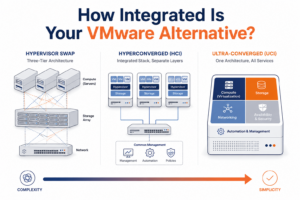
What comes after the VMware exit matters more than what you leave behind. Don’t replace VMware with Nutanix, or Hyper-V, or the hypervisor du jour, and declare the problem solved. That approach misses the real opportunity. The VMware exit served as the compelling event that enterprises needed to finally consolidate years of tactical decisions, which had built silos across the data center, edge, and cloud, leaving them ill-prepared for future workloads.
Most enterprises already run multiple hypervisors. VMware sits at the core, but Hyper-V handles Windows-centric applications. Nutanix crept in through departmental projects. Edge sites run different stacks. Cloud platforms host workloads that were meant to be temporary but never came back. Swapping VMware for another hypervisor leaves this mess intact.

The right move is to use this disruption to drive complete consolidation. One operating model must span the data center, edge, ROBO, and venues. One platform must handle virtual machines, containers, AI workloads, backup, and disaster recovery. Anything less retains the same fragmented complexity, albeit under a different label.
The path forward is clear. Enterprises must modernize on-premises infrastructure to consolidate silos, pull back workloads that never belonged in the cloud, and build a platform ready to run AI alongside every other workload. Anything less leaves IT repeating the same cycle of sprawl under new names.
After The VMware Exit, Modernize Infrastructure

After the VMware exit the goal should be complete consolidation of the infrastructure. Consolidation starts with modernization, but not the kind most vendors sell. Too often, “modernization” is a rebrand of the same fragmentation—another hypervisor, another storage system, another management console. Real modernization means collapsing silos into a single operating model, extending the useful life of hardware, and giving IT the agility to run any workload on a standard foundation.
Modernization done right reduces the number of moving parts, stretches servers and storage to five or seven years instead of three or four, and creates a single system capable of supporting virtual machines, containers, and AI workloads without building separate stacks. The VMware exit is the moment to stop layering tactical fixes and start building a strategic, consolidated platform that lasts.
After The VMware Exit, Repatriate the Cloud
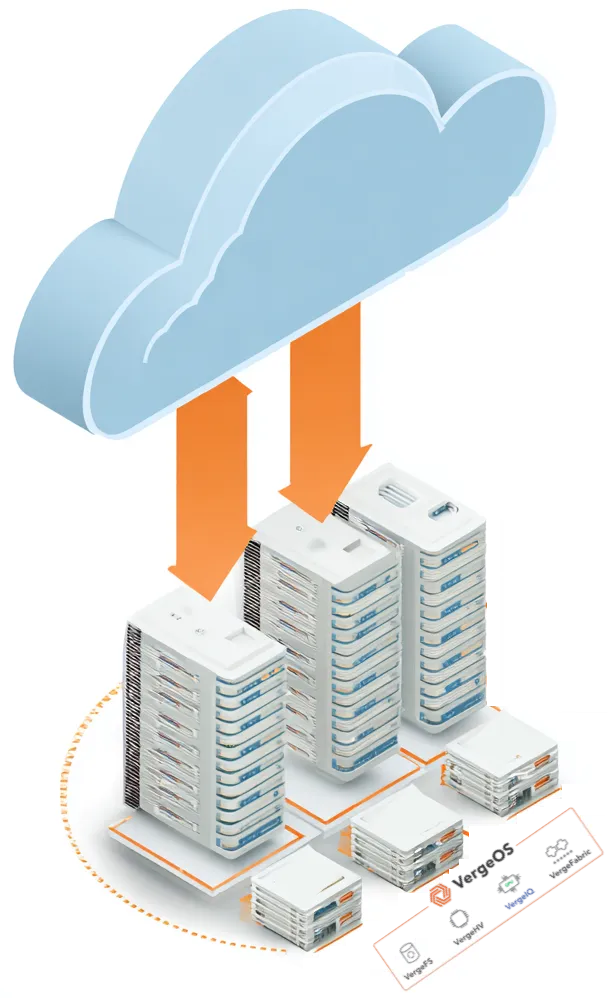
Another step after the VMware exit is cloud repatriation, which involves consolidating on-premises resources and pulling back workloads that should never have been moved to the cloud in the first place. The public cloud provided quick relief when IT needed capacity fast, but many of those temporary moves became permanent. Enterprises now pay unpredictable monthly bills for capacity they could run more consistently and economically on infrastructure they already own.
Those costs rise every quarter, driven by storage growth, variable I/O performance, and punitive egress charges. The fix is repatriation. Pull back the steady-state workloads—databases, file services, ERP systems, and VDI—that run better under direct control. Keep the cloud for temporal workloads where its economics make sense. Renting a car for a trip is practical. Renting one every day for your daily commute is reckless. The same logic should be applied to cloud consumption.
AI makes the case even stronger. Training and inference create data gravity that punishes cloud economics. Large and growing datasets need to sit close to the GPU and compute resources. Moving them back and forth only adds cost and latency. Repatriation is not just about saving money. It is about putting the right workloads in the right place and preparing the enterprise for AI.
After The VMware Exit, Prepare for Private AI
Another step after the VMware exit is preparing infrastructure to run AI as a core function, not as an afterthought. AI is no longer experimental, and it cannot be treated as a side project or pushed into the cloud as a service. The datasets that feed AI are the most valuable assets enterprises own. Sending them to a public cloud raises sovereignty concerns, exposes sensitive data, and locks the enterprise into consumption models that only grow more expensive.

Cloud-based AI also adds token costs that accumulate with every transaction. What begins as a pilot quickly becomes an unpredictable monthly bill. Treating AI this way repeats the same mistakes that left steady-state workloads stranded in the cloud.
The right move is to make AI a first-class citizen in the same operating system that runs virtual machines, databases, and desktops. GPU pooling, high-throughput storage, and predictable networking must be built into the core platform, not added later as separate stacks. Vendors eager to sell AI-only servers and storage will lead enterprises straight into another silo. Building AI into the unified infrastructure from the start prevents this and keeps the estate ready for tomorrow’s demands.
What’s Required for Complete Consolidation
Modernizing on-premises, repatriating the right workloads, and preparing for AI all point to the same conclusion: consolidation only works if the foundation is built right. Enterprises can’t afford to solve one problem only to create another. To break the cycle of sprawl, two non-negotiable capabilities are required. Miss either, and the silos return under a new set of logos.
The first requirement is a universal infrastructure operating system. It must integrate virtualization, storage, networking, GPUs, backup, and disaster recovery into a single code base. One policy model must stretch from the data center to the edge, ROBO, and venues. The operating system must run on a wide range of x86 servers so organizations can reuse hardware during transitions and extend refresh cycles to five or seven years instead of three. Licensing must be per server, not per core or per socket. The platform must treat AI as a core workload with GPU pooling, high-throughput storage, and predictable networking built into the design.
The second requirement is a universal migration path. The path must cover VMware, Hyper-V, Nutanix, OpenStack, and workloads sitting in a public cloud. It must synchronize data while production continues to run and cut over in minutes. It must scale through automation, with migration-as-code recipes that standardize each step and log every action for audit. Without this path, consolidation remains an idea on paper, not a result in production.
To learn more about complete consolidation, register for our live webinar, “After the VMware Exit—How to Consolidate, Repatriate, and Prepare for AI”
The Requirement: Universal Path + Destination
Consolidation only succeeds when both requirements are met: the path to move workloads and the destination where they land. One without the other leaves IT stuck with the same problems under different branding.
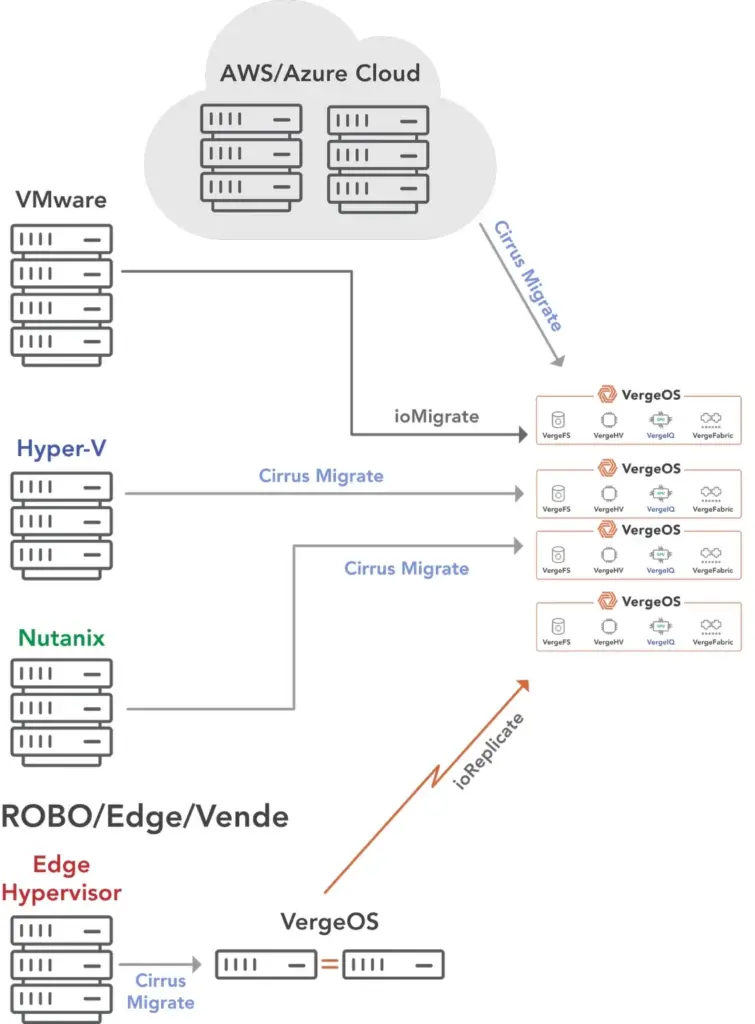
Cirrus Data provides the path. Its block-level migration runs while production stays online. Intelligent QoS manages I/O so applications remain responsive during synchronization. Cutovers take minutes, not hours, making migrations fit inside standard change windows. With MigrateOps, migrations become recipes—repeatable, auditable, and consistent across hundreds of workloads. Migration risk, once the barrier to change, is removed.
VergeOS provides the destination. It is a single operating system that unifies virtualization, storage, networking, GPU sharing, backup, and disaster recovery. VergeOS runs on standard x86 servers and uses per-server licensing, so enterprises can extend hardware life and deploy large hosts without penalty. Most importantly, VergeOS treats AI as a core workload. GPU pooling, high-throughput storage, and predictable networking are built in, preventing the creation of yet another silo.
Together, Cirrus Data and VergeOS address both sides of the consolidation equation. Cirrus Data clears the way out of sprawl. VergeOS delivers a consistent operating model across the data center, edge, ROBO, and venues. Unlike other platforms that claim unification, VergeOS is built on a single code base—a distinction that makes a difference when stability and scale matter.
Why a Single Code Base Matters
Not every platform that calls itself “unified” deserves the label. Most competitors stitch together a collection of modules written by separate development teams, often acquired through M&A, and then shoehorn them into a common management GUI. The interface hides the seams but does not remove them. Each module carries its own dependencies, update cycles, and failure modes. When workloads push the system, those seams show up in outages, support escalations, and stalled upgrades.
A true universal infrastructure operating system is different. Built on a single code base, VergeOS delivers compute, storage, networking, GPU support, backup, and disaster recovery through the same logic and policy framework. Features work together because they were designed together. One update applies across the platform. One roadmap drives progress. One support model resolves issues without finger-pointing.
The difference matters. Layered modules behind a GUI add fragility that IT pays for later. A single code base gives enterprises confidence that every workload—traditional applications, cloud-repatriated systems, and private AI—runs on the same consistent foundation. Anything less is not consolidation. It is simply sprawl wearing a new logo.
Conclusion
The VMware exit is not just a licensing shift. It is the compelling event that enterprises need, to confront the cost and complexity created by years of tactical decisions. Treating it as a hypervisor swap misses the point. Replacing VMware with another logo keeps the same fragmentation in place and leaves the enterprise just as unprepared for AI, cloud repatriation, and future workloads.
The right move after the VMware exit is complete consolidation. That requires both a universal migration path and a universal infrastructure operating system. Cirrus Data provides the path, with live block-level migration, automation through MigrateOps, and cutovers measured in minutes. VergeOS provides the destination, with a single code base that unifies compute, storage, networking, GPU sharing, backup, and disaster recovery. Together, they address the two most critical questions following the VMware exit: how to escape sprawl and where to land once you do.
This is not the time to patch or postpone. Enterprises that seize the moment can consolidate once, extend hardware life, and prepare their infrastructure for AI without creating new silos. Enterprises that miss it will be back in the same place in three years—only weaker and even less ready. The choice is clear: consolidate now with Cirrus Data and VergeOS, or carry the weight of sprawl into the future.