Infrastructure-wide deduplication expands what IT professionals know about deduplication, a storage feature that saves disk space. Arrays deduplicate blocks, backup systems compress datasets, and WAN optimizers reduce transmission overhead. Each system handles deduplication independently, creating islands of efficiency in an already fragmented infrastructure.
Infrastructure-wide deduplication takes a fundamentally different approach. Instead of treating deduplication as separate features scattered across various systems, it implements deduplication as a unified capability that spans the entire infrastructure—storage, virtualization, networking, and data protection—under a single, consistent framework.
The Problem with Fragmented Deduplication
Traditional deduplication creates a cycle of inefficiency. Data may start deduplicated in primary storage, expand to full size during backup operations, then deduplicate again in the backup appliance using different algorithms. For disaster recovery, the same data rehydrates before replication, deduplicates for transmission, expands again at the destination, and deduplicates once more on DR storage.
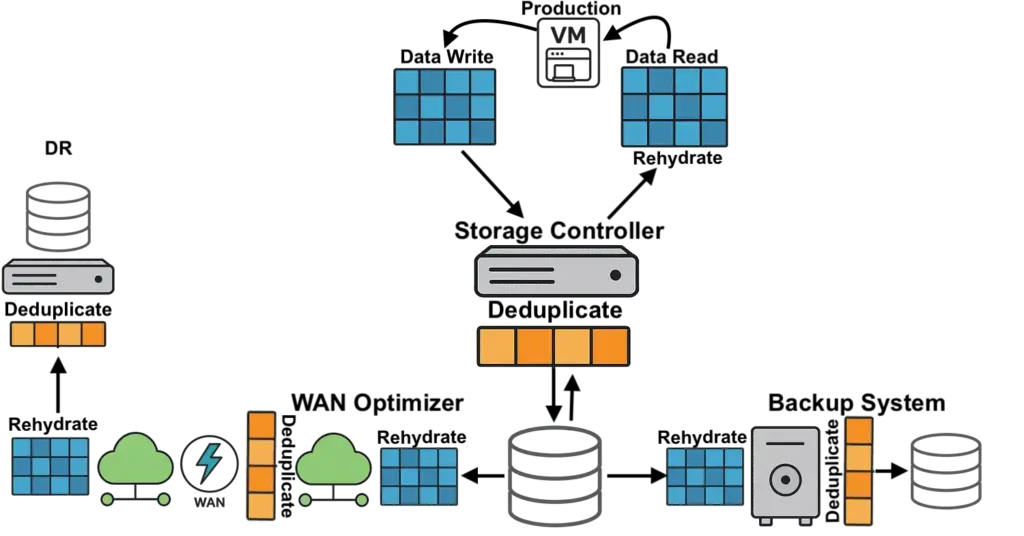
This fragmentation forces organizations to deploy 30–50% more CPU and RAM than workloads otherwise require to absorb the overhead of constant rehydration and re-deduplication. WAN circuits carry redundant data streams. Backup windows extend as data repeatedly expands and contracts. IT teams assume they have comprehensive deduplication coverage, but in reality, they are paying a hidden tax across every system boundary.
Understanding these inefficiencies—and the architectural approaches that eliminate them—requires examining how different vendors implement deduplication across their platforms. Our white paper “Building Infrastructure on Integrated Deduplication” provides a detailed analysis of implementation patterns from bolt-on approaches to native integration, plus vendor-specific guidance on Unity, vSAN, Nutanix, Pure, and VergeOS platforms. Get the complete analysis at verge.io/building-infrastructure-on-integrated-deduplication.
How Infrastructure-Wide Deduplication Works
Infrastructure-wide deduplication eliminates these inefficiencies through three key principles:
Native Integration. Rather than bolting deduplication onto existing systems, it’s built into the platform from the earliest lines of code. Deduplication becomes part of the core infrastructure operating system, not a separate process competing for resources.
Unified Metadata. Instead of each system maintaining its own deduplication tables, infrastructure-wide implementations use a single, consistent metadata model. A block deduplicated in New York remains deduplicated when referenced in London or Tokyo. Data never loses its optimized state as it moves between functions or sites.
Cross-Layer Operation. Deduplication runs simultaneously across storage, virtualization, and network layers. When the hypervisor makes deduplication decisions, they directly inform storage operations. Network transfers automatically leverage existing deduplication metadata without redundant processing cycles.
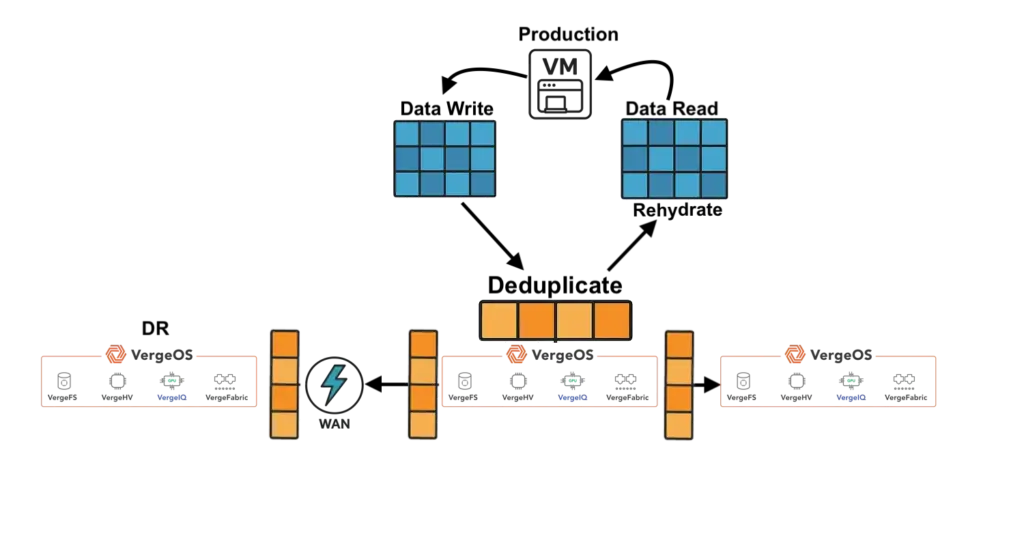
This cross-layer integration has practical consequences. For example, when a virtual machine snapshot is taken, the hypervisor references existing deduplicated blocks instead of writing new ones. That reduces both I/O and backup times. Similarly, when replication jobs run, they automatically leverage deduplication tables maintained across the entire infrastructure, eliminating duplicate transfers without additional processing.
The VergeOS Implementation
VergeOS demonstrates this approach through its Infrastructure Operating System. Instead of separate storage, virtualization, and networking products that require integration, VergeOS provides a unified platform where deduplication operates across all infrastructure functions.
When a virtual machine writes data, the hypervisor immediately deduplicates at the source. Storage operations work with the optimized dataset. Network replication transmits unique blocks. Backup operations reference existing deduplicated blocks rather than creating new copies. Recovery uses the same optimized structure, eliminating expansion penalties.
This architectural integration explains why infrastructure-wide deduplication remains rare. Other vendors build platforms around separate components. Retrofitting unified deduplication requires redesigning core architectures rather than adding features—a significant undertaking that few vendors attempt. VergeOS avoids this problem by collapsing the stack into one code base where deduplication is built in, not bolted on. Deduplication becomes a key element in the VergeOS architecture.
Measurable Infrastructure-wide Deduplication Benefits
Infrastructure-wide deduplication delivers improvements that compound across the entire infrastructure:
Performance. By operating on deduplicated datasets from the start, I/O operations decrease by 40–60%. Cache hit rates improve by 2–3x because the working dataset is fundamentally smaller. Applications experience lower latency and higher throughput.
Resource Efficiency. Organizations can right-size servers based on actual workload requirements rather than deduplication overhead. Memory utilization improves because duplicate data never enters the cache hierarchy.
WAN Optimization. Only unique blocks traverse the network, reducing replication traffic by 70–90%. Organizations can handle more data on existing circuits or reduce bandwidth costs while maintaining protection levels.
Operational Simplicity. Backup windows shrink by 60–80% because data doesn’t rehydrate during protection operations. Snapshots become instant references to deduplicated blocks. Recovery operations are complete 5–10x faster using the same optimized block structure.
Multi-Site Flexibility. With consistent deduplication across locations, entire data centers can migrate between continents with minimal data transfer. AI training checkpoints that previously required hours to replicate are now completed in minutes.
Use Case Spotlights
VMware Exits. Organizations moving away from VMware face major infrastructure transitions. Infrastructure-wide deduplication offsets migration costs by reducing hardware requirements and enabling faster workload mobility.
AI/ML Pipelines. Training large language models generates terabytes of repetitive checkpoint data. Infrastructure-wide deduplication reduces replication from hours to minutes, enabling faster iteration and lower infrastructure cost.
Disaster Recovery Compliance. Meeting aggressive recovery time objectives (RTOs) requires restoring systems quickly. Infrastructure-wide deduplication cuts recovery times by up to 5–10x, helping organizations meet compliance and business continuity mandates.
Competitive Landscape
Not all deduplication is created equal. Broadly, vendors take one of three approaches:
- Bolt-On: Deduplication is a separate process layered onto existing systems. It introduces overhead, requires additional metadata, and forces rehydration between steps.
- Integrated Later: Deduplication was added to the platform after launch. Better than bolt-on, but still scoped to clusters or volumes rather than spanning the entire stack.
- Array-Native: Vendors like Pure Storage offer always-on deduplication, but it starts once data hits the array. CPU, RAM, and WAN costs remain untouched.
- Infrastructure-Wide: Platforms like VergeOS embed deduplication across storage, compute, and networking in a unified architecture, eliminating silos and preserving deduplication across the entire lifecycle of the data.
When Infrastructure-wide deduplication Matters
Infrastructure-wide deduplication becomes strategically relevant during periods of infrastructure change. Organizations evaluating VMware alternatives should reconsider their entire technology stack. AI workloads generate massive repetitive datasets that storage-specific deduplication handles poorly. Budget pressures make the 30–50% resource overhead of fragmented approaches increasingly difficult to justify, and fragmented deduplication is a key component of the AFA Tax.
The question for IT leaders isn’t whether deduplication works—it’s where it works and how broadly its benefits extend. Infrastructure-wide deduplication transforms a commodity storage feature into a competitive strategic advantage that improves performance, reduces costs, and enables new operational patterns.
Looking Ahead
As infrastructures evolve toward ultraconverged, AI-ready, and private-cloud designs, deduplication will become more than an efficiency tool. It will serve as a foundation for agility, enabling IT to scale workloads globally, replicate AI datasets instantly, and deliver faster recovery from outages.
Rather than accepting the inefficiencies of fragmented deduplication, organizations can adopt infrastructure-wide approaches that optimize the entire stack. The technology exists, the business case is clear, and the timing—with widespread infrastructure reevaluations underway—is ideal.
Ready to eliminate the deduplication tax?
[ Schedule a Whiteboard Technical Deepdive ] [ Download The White Paper ]

