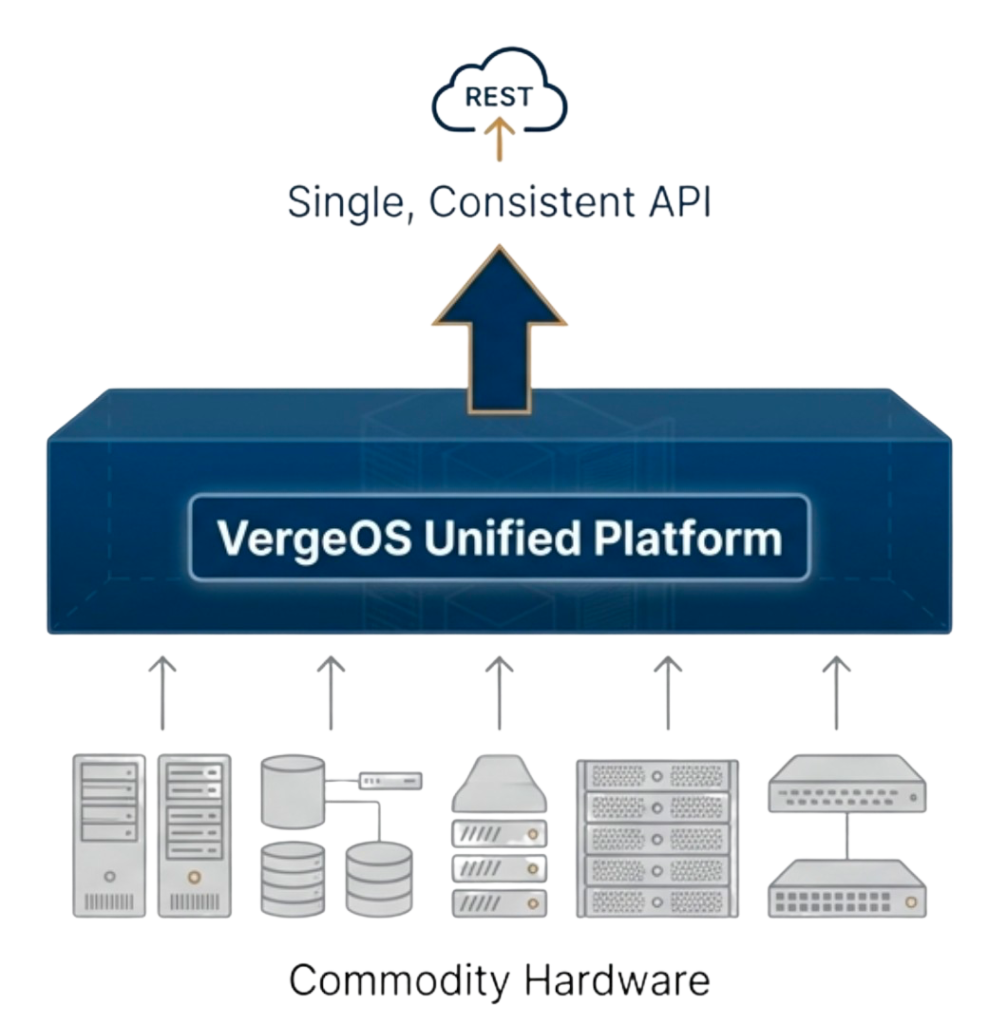
VergeOS approaches storage differently by integrating storage, compute, and networking into a single operating system with one API. Storage runs as a distributed service across cluster nodes rather than as external arrays, eliminating the disruption to automation caused by storage refreshes.
Teams write Terraform modules that reference storage services rather than storage hardware, keeping modules stable across refresh cycles because VergeOS handles storage presentation internally. A volume provisioning module works identically whether the underlying drives are three-year-old SATA SSDs or new NVMe devices added during a refresh, preventing the automation layer from interacting directly with storage hardware.
VergeOS delivers specific automation advantages during storage refresh:
- Terraform modules remain unchanged when new servers join clusters
- Ansible roles continue working without firmware version checks or conditional logic
- Monitoring dashboards display consistent metrics across all hardware generations
- Authentication patterns stay constant regardless of the underlying hardware vendor
- Storage service layer abstracts drive types, server models, and firmware versions
- Organizations refresh sites independently without maintaining separate code branches
Hardware refresh becomes straightforward when new servers join the cluster, and VergeOS absorbs them into the storage pool while Terraform modules, Ansible roles, and monitoring continue working without modification. The automation code remains untouched because the platform maintains abstraction across hardware transitions.
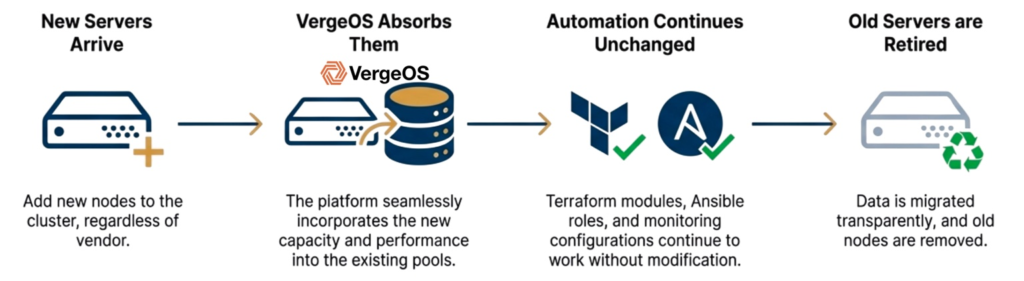
Organizations can refresh storage hardware gradually by adding new servers with modern drives while removing old servers with aging drives. The cluster capacity adjusts dynamically while the storage service continues presenting the same interface to automation tools throughout the transition, eliminating cutover events where automation suddenly breaks.
Why VMware Exits and Storage Refreshes Align
Organizations leaving VMware often discover their storage is also approaching refresh timing, as three-to-five-year storage cycles and VMware licensing concerns create natural alignment. Traditional approaches treat these as sequential projects by refreshing storage first, then addressing VMware, doubling the automation redesign burden unnecessarily.
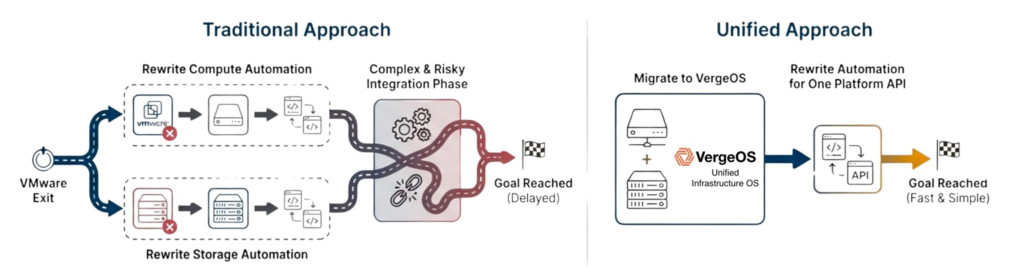
VergeOS changes this calculation by delivering both a VMware alternative and storage consolidation in one platform transition. The automation rewrite occurs only once, eliminating future refresh-driven rewrites and maintaining code compatibility when new servers or drive types are introduced, because the storage service layer remains constant.
Terraform modules address unified infrastructure rather than separate hypervisor and storage layers, while Ansible roles configure services rather than navigating vendor-specific APIs. The migration complexity decreases because teams build a single automation framework rather than coordinating separate efforts for compute and storage.
Storage refresh timing accelerates VMware decisions as organizations evaluating alternatives recognize they face two major transitions regardless. Combining them reduces total disruption time while delivering infrastructure that supports automation rather than resisting it. Organizations seeking to build end-to-end automation chains find that unified infrastructure eliminates the dual automation burden of separate hypervisor and storage management layers.
| Aspect | Traditional Storage Arrays | VergeOS Unified Infrastructure |
|---|---|---|
| Refresh Automation Impact | New arrays break Terraform modules and Ansible playbooks. Teams rebuild automation for new firmware and APIs. | Automation unchanged. New servers join without code updates. Storage service abstracts hardware. |
| Multi-Generation Support | Separate code paths per firmware generation. Conditional logic detects versions. Supports 3-4 generations simultaneously. | Single code path across all generations. No version detection. Same automation works on old and new hardware. |
| Cross-Vendor Refresh Penalty | Complete reconstruction. New providers, collections, exporters. May require new automation tools. | No vendor lock-in. Replace hardware from any vendor without automation changes. |
| VMware Exit Alignment | Sequential projects. Storage refresh then VMware exit. Two automation rewrites. | Combined transition. One framework for unified infrastructure. Single migration. |
| Hardware Refresh Process | Cutover event breaks automation. Dual maintenance during migration. Testing reveals broken modules. | Gradual refresh without cutover. Add new, remove old. No automation break point. |
| Long-Term Maintenance Cost | Continuous updates every 3-5 years. Rebuild for each refresh. Multi-platform expertise required. | One-time investment. Code stable across decades. Reduced platform-specific expertise. |
The Storage Refresh Decision
Storage refresh cycles force a strategic decision between replacing arrays with newer arrays from the same or different vendors while maintaining the fragmentation that breaks automation, or shifting to unified infrastructure platforms that eliminate storage as a separate automation concern entirely.
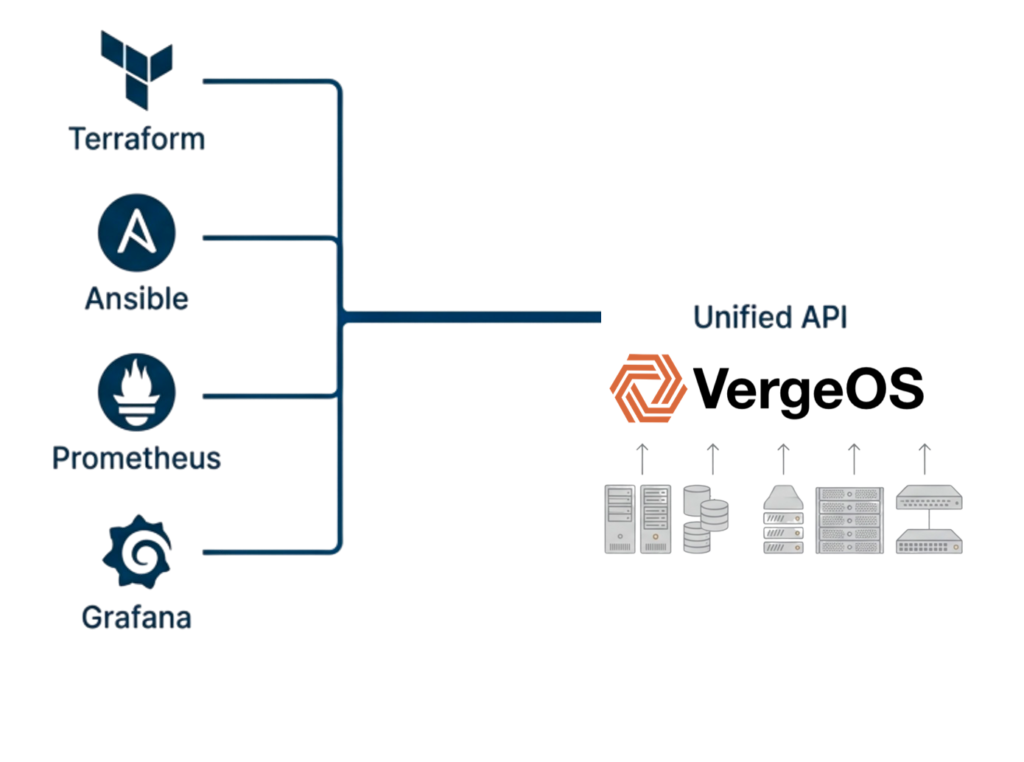
Traditional storage refreshes break automation because new arrays arrive with different APIs, forcing teams to update Terraform providers, rewrite Ansible collections, and rebuild monitoring dashboards. The automation framework continues tracking vendor-specific details across product families and firmware generations until three years later, when the next refresh cycle repeats the same painful process.
VergeOS removes storage refreshes as an automation event, enabling teams to write infrastructure code that describes services rather than hardware. The code remains stable across refresh cycles as new servers join clusters without triggering automation updates, drive types change without affecting Terraform modules, and storage capacity grows without modifying Ansible playbooks.
Organizations gain predictable automation that survives hardware transitions, while infrastructure supports automation rather than undermining it every 3 to 5 years. The choice determines whether the next decade follows the same refresh-and-rewrite pattern or whether the organization moves toward infrastructure that makes automation investments durable.
Storage refresh breaks automation when storage exists as external arrays with vendor-specific APIs. Storage refresh becomes invisible to automation when storage integrates into the infrastructure operating system as an abstracted service. The difference shapes operational efficiency for years.
Frequently Asked Questions
How often do storage refresh cycles occur and why do they break automation?
Most organizations refresh storage hardware every three to five years due to warranty expirations, capacity needs, or performance requirements. Refresh cycles break automation because new storage arrays arrive with different firmware versions that expose changed API endpoints, modified authentication patterns, and incompatible resource definitions. Terraform modules written for the old arrays fail against new hardware even when staying within the same vendor family.
Does standardizing on a single storage vendor protect automation during refresh cycles?
No. Storage vendors operate product lines as independent platforms with incompatible APIs. Dell maintains separate REST APIs for PowerStore, PowerMax, PowerFlex, Unity, and PowerScale. HPE splits between WSAPI for Primera and different APIs for Nimble. A refresh from one product to another within the same vendor requires nearly as extensive automation rewrites as switching vendors entirely because resource definitions, authentication models, and JSON structures all differ.
What happens to automation when organizations cannot refresh all sites simultaneously?
Organizations face extended transitions spanning twelve to eighteen months where automation must support multiple storage generations simultaneously. Production refreshes first, DR sites refresh six months later, and branch offices refresh over many months due to budget constraints and risk management. Teams write conditional logic to detect firmware versions and branch accordingly, maintaining separate code paths for three or four array generations at once while technical debt compounds.
Can better planning or phased Terraform modules avoid the automation rewrite problem?
No. The problem is architectural, not procedural. Storage arrays expose vendor-specific APIs that change between product generations and firmware versions. Better planning cannot eliminate API incompatibility between array models or prevent authentication mechanism changes between generations. Conditional logic and version detection simply move complexity into automation code rather than solving the underlying fragmentation.
How much does it cost to maintain dual automation paths during storage refresh transitions?
Organizations pay for parallel maintenance of old and new automation during transitions that span twelve to eighteen months across all sites. Teams maintain Terraform modules for Generation N while building modules for Generation N+1, effectively doubling the automation workload. This includes separate Ansible collections, different Prometheus exporters, and rebuilt Grafana dashboards for each storage platform, consuming weeks or months of engineering time that could address other priorities.
What happens if we delay storage refresh to avoid automation disruption?
Delayed refresh accumulates risk through aging hardware, expired warranties, and degraded performance while automation problems persist and worsen. Firmware falls further behind as vendors deprecate support for older array models. When refresh becomes unavoidable due to hardware failure or capacity constraints, the automation gap widens because newer arrays diverge further from aging platforms, making eventual migration even more disruptive.
How does VergeOS handle storage refresh differently from traditional arrays?
VergeOS integrates storage as a distributed service within the infrastructure operating system rather than as external arrays. Teams write Terraform modules that reference storage services instead of hardware, keeping code stable when new servers join clusters. The storage service layer abstracts drive types, server models, and firmware versions so automation never interacts with storage hardware directly. New servers join gradually without cutover events where automation breaks.
Can existing automation transfer to VergeOS or does migration require complete rewrites?
Migration requires rewriting automation because the architectural model changes from managing external arrays to referencing infrastructure services. However, this is a one-time rewrite that eliminates future refresh-driven rewrites entirely. The automation investment becomes durable across decades of hardware refresh rather than requiring updates every three to five years. The code simplifies because it no longer needs vendor detection, firmware version checks, or generation-specific conditionals.
Why do VMware exits and storage refreshes create natural timing alignment?
Three-to-five-year storage cycles often align with VMware licensing decisions as organizations evaluate alternatives. Traditional approaches treat these as sequential projects requiring two separate automation rewrites—first for storage refresh, then for hypervisor migration. VergeOS delivers both VMware alternative and storage consolidation in one platform transition, building a single automation framework instead of coordinating separate efforts for compute and storage layers.
What happens to monitoring and observability during storage refresh on traditional arrays versus VergeOS?
Traditional arrays require vendor-specific Prometheus exporters per storage family with incompatible metric schemas. Storage refresh forces complete Grafana dashboard reconstruction because new arrays expose performance data through different metric structures and label hierarchies. VergeOS provides one Prometheus exporter for all infrastructure where dashboards remain unchanged across hardware refresh because the platform exposes unified metrics regardless of underlying server or drive vendor.
Most organizations refresh storage hardware every 3 to 5 years due to warranty expirations, capacity requirements, or performance requirements. Refresh cycles break automation because new storage arrays arrive with different firmware versions that expose changed API endpoints, modified authentication patterns, and incompatible resource definitions. Terraform modules written for the old arrays fail on new hardware, even when using the same vendor family.
No. Storage vendors operate product lines as independent platforms with incompatible APIs. Dell maintains separate REST APIs for PowerStore, PowerMax, PowerFlex, Unity, and PowerScale. HPE splits between WSAPI for Primera and different APIs for Nimble. A refresh from one product to another within the same vendor requires nearly as extensive automation rewrites as switching vendors entirely because resource definitions, authentication models, and JSON structures all differ.
Organizations face extended transitions spanning twelve to eighteen months where automation must support multiple storage generations simultaneously. Production refreshes first, DR sites refresh six months later, and branch offices refresh over many months due to budget constraints and risk management. Teams write conditional logic to detect firmware versions and branch accordingly, maintaining separate code paths for three or four array generations at once while technical debt compounds.
No. The problem is architectural, not procedural. Storage arrays expose vendor-specific APIs that change between product generations and firmware versions. Better planning cannot eliminate API incompatibility between array models or prevent changes to authentication mechanisms between generations. Conditional logic and version detection simply shift complexity into the automation code rather than addressing the underlying fragmentation.
Organizations pay for parallel maintenance of both old and new automation during transitions that span 12 to 18 months across all sites. Teams maintain Terraform modules for Generation N while building modules for Generation N+1, effectively doubling the automation workload. This includes separate Ansible collections, different Prometheus exporters, and rebuilt Grafana dashboards for each storage platform, consuming weeks or months of engineering time that could be devoted to other priorities.
Delayed refresh accumulates risk through aging hardware, expired warranties, and degraded performance while automation problems persist and worsen. Firmware falls further behind as vendors deprecate support for older array models. When refresh becomes unavoidable due to hardware failure or capacity constraints, the automation gap widens because newer arrays diverge further from aging platforms, making eventual migration even more disruptive.
VergeOS integrates storage as a distributed service within the infrastructure operating system rather than as external arrays. Teams write Terraform modules that reference storage services instead of hardware, keeping code stable when new servers join clusters. The storage service layer abstracts drive types, server models, and firmware versions so automation never interacts with storage hardware directly. New servers join gradually without cutover events where automation breaks.
Three-to-five-year storage cycles often align with VMware licensing decisions as organizations evaluate alternatives. Traditional approaches treat these as sequential projects requiring two separate automation rewrites—first for storage refresh, then for hypervisor migration. VergeOS delivers both VMware alternative and storage consolidation in one platform transition, building a single automation framework instead of coordinating separate efforts for compute and storage layers.
Traditional arrays require vendor-specific Prometheus exporters per storage family with incompatible metric schemas. Storage refresh forces complete Grafana dashboard reconstruction because new arrays expose performance data through different metric structures and label hierarchies. VergeOS provides one Prometheus exporter for all infrastructure where dashboards remain unchanged across hardware refresh because the platform exposes unified metrics regardless of underlying server or drive vendor.