The supply of RAM and flash storage is not keeping up with demand. The shortage is driving prices higher and pushing delivery times out by months. According to an SK Hynix internal analysis, high prices and constrained supply are expected to continue through at least 2028. For IT planners already facing the rising cost of VMware licensing and looking for a VMware alternative, the timing is brutal. The solution is to consolidate VMs onto fewer hosts, but then IT needs to account for the hidden risk of VM Density, the blast radius.
Key Takeaways
- RAM and flash supply constraints are expected to last through at least 2028. Reducing protection levels to offset rising prices puts data at risk during the period when that data is most valuable.
- VM consolidation saves money but increases blast radius. When a dense host fails, it takes more VMs, more CPU, more memory, and more storage offline simultaneously than a traditional environment.
- ioOptimize uses AI to proactively migrate workloads off degrading servers before failure and intelligently redistribute displaced VMs across surviving hosts based on actual resource demands.
- RF2 mirrored redundancy and ioGuardian work together to extend protection from N+1 to N+2 without the performance overhead of RAID 6 or erasure coding.
- Integrated replication and virtual data centers turn the DR site into an active protection layer, with cross-site ioGuardian recovery and full application stack failover in minutes.
- RF3 triple mirroring, new in VergeOS 26.1, combined with ioGuardian delivers N+X availability where data remains accessible as long as one production server and the repair server are running.
- VergeOS’s layered protection architecture scales with density, letting organizations capture the full cost savings of VM consolidation without accepting the availability risk that density traditionally creates.
If the risks of VM density can be contained or eliminated, the return on investment from increasing VM density is significant under normal market conditions. During a memory and flash supercycle, it becomes a strategic imperative.
Key Terms
- Blast Radius — The scope of operational impact caused by a single failure event. In dense environments, one server going offline removes more VMs, CPU, memory, and storage from the cluster simultaneously.
- VM Consolidation — The practice of running more virtual machines per physical host to reduce hardware costs, power, cooling, and data center footprint.
- ioOptimize — VergeOS technology that uses AI and machine learning to balance workloads across mixed-generation servers, proactively migrate VMs off degrading hardware, and intelligently redistribute displaced VMs during failures.
- RF2 Mirrored Redundancy — N+1 data protection that maintains two copies of every data block on separate fault domains. Provides fast rebuilds through direct block copies rather than parity reconstruction.
- ioGuardian — A dedicated VergeOS instance that holds a protected third copy of data and provides inline VM recovery during failures. Extends protection from N+1 to N+2 without hosting production workloads.
- RF3 Triple Mirroring — N+2 data protection new in VergeOS 26.1 that maintains three complete copies of every data block. Combined with ioGuardian, it delivers N+X availability.
- N+X Availability — Protection level achieved by combining mirroring with an ioGuardian repair server. Data remains accessible as long as one production server and the repair server are running, without reaching for backups.
- Virtual Data Centers — VergeOS technology that encapsulates entire application stacks for rapid failover to a remote site in minutes, without VM-by-VM configuration at the DR site.
- Granular Replication — New in VergeOS 26.1, the ability to replicate specific workloads or data sets rather than replicating everything, reducing WAN bandwidth consumption and giving finer control over cross-site protection.
The ROI of VM Density
Every server removed from the environment eliminates its share of RAM, flash, power, cooling, licensing, and rack space costs. VergeOS customers who reduce server count by 25% do not just save on the servers themselves. They avoid purchasing RAM and NVMe drives for those servers at supercycle pricing. A four-server reduction in a 16-server cluster removes roughly 25% of the organization’s exposure to price increases in memory and flash in a single move.
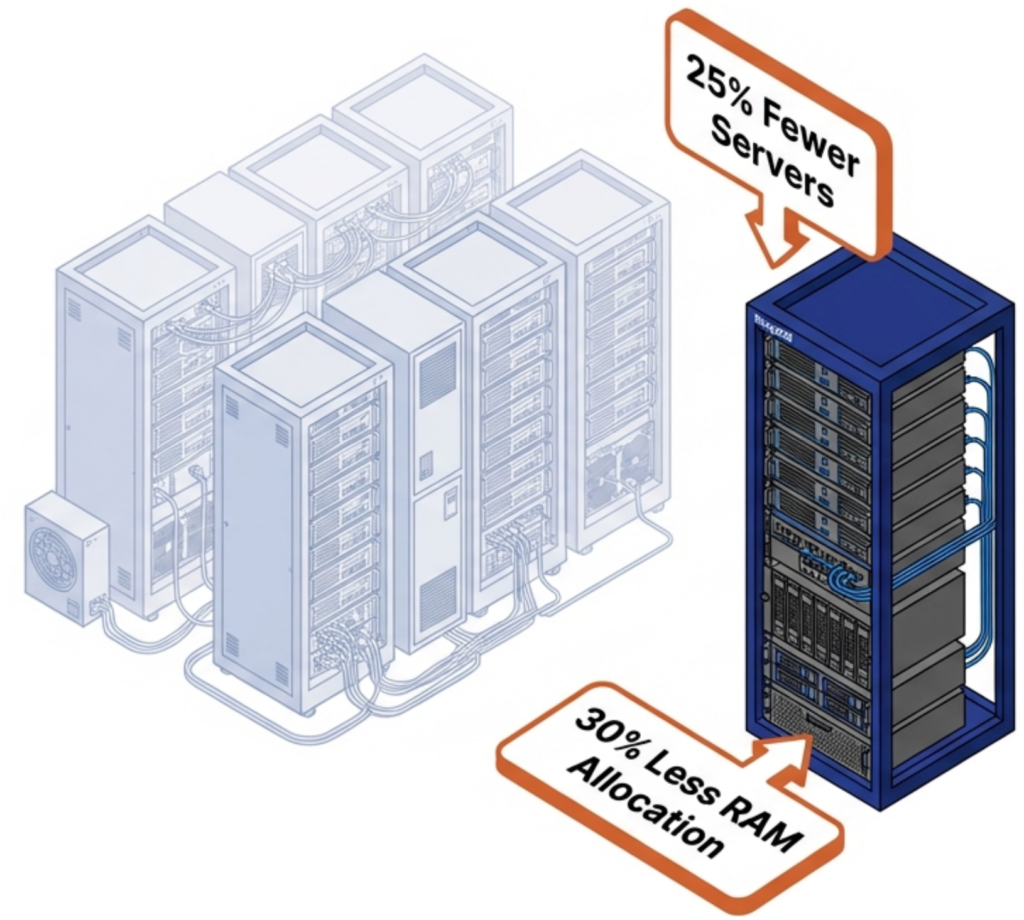
The 30% reduction in per-VM memory allotment compounds the savings. A VM that required 16GB of RAM under VMware runs on 11GB under VergeOS. Multiply that savings across hundreds of VMs, and the organization reclaims terabytes of RAM capacity that it no longer needs to purchase, license, or replace at inflated prices. That reclaimed capacity either extends the life of existing hardware or reduces the bill of materials on the next refresh.
The combined effect is fewer servers, less memory per VM, and commodity drives instead of vendor-priced components. Organizations that achieve this level of consolidation spend less on infrastructure during the supercycle while maintaining or increasing their total workload capacity. The ROI is clear. The question is whether the protection architecture can keep pace with the density. That is the blast radius problem.
The VM Density Blast Radius Problem
Higher VM density means more VMs per host and more storage capacity inside each host. With modern hardware, the odds of a server or SSD drive failure are low. The odds of a second or third simultaneous failure are even lower. The real concern is the blast radius, meaning how much of the operation a single failure impacts.
When a host running 40 VMs goes offline, it does not just remove drives from the storage pool. It removes 40 running workloads, along with their CPU, memory, and network connections. The surviving hosts absorb the displaced VMs on top of their existing workloads and any storage rebuild I/O. A workload spike on a dense host creates a ripple effect, forcing resource contention across the cluster and degrading performance for every VM, not just the one experiencing the spike.
Traditional infrastructure spreads this risk across more physical servers, with fewer VMs per server. VM density concentrates it. The savings from higher density are real, but only if the protection architecture accounts for the larger blast radius.
How VergeOS Protects VM Dense Environments
VergeOS addresses the VM density blast radius with a layered protection architecture. Each layer targets a different failure scenario, from early degradation warnings to complete site loss.
ioOptimize uses AI and machine learning to continuously monitor the health, performance, and capacity of every server in the environment. Its algorithms distribute workloads based on each server’s actual capabilities, assigning lighter tasks to aging hardware and directing demanding workloads to newer servers. This intelligent placement lets organizations run mixed-generation environments without prematurely retiring older servers. The scale-down capability goes further, consolidating VMs and storage onto denser configurations to reduce power, cooling, and physical footprint. The result is fewer servers doing more work, which directly reduces the hardware exposed to the memory and flash supercycle pricing.
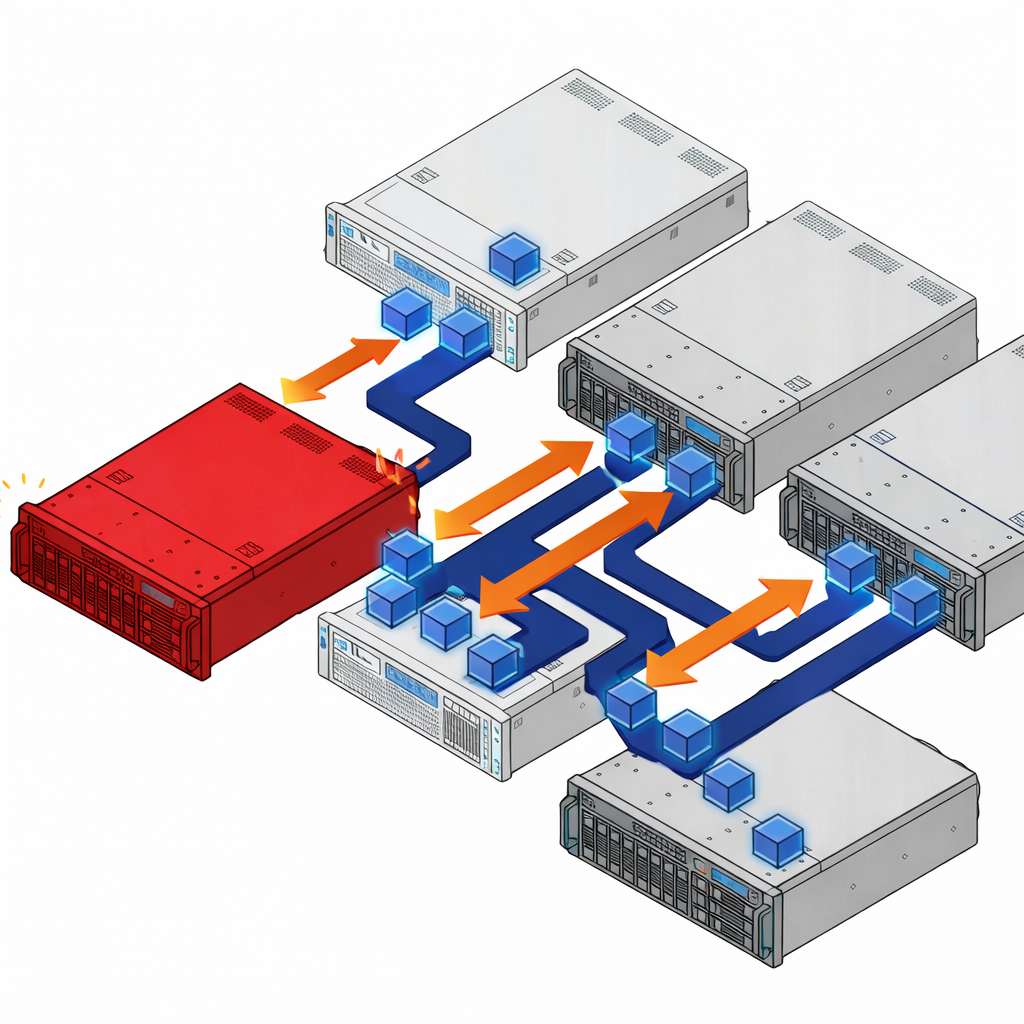
ioOptimize also changes how the cluster responds to server failures. It monitors for early indicators of degradation and proactively migrates workloads off at-risk servers before a hard failure occurs. When a server does fail unexpectedly, ioOptimize evaluates the resource demands of each displaced VM and matches them against available capacity on the surviving hosts. Instead of dumping 40 VMs onto the nearest available server and creating a new hotspot, it distributes them based on actual CPU, memory, and I/O requirements. That intelligent redistribution keeps the blast radius contained and prevents a single failure from cascading into a cluster-wide performance problem.
RF2 Mirrored Redundancy keeps two copies of every data block on separate fault domains. When a drive or server fails, the surviving copy handles all requests without degrading performance. Rebuilds are fast because the process copies intact blocks directly from the surviving mirror rather than reconstructing data from parity calculations.
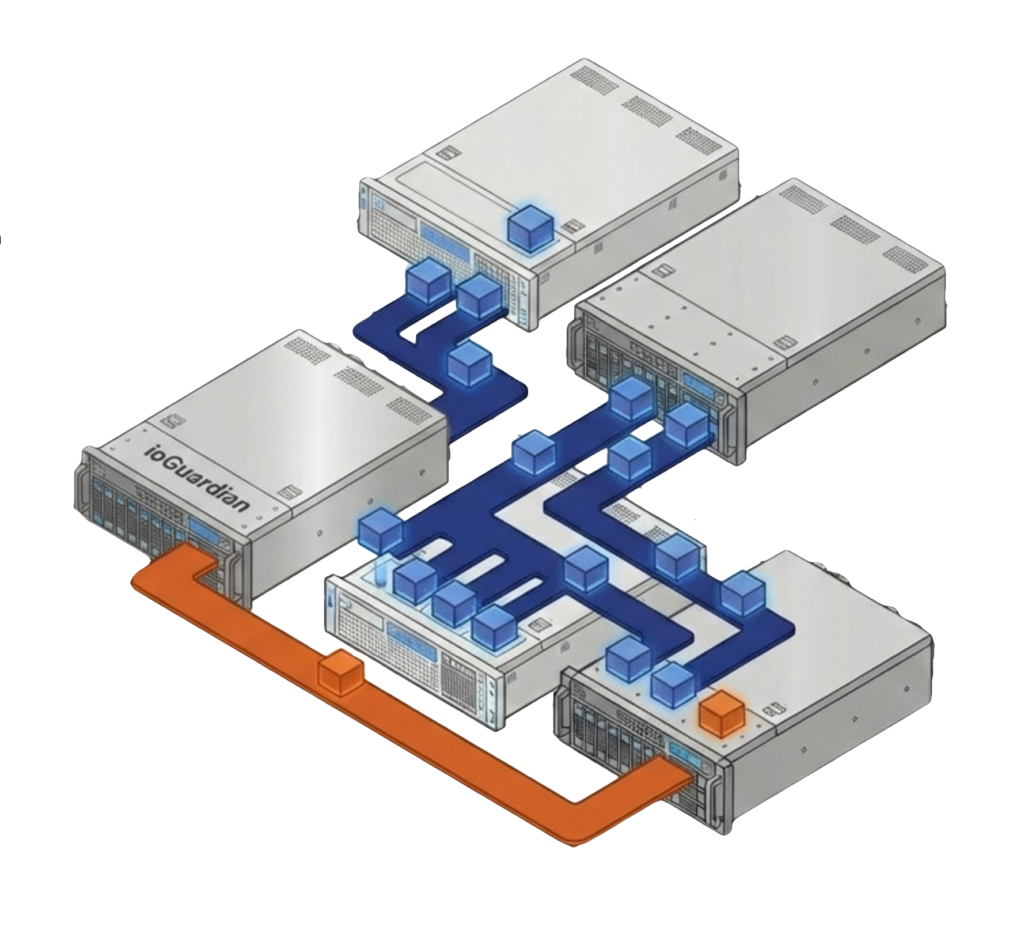
ioGuardian maintains a protected third copy of data on a separate VergeOS instance that can provide inline recovery of VMs. The ioGuardian server does not host production workloads. Its dedicated role is to feed missing data blocks back to the production environment during failures, keeping production hosts focused on running VMs rather than diverting resources to data reconstruction. This extends protection from N+1 to N+2 without adding the performance overhead of RAID 6 or erasure coding.
ioReplicate sends both production data and ioGuardian data to a remote site. If the primary site’s ioGuardian instance fails at the same time as a production failure, the ioGuardian at the DR site can still perform inline recovery to the production cluster at the primary site. This cross-site protection layer covers failure scenarios that no single-site architecture can address.
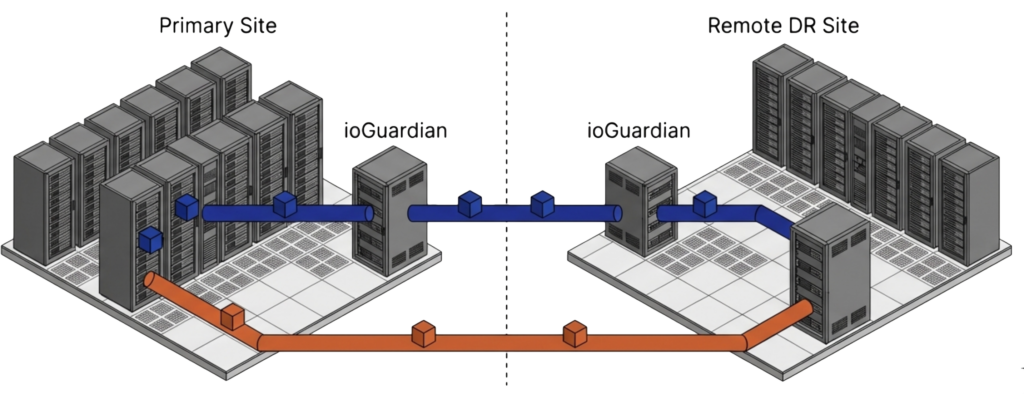
Virtual Data Centers make recovery at the remote site straightforward when the primary site fails completely. Entire application stacks restart at the DR site in minutes, not hours. The encapsulation of full workload environments means the DR site does not need to be configured VM by VM.
VergeOS 26.1 Strengthens the Protection Stack
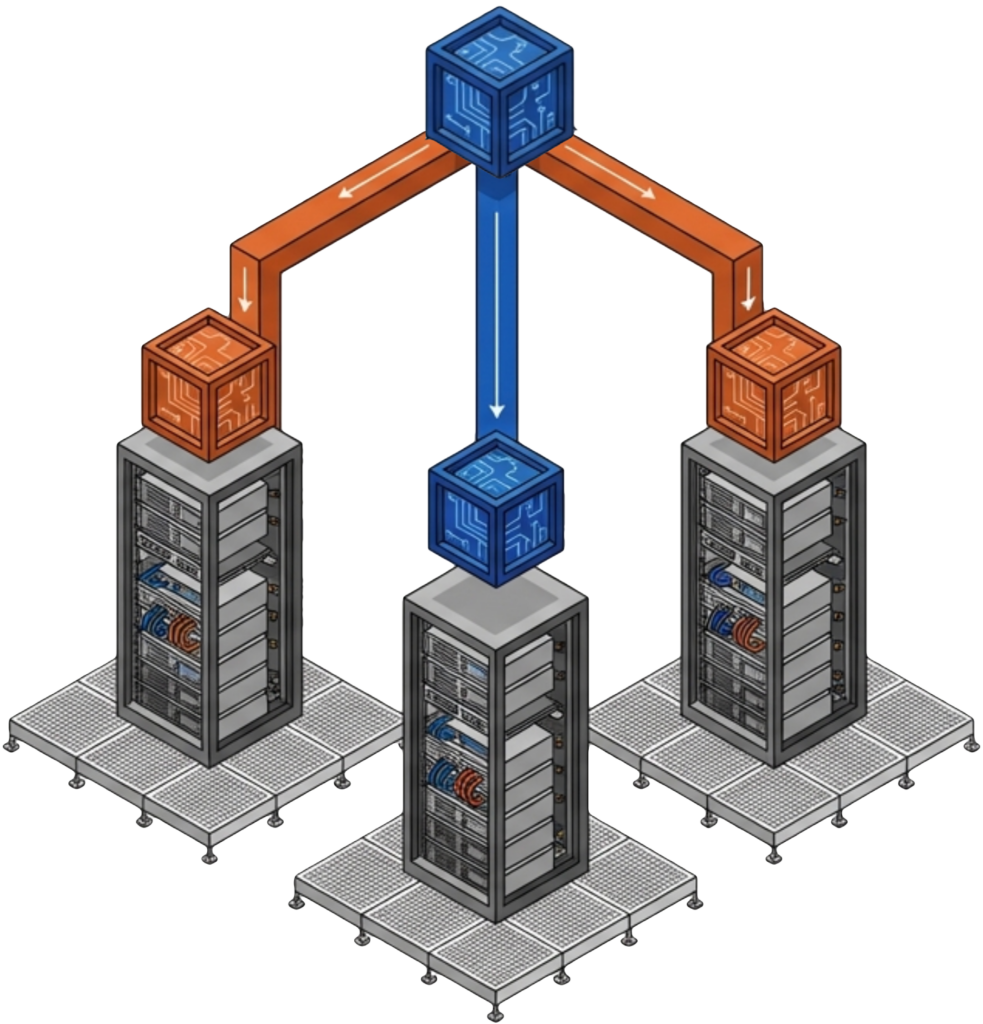
RF3 Triple Mirroring, new in VergeOS 26.1, provides N+2 availability for organizations that demand maximum protection. Three complete copies of every data block mean two simultaneous failures cause zero data loss and near-zero performance impact. When combined with ioGuardian, RF3 enables the environment to reach N+X availability, where data remains accessible as long as one production server and the repair server are running.
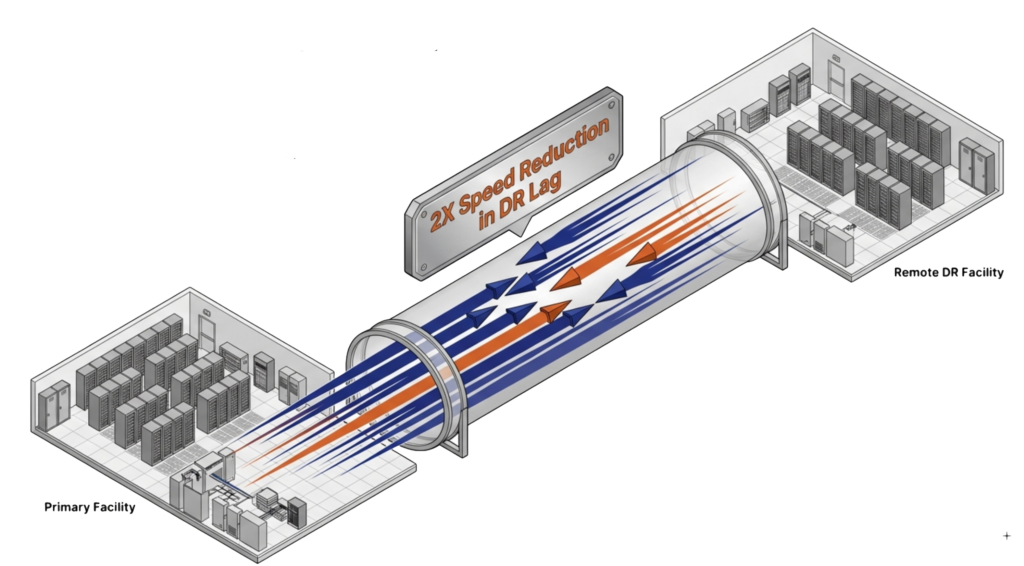
VergeOS 26.1 increases replication performance by 2x, cutting the time required to synchronize data between sites. Faster replication narrows the window where the DR site lags behind the primary, reducing the amount of data at risk during a site-level failure.
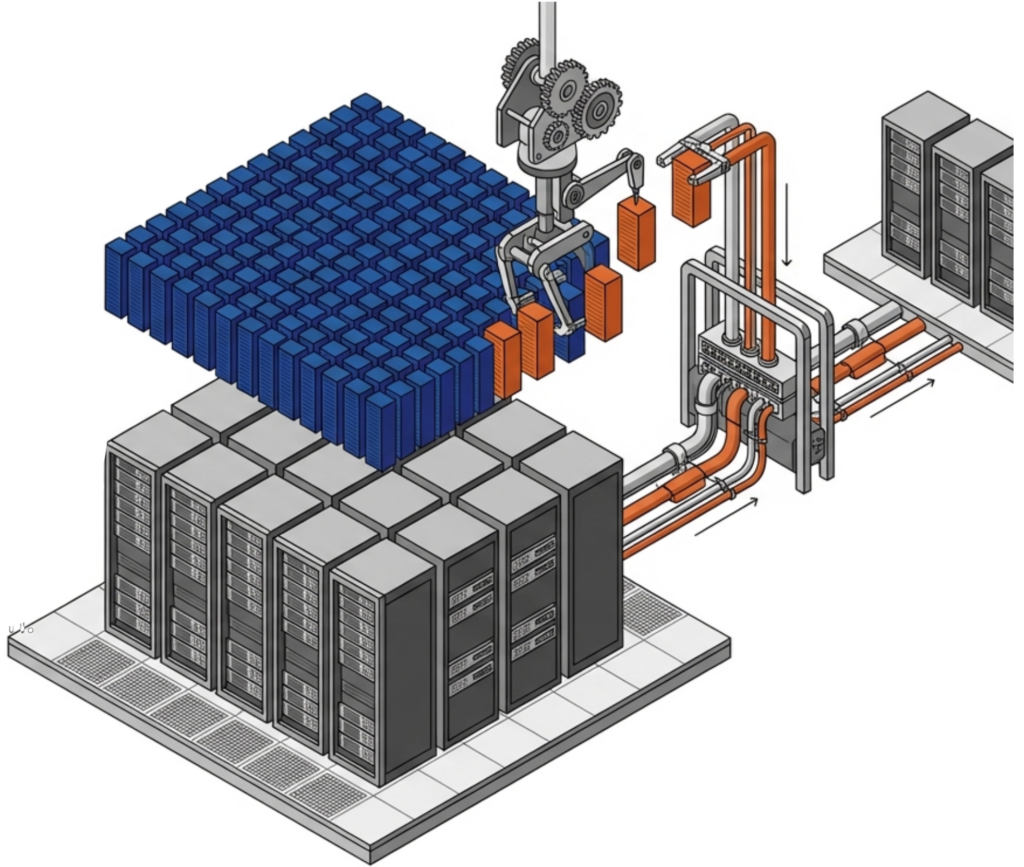
Version 26.1 also introduces granular replication, allowing IT planners to replicate specific workloads or data sets rather than replicating everything. This precision reduces bandwidth consumption on the WAN link and gives organizations finer control over which data gets the highest level of cross-site protection.
Density Without the Risk
VM density reduces hardware costs, shrinks the data center footprint, and frees budget for strategic initiatives. The risk is that traditional protection methods were designed for environments with fewer VMs per host and less data per server. As density increases, the blast radius of each failure grows.

VergeOS addresses this with a layered protection architecture that scales with density. ioOptimize keeps workloads balanced and migrates VMs off failing servers before they crash. RF2 handles single failures with no performance impact. ioGuardian extends protection to N+2 with a dedicated repair path that does not compete with production workloads. Integrated replication and virtual data centers add cross-site recovery that activates in minutes. Now with 26.1, RF3 combined with ioGuardian delivers N+X availability for environments where any downtime is unacceptable.
The result is an infrastructure that captures the full cost savings of VM density without accepting the availability risk that density traditionally creates.
Packing more VMs onto fewer hosts means each server failure takes more workloads offline at once. The surviving hosts absorb those displaced VMs on top of their existing workloads and any storage rebuild I/O, creating resource contention that can degrade performance across the entire cluster.
ioOptimize monitors every server for early signs of degradation and proactively migrates workloads before a hard failure occurs. When a server does fail, it evaluates the resource demands of each displaced VM and distributes them across surviving hosts based on actual CPU, memory, and I/O capacity rather than dumping them onto the nearest available server.
RF2 keeps two copies of every data block and provides N+1 protection, sustaining one device failure without data loss. RF3 keeps three copies and provides N+2 protection, sustaining two simultaneous failures. RF3 is new in VergeOS 26.1 and is designed for organizations that demand maximum availability.
ioGuardian maintains a protected copy of data on a separate VergeOS instance that does not host production workloads. During failures, it feeds missing data blocks back to the production environment in real time. Combined with RF2 it delivers N+2 protection. Combined with RF3 it delivers N+X availability, where data stays accessible as long as one production server and the repair server are running.
Yes. Integrated replication sends both production data and ioGuardian data to a remote site. If the primary site’s ioGuardian fails at the same time as a production failure, the ioGuardian at the DR site can still perform inline recovery to the primary production cluster over the WAN.
Virtual data centers encapsulate entire application stacks for failover at the remote site. The DR site does not need VM-by-VM configuration. Full workload environments restart in minutes, not hours.
According to SK Hynix internal analysis, commodity DRAM supply is projected to remain constrained through at least 2028. Multiple industry analysts expect high prices and tight supply to persist until new fabrication facilities reach volume production.
VergeOS’s single-codebase architecture reduces physical server count by up to 25% and per-VM memory allotment by 30%. Its ultraconverged design supports commodity NVMe drives and standard memory instead of vendor-specific components with inflated pricing. Fewer servers consuming less memory per VM means less hardware exposed to supercycle pricing.
New in VergeOS 26.1, granular replication lets IT planners replicate specific workloads or data sets to a remote site rather than replicating everything. This reduces WAN bandwidth consumption and gives organizations finer control over which data receives the highest level of cross-site protection.
Frequently Asked Questions
- Why does VM consolidation increase risk? — Packing more VMs onto fewer hosts means each server failure takes more workloads offline at once. The surviving hosts absorb those displaced VMs on top of their existing workloads and any storage rebuild I/O, creating resource contention that can degrade performance across the entire cluster.
- How does ioOptimize prevent failures from cascading? — ioOptimize monitors every server for early signs of degradation and proactively migrates workloads before a hard failure occurs. When a server does fail, it evaluates the resource demands of each displaced VM and distributes them across surviving hosts based on actual CPU, memory, and I/O capacity rather than dumping them onto the nearest available server.
- What is the difference between RF2 and RF3? — RF2 keeps two copies of every data block and provides N+1 protection, sustaining one device failure without data loss. RF3 keeps three copies and provides N+2 protection, sustaining two simultaneous failures. RF3 is new in VergeOS 26.1 and is designed for organizations that demand maximum availability.
- How does ioGuardian extend protection beyond RF2 or RF3? — ioGuardian maintains a protected copy of data on a separate VergeOS instance that does not host production workloads. During failures, it feeds missing data blocks back to the production environment in real time. Combined with RF2 it delivers N+2 protection. Combined with RF3 it delivers N+X availability, where data stays accessible as long as one production server and the repair server are running.
- Can ioGuardian work across sites? — Yes. Integrated replication sends both production data and ioGuardian data to a remote site. If the primary site’s ioGuardian fails at the same time as a production failure, the ioGuardian at the DR site can still perform inline recovery to the primary production cluster over the WAN.
- What happens if the primary site fails completely? — Virtual data centers encapsulate entire application stacks for failover at the remote site. The DR site does not need VM-by-VM configuration. Full workload environments restart in minutes, not hours.
- How long will RAM and flash prices stay elevated? — According to SK Hynix internal analysis, commodity DRAM supply is projected to remain constrained through at least 2028. Multiple industry analysts expect high prices and tight supply to persist until new fabrication facilities reach volume production.
- How does VergeOS reduce exposure to the memory supercycle? — VergeOS’s single-codebase architecture reduces physical server count by up to 25% and per-VM memory allotment by 30%. Its ultraconverged design supports commodity NVMe drives and standard memory instead of vendor-specific components with inflated pricing. Fewer servers consuming less memory per VM means less hardware exposed to supercycle pricing.
- What is granular replication? — New in VergeOS 26.1, granular replication lets IT planners replicate specific workloads or data sets to a remote site rather than replicating everything. This reduces WAN bandwidth consumption and gives organizations finer control over which data receives the highest level of cross-site protection.

