Licensing debates dominate the VMware Exit conversation, but the real issue is VMware’s protection problem. The platform was never designed to protect itself; it has always relied on third parties. While an ecosystem sounds good in theory, it also introduces complexity, increases exposure, and raises costs. IT professionals need to consider exiting VMware as more than just a hypervisor replacement. It presents a strategic opportunity to enhance core data protection, consolidate infrastructure software, repatriate cloud workloads, and lay the groundwork for AI.
From the start, VMware outsourced backup, replication, and disaster recovery to third-party vendors. Organizations filled the data protection gap by layering products on top of the hypervisor. Each solved part of the problem. None provided a complete solution. The ecosystem approach to data resilience, protection, and disaster recovery creates another siloed infrastructure that adds roughly 40 percent to the cost of the production environment. It was a clever way to hide the protection fragmentation problem behind a “feature.”

The operational burden of VMware’s protection problem matches the financial one. One team manages backup schedules. Another maintains replication appliances. A third builds disaster recovery runbooks and runs annual failover tests. When a failure occurs, recovery becomes an exercise in assembling pieces that rarely align under pressure.
By comparison, VergeOS takes the opposite approach—embedding protection directly into the same operating environment that runs workloads. It eliminates the external layers that make recovery slow, expensive, and unreliable.
Protection Fragmentation Is Expensive
Protection fragmentation separates data, configuration, and metadata across different systems. Backup applications capture virtual machine disks. Replication tools copy them to another site. DR orchestration attempts to restart them with the correct IP addresses and network mappings. Each layer introduces lag, overhead, and risk.
Recovery times stretch into hours because these systems were never designed to work together. During an absolute failure, IT teams discover that the backup copy is missing network configurations. The replicated image is hours out of date. The DR runbook references infrastructure that no longer exists. What appeared to be protection on paper becomes reconstruction under pressure.
The cost is not just financial. It is also operational. One team manages backup windows. Another handles replication schedules. A third party tests DR failover once or twice a year, hoping that the test environment closely enough mirrors production to be effective. Coordination replaces automation. Manual validation replaces confidence.
Addressing Protection Fragmentation with the VMware Exit
A transition away from VMware touches every workload, every storage volume, and every network segment. It forces a complete inventory of what runs, where it runs, and how it connects. That same process creates an opportunity to eliminate the protection tax entirely.
The alternative is not just another backup product or replication tool. It is an architecture that integrates protection directly into the production environment. Instead of copying data out to separate systems, the modern infrastructure maintains continuous, deduplicated snapshots within the same layer that runs workloads. Recovery becomes a restart, not a rebuild.
Taking an infrastructure-wide approach to the exit eliminates the VMware protection problem, rather than recreating it. Gone are backup servers, replication appliances, and the storage arrays that support them. It removes the operational overhead of aligning schedules, policies, and retention across disconnected tools. Protection becomes automatic, continuous, and inherently consistent with the production state.
The financial impact is immediate. Removing 30 to 40 percent of infrastructure spend while improving recovery time and reliability is not incremental savings. It redefines the cost model.
Resilience Should Be Built In, Not Bolted On
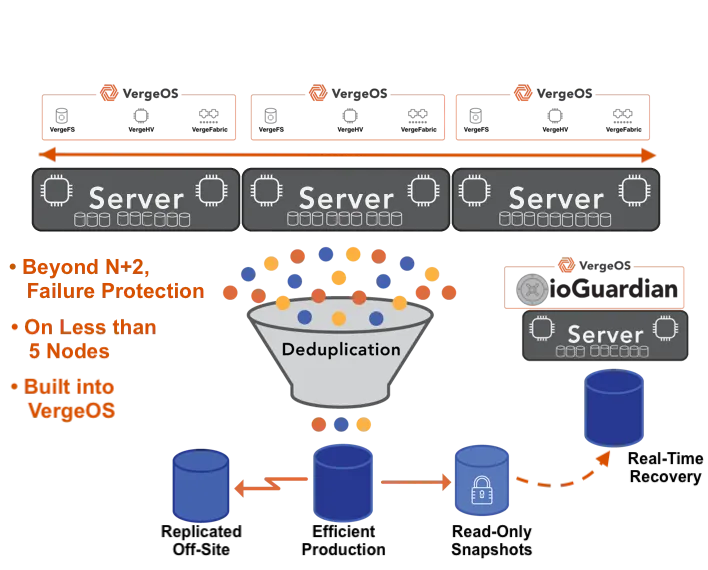
VergeOS does not separate production from protection. It treats availability, recovery, and performance as interconnected components of a unified system, enabling the creation of an advanced data resilience strategy. Every write is captured, deduplicated, and mirrored. Snapshots are independent, instant, and retained for months without impacting capacity. Replication encompasses not only data but also the configuration and metadata required for seamless failover.
Disaster recovery stops being a separate plan and becomes a continuous operational state. Sites maintain synchronized copies of complete virtual data centers that can be activated elsewhere in minutes. Testing happens during production hours without risk. Failover and failback are automated, predictable, and repeatable. VergeOS unifies these layers through VergeFS’s ioClone snapshot technology for data protection, ioGuardian for hardware resilience, and ioReplicate with virtual data centers for site continuity.
This isn’t theory. It’s how infrastructure should work in a post-VMware world. The hypervisor transition is the perfect opportunity to eliminate the protection fragmentation that VMware created.
Eliminating Protection Fragmentation Delivers Confidence
The VMware Exit begins with a choice. Organizations can replicate the same fragmented protection model on new infrastructure, or they can rebuild resilience the right way. The first option preserves the VMware protection problem. The second eliminates it.
Integrated resilience delivers faster, works-the-first-time recovery, lowers cost, and simplifies operations. It removes the protection tax caused by protection fragmentation and replaces it with a foundation that supports broader modernization. Infrastructure consolidation becomes practical. VDI performance improves. Cloud repatriation makes financial sense. Private AI can run securely next to production data.
The first VMware payoff isn’t cheaper licensing—it’s confidence, achieved by eliminating protection fragmentation. Confidence that data will always be available, recoverable, and protected by the infrastructure itself. That foundation enables everything that follows: consolidation, VDI modernization, cloud repatriation, and Private AI.
Ready to rethink how protection works in a post-VMware environment?
Register for our live virtual chalktalk session, Beyond the Hypervisor Swap, on October 9th at 1:00 PM ET / 10:00 AM PT, to explore how integrated resilience eliminates backup complexity, reduces infrastructure costs by 30–40%, and delivers recovery times measured in minutes instead of hours.


