Software limits infrastructure scale, not hardware. Organizations can add servers indefinitely, but if the software managing those servers introduces exponential coordination overhead, growth becomes a liability rather than an advantage. When scaling breaks, the cost isn’t just slower performance — it’s wasted hardware investment, delayed deployment, and ballooning operational overhead.
How Infrastructure Software Limits Scale
Organizations regularly encounter performance challenges when scaling traditional infrastructure beyond certain thresholds. The addition of hardware proceeds successfully—servers, networking, storage—but the expected linear performance improvement doesn’t materialize. The problem isn’t insufficient hardware. It’s architectural friction. Storage synchronization overhead, distributed routing complexity, and management coordination lag all compound as clusters grow. Resource contention increases, noisy neighbor scenarios multiply, and troubleshooting becomes more complex as failure domains expand.
This pattern repeats across the industry. Software limits infrastructure scale at predictable points—not from hardware failures, but from architectures that never anticipated modern scale requirements. Adding nodes or deploying more VMs doesn’t equal true scalability when compute, storage, and networking are managed by separate systems, each maintaining its own metadata and requiring constant coordination.
VMware and Nutanix hide architectural fragmentation behind unified management GUIs. Underneath, they still rely on multiple disconnected applications and data stores. As environments grow, this fragmentation compounds. More inter-process traffic within nodes. More synchronization overhead across clusters. More performance bottlenecks that degrade predictably with scale.
The solution isn’t another product layer, hyperconverged bundle, or management overlay. It’s a unified Infrastructure Operating System built from a single codebase—an architecture designed for scale from the ground up.
Layers Create Infrastructure Software Limits
Most vendors integrate components through APIs. This approach to software limits infrastructure scale by creating constant north-south traffic inside each node (communication between software layers) and east-west traffic across the cluster (coordination between nodes). Each module—hypervisor, storage, networking—maintains its own metadata structures. The result is inefficiency, synchronization lag, and exponential coordination overhead as clusters grow.
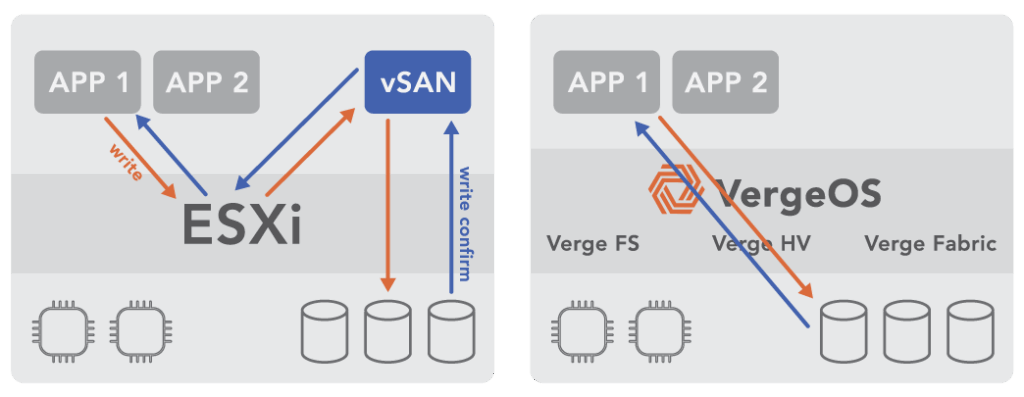
In VMware, a single VM I/O request traverses multiple independent software layers. ESXi receives the I/O request. The request passes through vSAN APIs for storage operations. NSX handles network translation. Each hop adds CPU overhead, I/O latency, and metadata synchronization. At 10 nodes, this overhead is measurable. At 20 nodes, it’s significant. At 30 nodes, it becomes crippling.
Solving Infrastructure Software Limits: A Single Codebase
True scalability requires eliminating architectural friction before it compounds. The prerequisite for efficiency, performance, and predictability at scale is a single codebase in which all infrastructure components share the same metadata layer, scheduler, task engine, and control plane.
The difference between architectures is almost invisible at the small scale. With a few nodes, even inefficient designs appear fast. The fundamental distinction emerges when infrastructure grows to six or more nodes. At this, still relatively small node count, the number of inter-module communications multiplies exponentially.
VergeOS Eliminates Infrastructure Software Limits

VergeOS executes within one unified software context. Compute, storage, and networking operations access shared data structures and are managed through the same control plane. A VM performing storage I/O makes a direct call to shared infrastructure services without API translation or separate metadata lookups. The result is 40-60% better storage performance versus VMware with vSAN, lower resource utilization, and linear scalability without introducing coordination overhead.
This architectural difference manifests as the number of nodes per instance increases. Practically speaking, VMware vSAN clusters max out at about 64 nodes, with performance degradation starting at 32. Nutanix recommends 32-48 nodes per cluster, requiring multiple clusters for larger environments. VergeOS scales linearly to 100+ nodes in a single instance with consistent performance.
Complete Infrastructure Services in One Platform
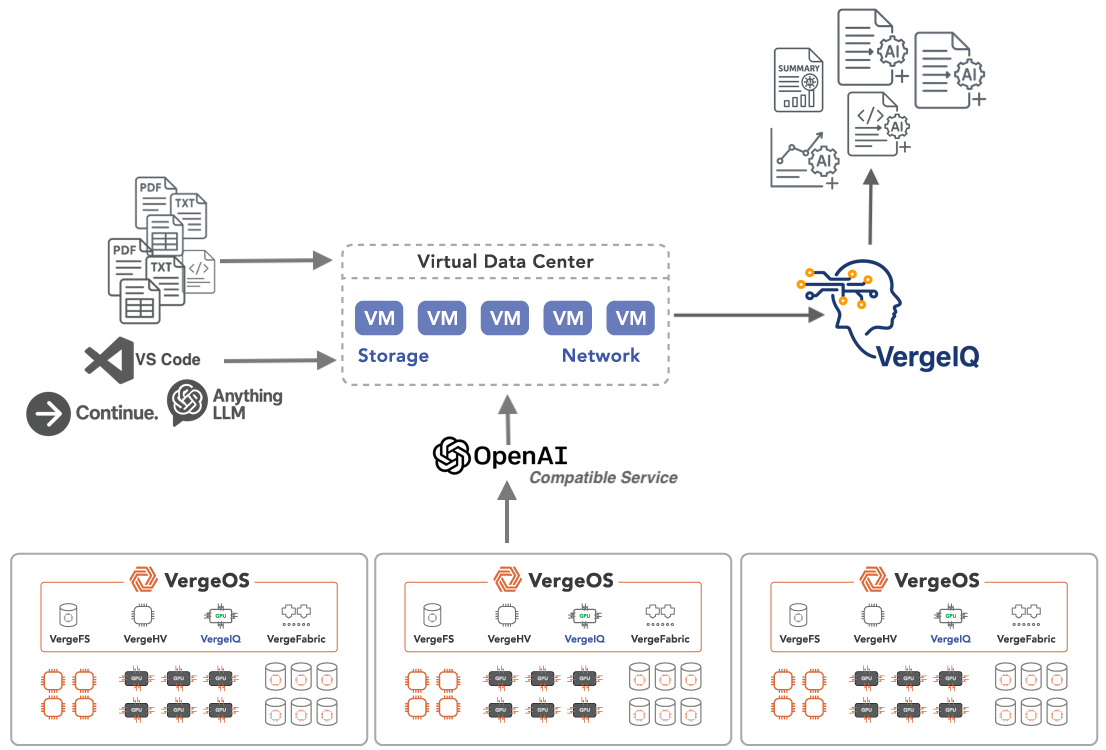
When a new workload or application becomes a new requirement for an organization, like AI is becoming today, Legacy software limits infrastructure scale by forcing organizations to deploy new infrastructure silos. In VergeOS, it’s just another service inside the same operating system. A true Infrastructure OS integrates virtualization, networking, storage, data protection, and AI into one platform. It is also ready to integrate the next popular workload when the time is right.
Legacy software limits infrastructure scale because of its design philosophy. VMware and Nutanix achieve functionality through stitched-together binaries. VergeOS achieves it through a unified architecture. Shared logic means no translation between modules and no management-plane silos.
In VergeOS, these services are native, not layered. Networking provides integrated routing and security without NSX-style overlays. Storage delivers global inline deduplication and instant immutable snapshots as core functions, not external components. Data protection offers immutable, near-instant recovery without copying data to secondary systems. AI provides GPU pooling, vGPU sharing, and integrated inference (VergeIQ) with the same resource management as CPU and memory—not deployed as a bolt-on Kubernetes cluster or cloud service requiring separate infrastructure.
When a VM writes data in VergeOS, that write operation deduplicates, replicates, and protects data in a single pass. In VMware, vSAN handles storage, NSX handles networking, and a separate backup product handles protection. Three separate operations with three separate metadata updates. This difference becomes more pronounced at scale.
Virtual Data Centers and Infrastructure-Wide Tagging
Virtual Data Centers (VDCs) form the architectural key to scaling tenants, departments, or workloads. Each VDC acts as a fully isolated tenant environment, including its own compute, storage, and networking—all managed from within VergeOS. VMware achieves multi-tenancy through separate clusters and NSX overlays. VergeOS achieves it natively, without extra hardware or complexity.
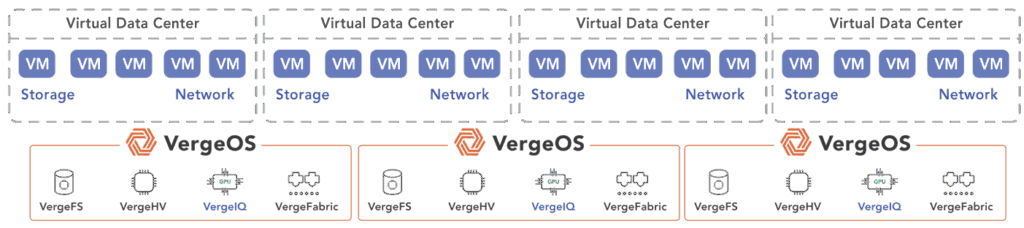
VDCs are elastic, expanding resources without reconfiguration or redeployment. They are portable, allowing instant cloning, migration, or replication of entire environments. They are isolated, enforcing security and performance policies at the tenant level without separate management tools. A single VergeOS cluster can host hundreds of VDCs, each with complete tenant isolation and QoS boundaries that prevent noisy neighbor problems.
MSPs use VDCs to host customers. Enterprises use them to separate production, development, and DR environments. Cloud providers use them to differentiate service tiers. VDCs can be nested, enabling hierarchical tenant structures that mirror business organization—customer, department, team.
Infrastructure-wide tagging extends this organizational model into policy enforcement. VMware tags describe what something is. VergeOS tags define what it does. Tags apply across all layers—nodes, networks, VDCs, and storage objects. A VM tagged “Gold” can have actions taken on it, such as 15-minute immutable snapshots, replication to the DR site, a high-performance storage tier, and priority network QoS.
This becomes critical at scale. Managing 1,000 VMs manually is possible. Managing 10,000 without automation is not. Infrastructure-wide tagging makes 10,000 VMs as manageable as 100. Instead of configuring policies for thousands of VMs individually, tag 10 VDC environments.
Scale Needs Integration, Not Integration Projects
Another way legacy software limits infrastructure scale is by failing to integrate with existing automation and observability tools. Scalability depends on open integration with modern automation and observability tools, not on proprietary APIs or management stacks. VergeOS integrates natively with Terraform and Prometheus, enabling seamless integration into modern DevOps pipelines.
Terraform provides infrastructure-as-code provisioning, scaling, and lifecycle management. A single script can provision an entire multi-tenant environment—VDC creation, network configuration, VM deployment, storage policy assignment, and monitoring setup—in minutes, with full idempotency and version control. Prometheus delivers cluster-wide visibility into performance, I/O, latency, and deduplication metrics without additional agents.
VMware’s PowerCLI requires separate scripting for vSAN, NSX, and vCenter. VergeOS provides one unified API. Open integration means organizations scale operations as easily as they scale compute. Integration should expand capability, not maintenance. Terraform and Prometheus make VergeOS part of the automation ecosystem, not another island of management.
The Cost of Infrastructure Software Limits
VMware operates as independent products linked through APIs. ESXi, vSAN, NSX, and vCenter each add their own control plane and data structures. Nutanix combines AHV, AOS, Flow and Prism Central, which still operate as separate binaries under a common management GUI.
Each layer introduces multiple metadata stores and redundancy, network traffic for synchronization (east-west), and inter-process overhead within the node (north-south). As environments grow, these coordination costs rise exponentially, limiting scalability. At 50 nodes, VMware requires 50x ESXi licenses, 50x vSAN licenses, NSX licenses (if used), vCenter licenses, and a separate backup product. VergeOS requires one platform license covering all functionality.
The hidden tax of architectural complexity extends beyond licensing. Management overhead requires separate teams for compute, storage, and networking. Every additional product requires its own specialists, its own upgrade schedule, and its own failure domain. VergeOS eliminates these barriers, and performance remains consistent as nodes scale linearly.
Proving Infrastructure Software Limits Don’t Exist
Most vendors demo scalability with small clusters. Test the following scenarios across any infrastructure platform to determine whether the software limits infrastructure scale. Add 10 nodes back-to-back and measure time and performance impact. Create 1,000 VMs across the cluster and measure provisioning time. Simulate node failure and measure failover time, data protection, and data exposure windows. Run mixed workloads—database, VDI, AI inference—and measure resource contention.
VergeOS customers regularly run these tests during proof-of-concept evaluations. The results speak to architectural differences. VergeOS represents the next step in infrastructure evolution—an operating system built for scale itself.
You can scale nodes or scale architecture. Only an Infrastructure Operating System lets you do both—without compromise, without complexity, and without limits.
Don’t Settle for Infrastructure Software Limits
Legacy software limits infrastructure scale, not hardware. Software fails because of fragmented software. Fragmented software is why most infrastructure modernization projects end up with the same problems as the architecture they replace.
VergeOS solves that by collapsing all infrastructure functions into a single codebase that eliminates internal traffic, metadata duplication, and management silos. It scales infrastructure and operations — delivering the simplicity hyperscale demands.

