
Can an organization generate an ROI from disaster recovery? Most IT planners view the infrastructure and costs associated with disaster recovery (DR) as purely an expense item. It is a necessary expense to protect the organization in case of a major outage in its primary data center. But VergeIO, with the additional capabilities in VergeOS 26.1, can turn a DR expense into an investment that delivers a rapid return. The key is making the DR site work for the business every day, not just during a disaster.
Workload Portability: The Foundation of Disaster Recovery ROI
The foundational requirement for generating ROI from disaster recovery is seamless workload portability. Workloads have to restart in the other data center seamlessly, using only a few mouse clicks and as little post-movement configuration as possible. VergeOS accomplishes this with its multi-tenant Virtual Data Center (VDC) technology. These tenants encapsulate the entire data center, including all Virtual Machines and their specific settings, all network settings, and all storage settings. Customers can create VDCs by workload type, by line of business, or in the case of service providers, by customer.
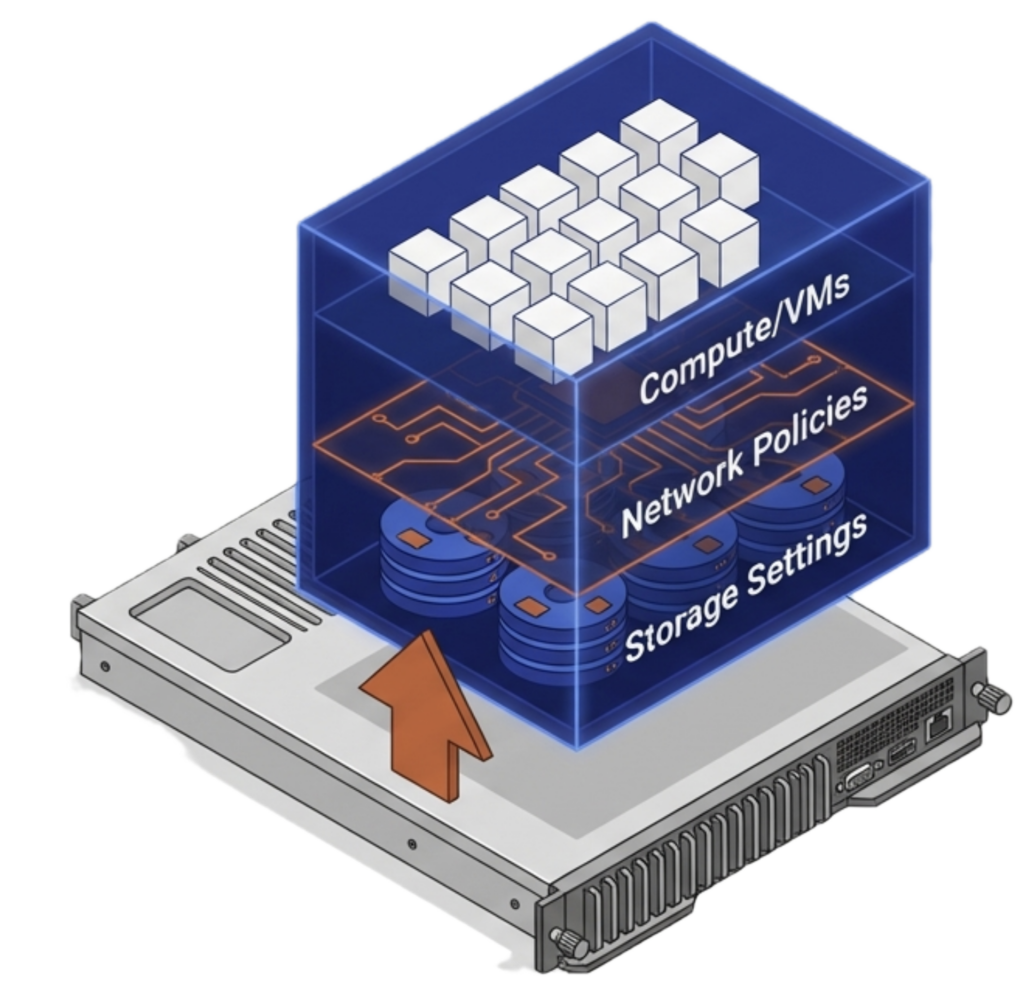
VDC-level encapsulation solves a problem that other DR approaches cannot. VM-centric replication misses network settings, storage configurations, and dependencies between interrelated VMs. It creates dozens of moving parts that an administrator must reassemble at the DR site before workloads can run. Data-center-wide replication goes to the other extreme. It forces everything to replicate together, offers no granularity, and makes it difficult to prioritize recovery of critical workloads over low-value ones.
VDCs hit the middle ground. They segment workloads into logical groups that match how the business actually operates. Each VDC acts as an automatic consistency group, capturing all the components a workload needs to run. No extra configuration. No extra cost. The result is a three-click restart at the DR site, with the workload running exactly as it did in production.
| Capability | VM-Centric DR | Data Center Wide DR | VergeOS VDC DR |
|---|---|---|---|
| Network settings | Manual reconfiguration | Might be included, but no granularity | Encapsulated per VDC |
| Storage settings | Manual reconfiguration | Might be included, but no granularity | Encapsulated per VDC |
| VM configurations | Replicated individually | Replicated as a whole | Grouped by workload, LOB, or customer |
| Interrelated VM dependencies | Missed or manually tracked | Included but cannot isolate | Automatic consistency groups |
| Recovery granularity | Per VM (many moving parts) | All or difficult per VM | Per VDC (right-sized groups) |
| Recovery prioritization | Manual triage at DR site | Difficult to prioritize | VDC-level priority sequencing |
| Post-failover configuration | Extensive | Minimal but inflexible | Three clicks, no reconfiguration |
Why DR Site Hardware Utilization Matters for Cost Savings
The second requirement for disaster recovery ROI is efficient hardware utilization at the DR site. Mirroring production hardware at a secondary location is expensive, and most organizations avoid that cost by running last-generation servers at their DR sites. The hardware is older, slower, and less capable than what runs in production.
This creates a problem for any organization that wants to use DR infrastructure for more than standby. If the DR site cannot run workloads at production-level performance, it cannot serve as a reliable testing environment or handle overflow during peak demand.

VergeOS addresses this through hardware abstraction. The platform decouples workloads from the underlying server hardware, allowing VMs to run on whatever physical resources are available. VergeOS uses that hardware efficiently, extracting maximum performance from every core, drive, and network link. The result is that workloads run as well at the DR site as they do in production, even on older equipment.
Two Ways to Generate ROI from Your DR Investment
With seamless portability and efficient hardware utilization in place, organizations can put their DR investment to work in two ways that generate measurable disaster recovery cost savings.
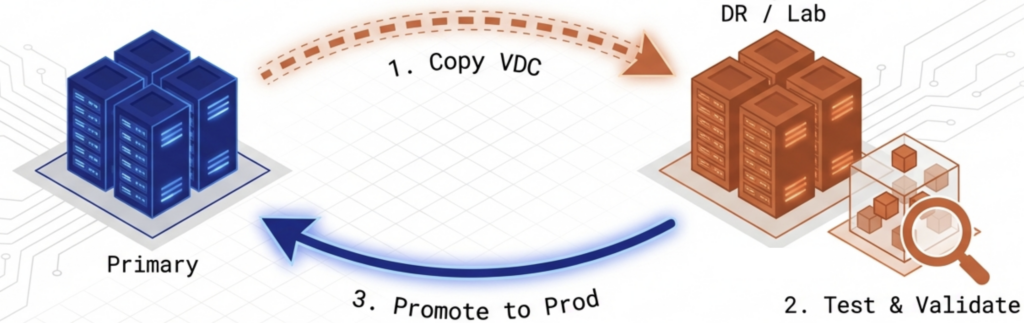
The first way to generate ROI from disaster recovery is to use the DR site becomes a testing environment. Instead of maintaining a dedicated lab or consuming production resources for QA, staging, and validation work, IT teams can run test workloads on the DR infrastructure. A VDC containing the test environment can be created at the DR site in 3 clicks. When testing is complete, the VDC stops, and the resources return to standby. The organization avoids the capital and operational costs of a separate test lab. If the test is successful, IT can move the validated VDC back to the primary site as a direct replacement for the production VDC. The DR site becomes a staging ground where updates are tested and promoted to production in a single workflow.
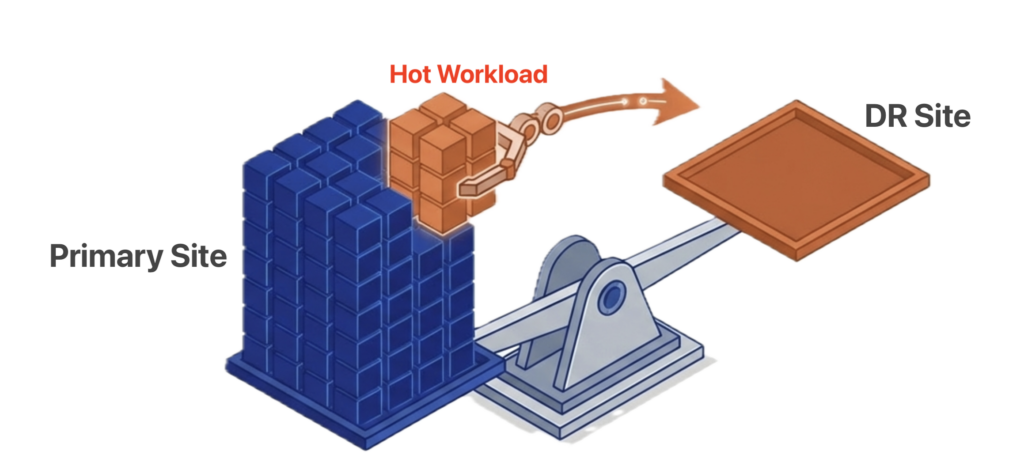
A second way to generate ROI from disaster recovery is to use it as a pressure valve for peak loads. When production demand spikes, administrators can move lower-priority workloads to the DR site, freeing resources for the applications that need them most. Or they can move the peak workload itself to the DR site, giving it dedicated access to the full hardware pool without competing for resources. Either approach turns idle DR capacity into active compute that supports the business during its most demanding periods. Speed and simplicity of transfer are critical here. If the process is too difficult, IT teams will not bother. If it cannot be executed within a few minutes, the peak demand may pass before the transfer is complete. VDC portability in VergeOS makes both the decision and the execution fast enough to act on in real time.
Both use cases generate direct, measurable returns:
- Lab infrastructure the organization no longer needs to buy or maintain
- Production performance that improves during peak periods without additional hardware purchases
- Tested updates that promote directly from DR to production without rebuilding
- Idle standby capacity that pays for itself through active daily use
How VergeOS Keeps Production Running Without Full-Site Failover
Another way to generate ROI from disaster recovery is to leverage it to offload some of the production site’s investment in data availability and protection. Traditional DR assumes a binary choice when a catastrophic failure hits the production site. The organization either fails over everything to the DR site or suffers downtime until the production environment is repaired. Full-site failover is disruptive, time-consuming, and in some cases takes longer than just fixing the primary site.
VergeOS offers a third option. When drive failures exceed the protection scope or multiple production servers fail, VergeOS can restart just the affected critical workloads at the DR site using VDC technology. There is no full-site failover. Unaffected workloads keep running in production. Only the impacted VDCs move.
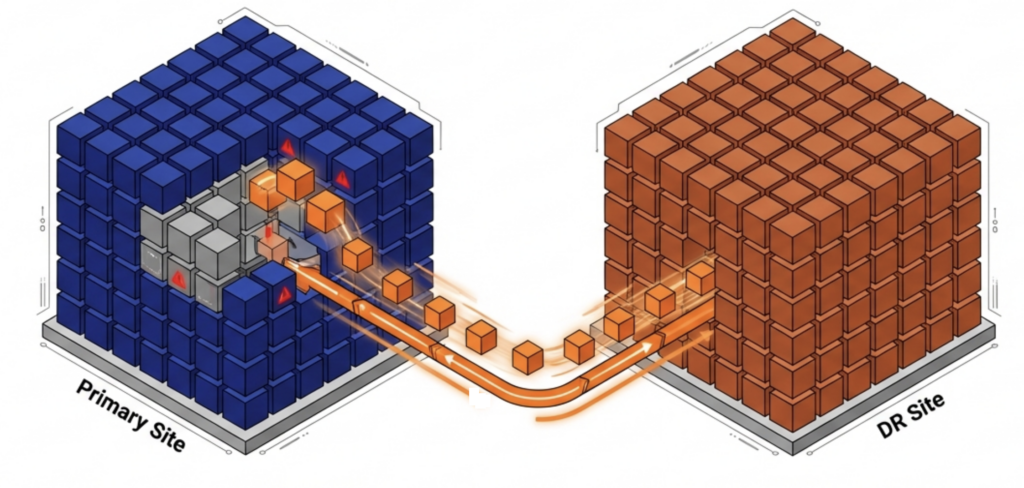
ioGuardian takes this further. When data segments are lost due to drive failures, ioGuardian feeds the missing blocks from the DR site back to production, one block at a time, in real time. The production environment rebuilds from the replica without taking workloads offline or initiating a formal DR event. The organization stays operational while the platform repairs itself in the background.
Active DR Sites Are More Recovery-Ready
DR readiness is one of the least-discussed benefits of generating ROI from disaster recovery by putting the secondary site into active use. Most organizations test their disaster recovery plans once or twice a year. Between tests, the DR environment sits idle. Configurations drift. Firmware falls behind. Network paths go unvalidated. When a real disaster hits, the DR site that passed its annual test six months ago may not perform the way the team expects.
An active DR site eliminates this risk. Every time IT moves a test workload to the DR site, runs a peak load scenario, or promotes a validated VDC back to production, the team is exercising the same processes and infrastructure that a real recovery event requires. Network connectivity between sites gets validated with every transfer. Storage replication gets confirmed with every sync. The team builds muscle memory on the exact workflows they would execute during a disaster.
This continuous validation replaces the artificial confidence of annual DR tests with operational proof. The DR site is not a cold standby that the team hopes will work. It is a working environment that the team knows will work because they used it yesterday.
VergeOS VDC portability enables this continuous readiness. Moving workloads between sites for testing or peak load management uses the same three-click process as a disaster recovery event. The tools are identical. The workflows are identical. The only difference is the trigger. Organizations that use their DR site daily do not need to wonder whether it will perform during a crisis. They already know.
Turn Disaster Recovery from an Expense into an Investment
DR Readiness is critical and using your DR Site for something other than a disaster actually improves your readiness. Disaster recovery does not have to be a pure cost center. Organizations that deploy VergeOS can use the same DR infrastructure for testing, peak load management, and targeted workload recovery. The foundational capabilities, VDC encapsulation, hardware abstraction, and ioGuardian, transform idle standby capacity into an active infrastructure that delivers value every day, not just during a disaster.
Yes. VergeOS VDC portability uses the same three-click process for daily workload transfers as it does for disaster recovery events. Every time you move a workload to the DR site for testing or peak load management, you are validating the same connectivity, replication, and recovery workflows that a real disaster would require.
VergeOS decouples workloads from the underlying hardware through abstraction. VMs run on whatever physical resources are available, and VergeOS extracts maximum performance from every core, drive, and network link. Organizations routinely run production-level workloads on last-generation DR hardware.
VM-centric replication copies individual virtual machines but misses network settings, storage configurations, and dependencies between interrelated VMs. VDCs encapsulate the entire workload environment, including all VMs, network, and storage settings, into a single portable unit that restarts at the DR site without reconfiguration.
No. VergeOS can restart just the affected VDCs at the DR site while unaffected workloads keep running in production. ioGuardian can also rebuild missing data blocks from the DR site back to production in real time, avoiding a formal DR event entirely.
Yes. IT teams can start a VDC at the DR site, validate updates in that environment, and then move the validated VDC back to the primary site as a direct replacement for the production VDC. The DR site becomes a staging ground where updates are tested and promoted in a single workflow.
VDC transfers execute in minutes through a three-click process. This speed is critical for peak load scenarios. If the transfer takes too long, the demand spike may pass before the move is complete. VergeOS makes both the decision and the execution fast enough to act on in real time.

