Deduplication and RAM cache are two of the most critical technologies in modern IT infrastructure. Both are designed to improve efficiency and performance, but in storage-centric designs, they often work against each other. Deduplication reduces the amount of data that must be stored and transmitted, while cache accelerates access to frequently used data. The problem is that the way these features are typically implemented causes them to clash.
The effectiveness of cache depends on the location. When cache sits inside the server hosting the VM, it is directly alongside the application and delivers immediate performance benefits. When cache resides in a shared storage system connected over the network, its value is far less meaningful. From the application’s perspective, there is little difference between retrieving a block from the array’s cache and retrieving it from the array’s flash drives—both require a network hop.
Deduplication complicates this further. Before cached data can be sent from the storage system, it must often be rehydrated. This process eliminates much of the performance advantage that cache is supposed to provide.
Infrastructure-wide deduplication changes the deduplication and RAM cache dynamics. By sharing metadata across storage, virtualization, and networking layers, it ensures that deduplication and cache work together rather than in opposition. Cache remains in the right place—next to the VM—while data stays deduplicated until the moment it is consumed. For a deeper explanation of this concept, see the blog What Is Infrastructure-Wide Deduplication.
The Role of RAM Cache Today
RAM cache is one of the most powerful tools available for improving application performance. Because it operates at memory speeds, it delivers far lower latency than even the fastest flash storage. Modern workloads—including databases, analytics platforms, and AI/ML pipelines—depend on cache to meet user and business expectations for responsiveness.
But the effectiveness of cache is determined by its placement. Cache inside the server hosting the VM eliminates unnecessary trips across the network, delivering measurable and consistent benefits.
By contrast, cache located inside a shared storage system provides limited value. Retrieving a block from the storage array’s cache is not much different than retrieving it from the array’s SSD tier—both require a network hop. Worse, storage-centric deduplication forces cached data to be rehydrated before transmission, erasing the supposed advantage of having the block in cache at all.
The result is a gap between what cache should provide and what it actually delivers. As applications grow more cache-dependent, that gap widens, exposing the shortcomings of architectures that treat deduplication and cache as isolated features rather than complementary technologies.
How Storage-Centric Deduplication Undermines RAM Cache
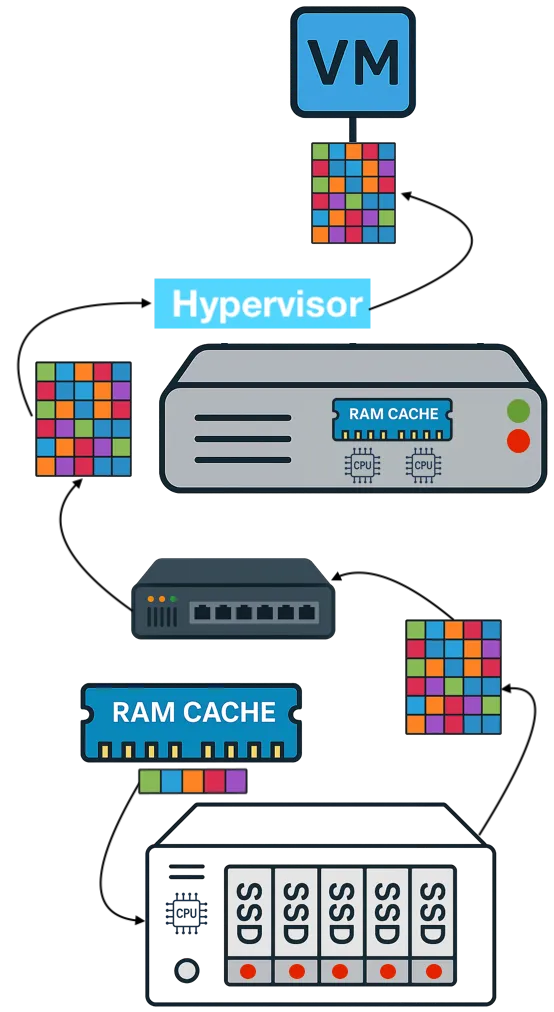
All-Flash Array vendors promote deduplication as a space-saving feature of their arrays. In theory, deduplication and RAM cache should complement each other; the smaller the dataset, the more effective the cache. In practice, the opposite occurs.
Deduplicated blocks inside an array must be rehydrated before they can be transmitted across the network to the VM. This means that even when a cache hit occurs, the system spends CPU cycles rebuilding the block before it can leave the array. The benefit of the cache hit is diminished, and the VM receives the data with little to no latency improvement.
From the application’s perspective, this creates an illusion of acceleration. The array may report cache efficiency, but because rehydration is required, the VM experiences almost the same delay it would if the block were read directly from flash. Customers end up buying expensive all-flash arrays with large caches that deliver almost no practical benefit to the workloads they are supposed to accelerate. This problem is explored further in AFA Deduplication vs vSAN, which highlights the compromises of storage-centric deduplication approaches.
This is not just a performance issue—it is a resource issue. Rehydration consumes CPU and memory resources in the storage system, forcing organizations to overprovision those resources just to keep workloads running. The result is higher cost, wasted infrastructure, and inconsistent performance.
Infrastructure-Wide Deduplication: The Metadata Advantage
The key to making deduplication and RAM cache work together is eliminating the need for rehydration until the very last step—when the data is delivered to the VM. This is possible only when deduplication metadata is shared across the entire infrastructure, rather than being locked inside a storage array.
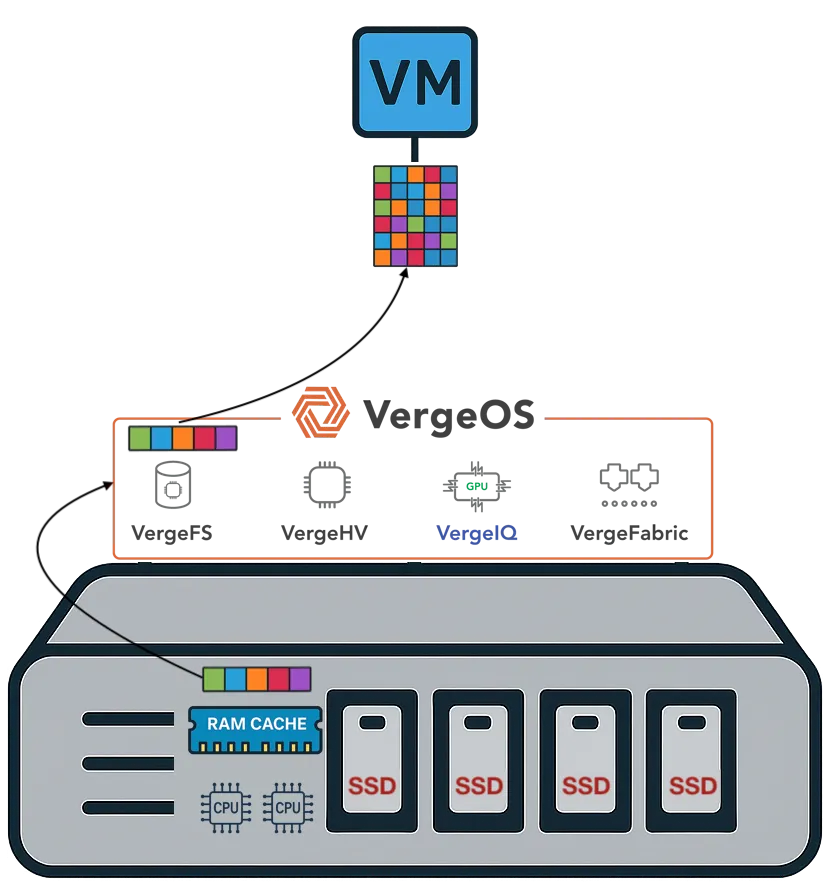
With infrastructure-wide deduplication, VergeOS maintains a single, global metadata structure that spans storage, virtualization, and networking. This ensures that data can remain deduplicated as it moves through the system. Blocks do not need to be reassembled or expanded in the storage system before traveling across the network. Instead, they stay in their deduplicated form until consumed by the VM or application.
This shift has a direct impact on cache strategy. Cache no longer needs to sit inside the storage system, where rehydration undermines its value. Instead, cache can be placed where it matters most—in the server, right next to the workload. By maintaining consistent deduplication awareness across all layers, cached blocks remain optimized and deliver real performance benefits without the overhead of premature rehydration.
In practice, this often improves effective cache hit rates by a factor of four to five compared to array-side caching, because server-side cache is no longer wasted storing redundant blocks. Applications see faster response times, more consistently low latency, and higher resource utilization efficiency.
Comparing Storage-Centric vs. Infrastructure-Wide Approaches
| Feature / Impact | Storage-Centric Deduplication + Cache | Infrastructure-Wide Deduplication + Cache |
|---|---|---|
| Cache Location | Inside storage array, across network | Inside server, next to VM |
| Rehydration Requirement | Before transmission, even from cache | Only at VM, at point of use |
| Effective Cache Hit Rate | Low, due to redundant blocks + rehydration | 4–5x higher, dedupe shrinks working set |
| Latency Improvement | Minimal (network hop and rehydration erases benefit) | Significant (direct from RAM cache to VM) |
| Resource Overhead | High CPU/RAM in array for rehydration | Lower overhead, fewer wasted cycles |
| Business Value Delivered | Efficiency for the array vendor | Efficiency and performance for the business |
The Deduplication and RAM cache Takeaway
Deduplication and RAM cache are both essential to modern infrastructure, but in storage-centric designs, they often work at cross purposes. Deduplication reduces storage requirements but forces rehydration, undermining cache. Storage-system caches sit on the far side of the network and provide little practical benefit to the applications that need them most.
Infrastructure-wide deduplication resolves this conflict. By sharing metadata across storage, virtualization, and networking, data remains deduplicated until the VM consumes it. Cache can be located directly in the server, where it accelerates workloads without the penalty of premature rehydration. Instead of competing for resources, deduplication and cache reinforce one another—smaller datasets, higher cache hit rates, and faster, more consistent application performance.

The distinction is clear. Storage deduplication and cache create efficiency for the array. Infrastructure-wide deduplication and cache create efficiency for the business—delivering responsiveness, reducing costs, and scaling with modern workloads like AI, analytics, and VDI that storage-centric models struggle to support. For a broader discussion of why deduplication must evolve, download the white paper Building Infrastructure on Integrated Deduplication.

