As enterprises plan their VMware exit, one of the biggest risks is falling into the hypervisor sprawl trap. The hypervisor sprawl trap is the cycle where organizations replace VMware with multiple hypervisors or cloud services for specific use cases, creating fragmented operations, higher costs, and diluted expertise instead of true simplification.

The reality is that many enterprises run more than one hypervisor, even more if you factor in public cloud use. This mix is manageable for now, but Broadcom’s acquisition of VMware is forcing more organizations to reevaluate their strategies. If the response is treated as a quick hypervisor swap, it may potentially lead to the addition of more hypervisors.
The wiser course is to view the VMware transition as an opportunity to simplify complexity. The goal should not be a one-for-one hypervisor trade but the adoption of a unified infrastructure platform that integrates virtualization, storage, networking, and protection. A single operating model reduces cost, simplifies operations, and creates a foundation for private AI.
How the Hypervisor Sprawl Trap is Sprung
The hypervisor sprawl trap rarely arrives in one step. It builds in layers.
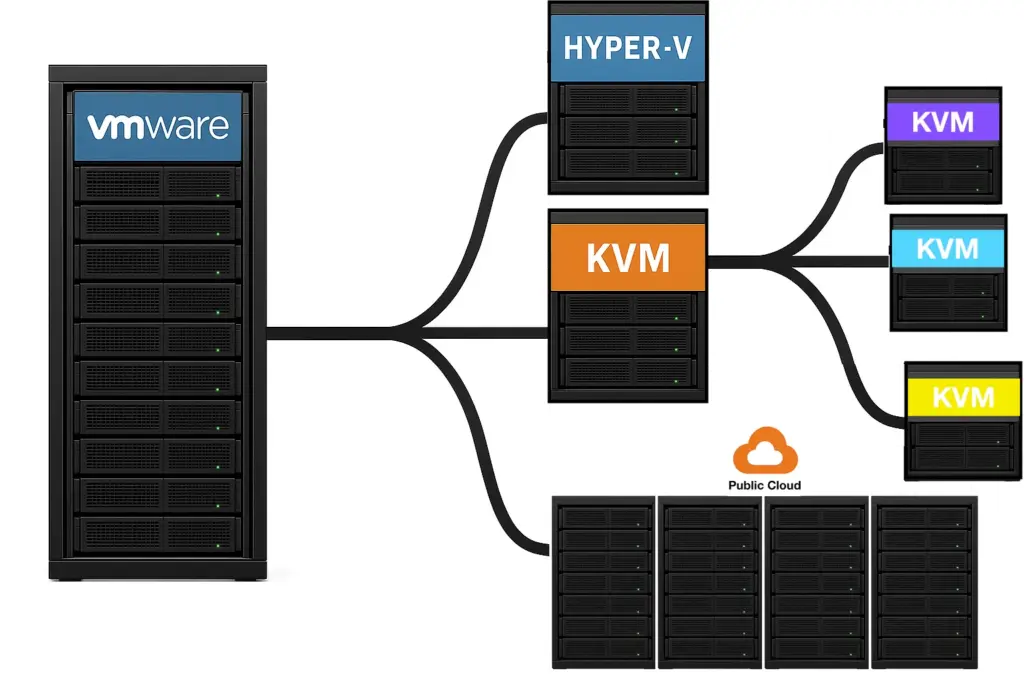
- The core data center adopts a hypervisor because it is less expensive than VMware and has near feature parity.
- Edge and ROBO groups want to adopt lightweight KVM builds for small deployments because the core selection is too “heavy.”
- AI teams want to experiment with GPU-focused variants because the core selection has weak or expensive GPU support.
- Business Unit Managers approve cloud migrations to speed the deployment of new applications because the core selection is too complex.
Each decision makes sense individually, but together they create a fractured environment that is harder to manage and more expensive to run.
The Cost of The Hypervisor Sprawl Trap
The first phase of the hypervisor sprawl trap can appear to save money. A “free” hypervisor delays a license renewal. A cloud migration shifts capital expense into operating expense. Those savings are short-lived, and the cost of falling into the hypervisor sprawl trap soon becomes obvious. Each new hypervisor introduces its own patch cycle, interface, and failure model. Training grows broader, but skills become shallow. Monitoring, backup, and automation tools multiply. Disaster recovery plans diverge, and testing becomes longer and less predictable.

The use of the Cloud compounds the hypervisor sprawl trap. Lift-and-shift projects rarely eliminate on-premises complexity. They add monthly expenses and force IT to maintain separate operational silos. Edge and ROBO hypervisors create their own islands of management. Instead of simplifying the environment, sprawl increases both direct cost and hidden overhead.
Over five years, the total cost of a hypervisor swap mentality can exceed even VMware’s high licensing costs while leaving IT with weaker recovery capabilities and higher operational risk.
The Better Path: Infrastructure Consolidation
Broadcom’s actions are a forcing function. Enterprises can either fall into the hypervisor sprawl trap or set a clearer goal. The right objective is complete consolidation under one infrastructure-wide operating model that spans the core data center, private AI, edge, venues, and remote offices. Storage, networking, and protection must be part of that model.
A single infrastructure platform restores consistency. Incident response improves when all workloads are managed through one console. Disaster recovery becomes more reliable when there is one failover pattern. Compliance checks are faster when policies are enforced consistently across the environment. Teams deepen their expertise because they are not spread across competing tools. Cloud use becomes tactical and deliberate rather than a default escape from licensing costs.
Start with a Universal Migration Capability
Migration from VMware, Hyper-V, KVM variants, and cloud instances should be part of IT’s core capabilities, not added later. The majority of enterprises are living with degrees of fragmentation. The right move is to reverse it.
A universal migration tool makes this process a repeatable practice for IT. Platforms such as Cirrus Data provide the ability to move workloads from VMware, Hyper-V, KVM variants, and public cloud with minimal disruption, which is the first step in avoiding the hypervisor sprawl trap. They manage bandwidth, schedule cutovers, and create audit trails. With tools like these, migration becomes a permanent capability rather than a special project, making it possible to unwind sprawl when it begins to form.
Plan a series of consolidation waves. Begin with workloads that are lower risk but generate high administrative costs. Use them to prove migration and rollback processes, and to refine team procedures. With each wave, expand to higher-value workloads and remove duplicate tools. Cloud workloads should be treated with the same rigor. SaaS adoption will remain, but many lift-and-shift VMs are better brought back into the consolidated platform when contract terms permit.
A universal migration capability is essential because consolidation only works when migrations can move workloads into the chosen destination platform quickly, safely, and at scale.
VergeOS: The Universal Destination
As migration tools provide the means to reverse the hypervisor sprawl trap, so VergeOS provides the destination. The majority of VMware alternatives re-package KVM and expect IT to fill the gaps. Although VergeOS is KVM-based, it removes those gaps by going a step further and integrating virtualization (VergeHV), storage (VergeFS), networking (VergeFabric), and AI (VergeIQ) into a unified code base. The result is a hardware-neutral, efficient, high performance environment designed to extend the life of current hardware while increasing selection flexibility in the future.
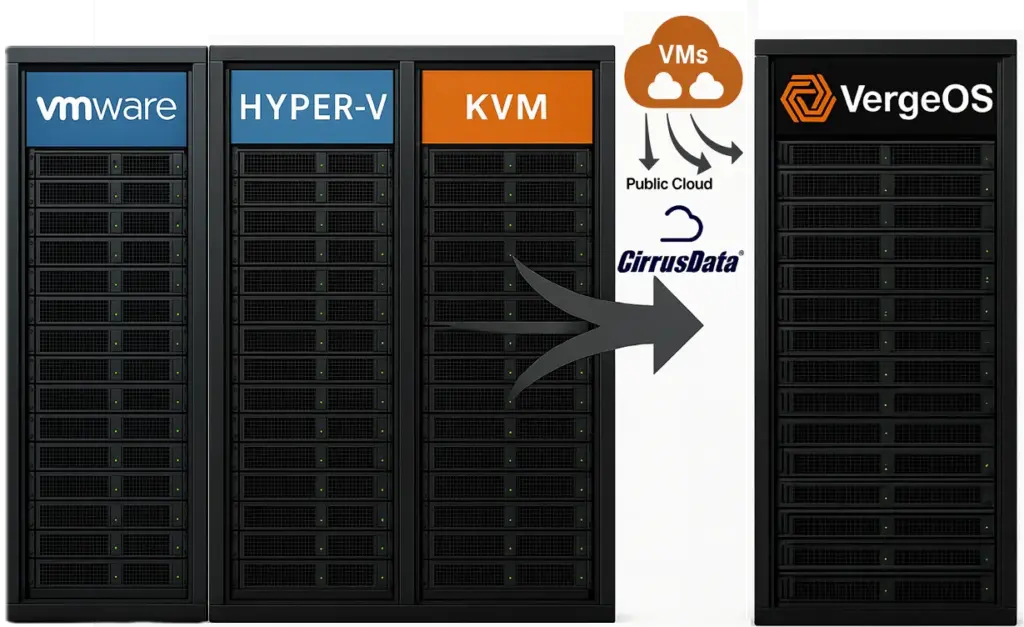
Workloads from VMware, Hyper-V, KVM distributions, and cloud services can all be hosted on the same platform. Management takes place through one interface. Data reduction is applied across the stack, cutting I/O and bandwidth. High availability, immutable recovery points, and consistent networking policies are built into the software.
Together, Cirrus Data provides the universal migration capability, and VergeOS delivers the unified destination. This combination makes it possible to eliminate sprawl permanently rather than only trading one hypervisor for another.
To see this partnership in action register for our live webinar “After the VMware Exit: How to Consolidate, Repatriate, and Prepare for AI.”
The result is true infrastructure consolidation. One operating model spans the data center, edge, AI, venues, and remote offices. Teams train on one system, gaining depth instead of spreading thin. Costs track with hardware rather than feature packs or add-ons. VergeOS turns the VMware transition into a permanent infrastructure upgrade rather than a short-term trade.
Escaping The Hypervisor Sprawl Trap Permanently
Enterprises operate with more than one hypervisor, and the VMware disruption threatens to expand that sprawl. Deploying different hypervisors for edge, AI, and ROBO workloads increases complexity, and cloud lift-and-shift projects make the problem worse. The better answer is infrastructure consolidation. A universal migration tool, such as Cirrus Data, provides the means, and VergeOS provides the destination.
Enterprises should resist the temptation to treat the VMware exit as only a hypervisor swap and instead look for a unified infrastructure-wide operating platform. The outcome is lower cost, stronger expertise, and a single platform ready to support the next generation of workloads, including private AI. After the VMware exit, the goal is not to manage sprawl. The goal is to eliminate it.
The choice is clear: consolidate now with a universal migration path and a unified infrastructure platform, or carry the cost of sprawl into the future. Schedule a technical whiteboard session to dive deep into the VergeOS architecture.


