Storage challenges at distributed sites are inhibiting organizations that want to reduce reliance on the cloud and instead extend workloads into remote offices, retail sites, venues, and edge locations. Storage is the critical obstacle preventing these distributed sites from operating effectively.
IT was promised that all data could be centralized in the cloud, but the lack of independence and the high costs of storing and moving data make that approach impractical. What once lived in a data center or the cloud must now be delivered locally at dozens or hundreds of sites, each with tight limits on space, staff, and budget.

These environments show varied workload needs: some sites need high-capacity storage for video, others require high performance for real-time tasks, and some demand intensive AI processing. Many sites have a mix of these needs, often with limited IT staff, rack space, and budgets. Balancing cost, performance, capacity, and manageability is essential.
The stakes are high. Availability expectations for remote locations often exceed those for the data center. Many are more than customer-facing—they are customer-touching, directly impacting the customer experience. Protection from hardware failure is essential, as is rapid recovery at another site or the data center in case of disaster.
Balancing Storage Demands at the Site
One of the storage challenges at distributed sites is balancing the performance and capacity needs, which can vary greatly. Some require high-performance storage for real-time tasks like point-of-sale, video analytics, or sensors. Others need high-capacity storage for surveillance videos, medical images, or records. Some sites face both demands. Without proper balance, workloads either stall due to latency or run out of space before meeting retention needs.
IT teams are forced to choose between costly, oversized storage that wastes resources and basic local disks lacking resilience. Direct-attached drives offer decent performance but risk disruptions if a drive or server fails. Hyperconverged solutions reduce risk but are costly and may impact performance. None provides the ideal balance of resilience and affordability.
How VergeOS Helps: VergeOS addresses these challenges by collapsing storage, compute, and networking into a single code base, delivering both performance and capacity in the smallest possible footprint. IT teams can size hardware to each site’s exact needs while still getting enterprise-class data services like global deduplication, snapshots, and replication. This unified approach gives small sites the same capabilities as large ones, without oversized appliances or fragile local disks.
Download our white paper: “A Comprehensive Guide to a VMware Exit for Multi-Site Organizations.“
Remote Site Storage Protection and Recovery Gaps
If performance and capacity are difficult to balance at remote sites, protecting the data stored there is even harder. Skilled IT professionals can get these sites backed up, but it is expensive because of WAN bandwidth requirements and high software costs.
Local snapshot capabilities could fix these issues, but low-end storage appliances often lack such features or require costly upgrades. Direct-attached storage has no snapshot option. Hyperconverged storage offers limited snapshots, which can impact performance. Hardware failures mean restoring from outdated backups, risking data loss or downtime at remote sites.
The recovery challenge is just as severe. Moving large amounts of data back across limited WAN bandwidth can take days. Outages from fiber cuts or local disruptions always occur at the worst possible time—such as in the middle of a long backup job. When the connection is restored, the job must start over, wasting time and leaving data exposed.
Testing disaster recovery across dozens or hundreds of sites is time-consuming and often overlooked. In many cases, the first time recovery procedures are attempted is during a real-life failure—when the pressure is highest and tolerance for mistakes is lowest.
How VergeOS Helps: VergeOS solves these issues by making data protection a built-in function, not an add-on. Instant, immutable snapshots and WAN-efficient replication are integrated into the platform, ensuring consistent recovery options across all sites. Organizations no longer depend on fragile appliance snapshots or expensive backup software. By unifying storage and protection in one system, VergeOS makes recovery faster, more predictable, and resilient even across limited WAN connections.
Remote Storage Operational Fragmentation
Organizations manage diverse storage solutions, which become even more complex at distributed sites. The core data center uses SAN and NAS, while edge and remote offices typically rely on direct-attached storage, hypervisor-based storage, and backup appliances. Each layer has different tools, update cycles, and licensing models.
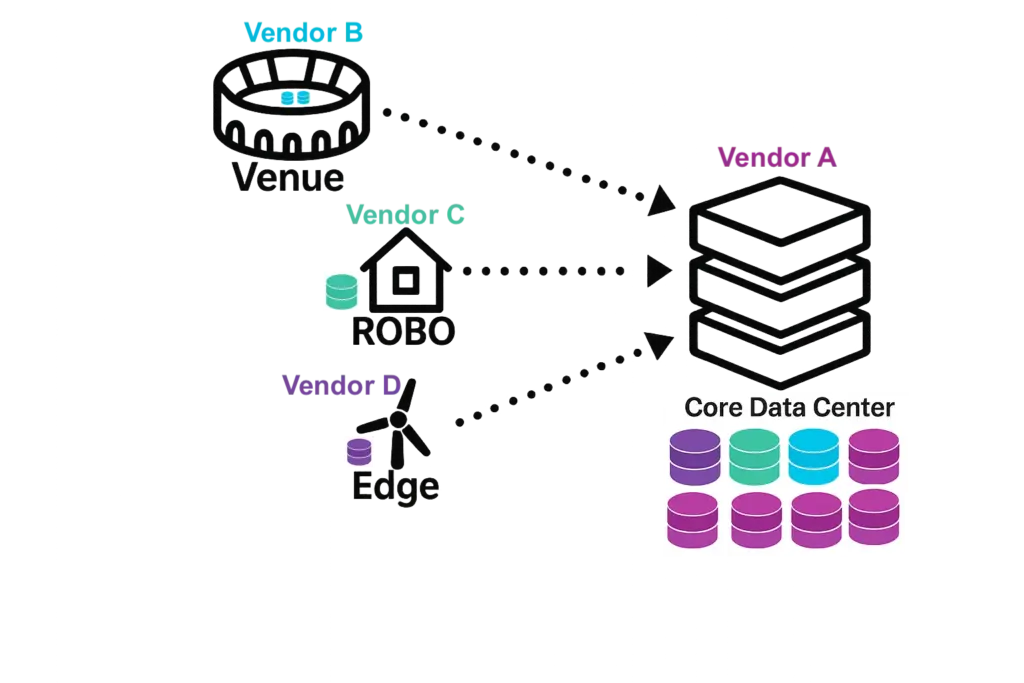
The result is operational fragmentation. IT staff must jump between consoles to monitor health, provision capacity, and validate protection. Policies differ by vendor, features behave inconsistently, and vendors update on different schedules. Without a single source of truth, it becomes challenging to determine which sites meet data protection requirements, have adequate recovery points, or are drifting out of alignment.
Another one of the top storage challenges at distributed sites is that storage features which appear similar, may work differently across platforms. Drive failure protection, replication, deduplication, encryption, and snapshots may all exist, but each behaves in its own way depending on the vendor, and they don’t understand each other. Vendor A can’t replicate to Vendor B, and Vendor C can’t leverage deduplication metadata from Vendor D. This inconsistency makes it nearly impossible to apply a single policy or rely on predictable results. These inconsistencies also exacerbate the IT skills gap.
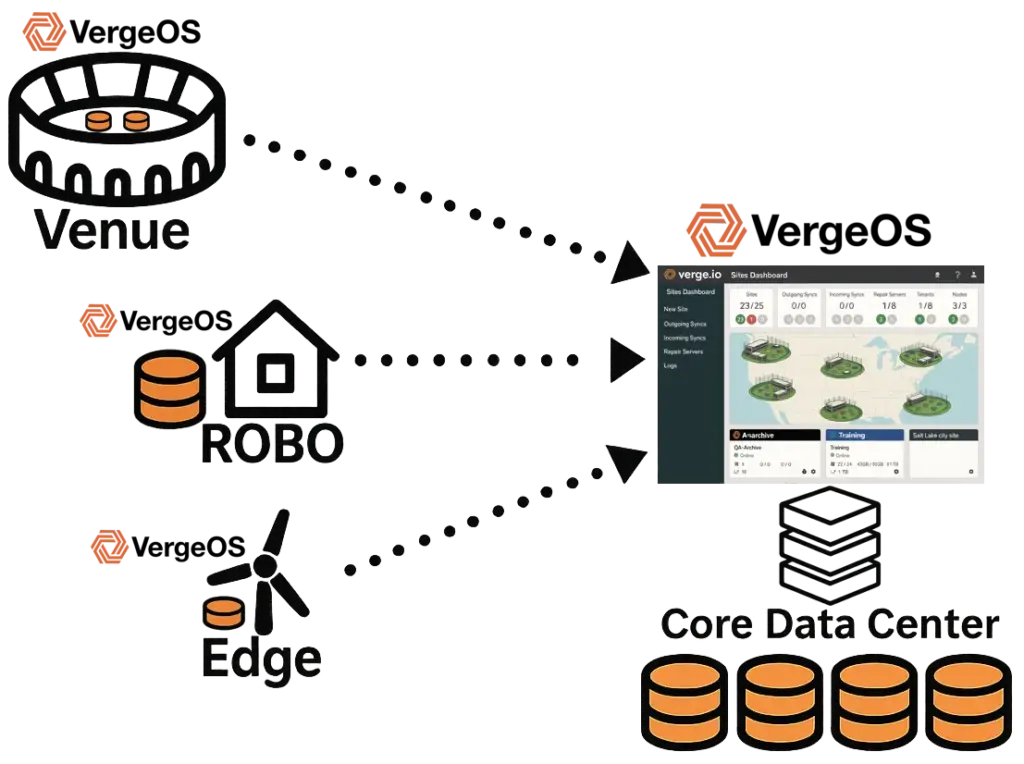
How VergeOS Helps: VergeOS replaces fragmented tools with a unified management plane and consistent features across every site. This eliminates silos and provides a single source of truth for monitoring, reporting, and compliance. It also eliminates inconsistency by applying global inline deduplication across the entire infrastructure—core, ROBO, edge, and venue locations. Deduplication is not siloed per vendor or appliance; identical blocks of data are recognized once, no matter where they originate. This reduces capacity requirements, improves replication efficiency across sites, and ensures all data management policies work consistently everywhere. Just as importantly, this same consistency extends to all features—snapshots, replication, encryption, and drive failure protection—so policies behave uniformly across every site.
The Path Forward: Unified Infrastructure Software
Solving the fragmentation issue requires more than incremental gains; the real challenge is architectural. Sites depend on diverse storage products, increasing complexity and risk. IT must unify infrastructure via a single software platform that offers storage, virtualization, and networking uniformly across multiple locations and supports diverse hardware.
A unified infrastructure platform eliminates storage challenges at distributed sites, such as the sprawl of consoles and feature sets. Replication, snapshots, deduplication, encryption, and drive failure protection all behave the same way whether they are deployed in the core data center, a regional office, or a small remote site. Policies can be defined once and applied everywhere, giving IT predictable outcomes.
This approach creates a single source of truth. Monitoring, reporting, and compliance data come from one system, giving IT visibility across the entire environment instead of forcing them to reconcile information from multiple consoles. With unified telemetry, trends are easier to spot, issues easier to diagnose, and compliance more straightforward to prove.
Operationally, benefits are immediate. IT teams spend less time managing incompatible tools and more on delivering value. Features work equally well at small and large sites—small sites get advanced capabilities without oversized appliances, and the core maintains resiliency without siloed complexity. Licensing and support are streamlined, avoiding duplication and waste from fragmentation.
Unified infrastructure software removes inconsistency, not choice. Teams can make per-site decisions on hardware, but standardizing the software layer across sites creates a resilient, easy-to-manage, scalable foundation. Architectural simplicity is essential for sustainable distributed infrastructure.
How VergeOS Helps: VergeOS delivers this architectural simplicity today via its ultraconverged infrastructure (UCI) design, which consolidates storage, virtualization, and networking into one tightly integrated code base. This ensures consistent features, policies, and management across every site—edge, ROBO, venue, and core—providing a unified foundation that scales without multiplying complexity.
Conclusion
Distributed sites are essential to modern operations, but traditional storage models were never built for environments with limited space, staff, and budgets. The result is a recurring cycle of over-provisioning, fragile local infrastructure, and operational silos that add cost and risk with every new site.
The solution to overcoming the storage challenges at distributed sites lies not in more point products but in a unified architectural approach. By consolidating storage, compute, networking, and data protection into one code base, VergeOS removes fragmentation and delivers consistent capabilities across every location. The result is simpler management, stronger resiliency, and predictable scalability.
Organizations that adopt this model can treat distributed sites as first-class citizens of the enterprise infrastructure—resilient, efficient, and prepared for the future.
Click here to learn more about VergeIO’s distributed sites solution.

